 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization Gap in Self-Evolving Language Model Reasoning
May 31, 2026Recent work suggests that large language models (LLMs) can improve through self-evolution (SE), using supervision signals generated by the model itself. In this work, we ask: under a strict closed-loop setup, where the self-evolution algorithm has access only to an unlabeled prompt set and a base model, how close can internally generated supervision come to oracle-supervised training? We analyze four representative strategies in a unified offline self-evolution framework: single-round verification, multi-turn revision with feedback, iterative training, and curriculum learning. Our primary experiments use Knights and Knaves (KK) logical reasoning tasks, which provide deterministic solutions, controlled difficulty levels, and a clean testbed for easy-to-hard generalization. We first show that self-evolution consistently improves over the base model, but plateaus after excessive training compute is invested, and eventually still leaves a non-trivial gap to oracle supervision. We find that multi-turn critic-revision with large models can reach strong self-evolution performance, with Gemma 12B nearly matching oracle-supervised training. Beyond Knights and Knaves, we also evaluate self-evolution on real-world reasoning benchmarks, where gains are also modest. Overall, our results characterize when closed-loop self-evolution can help and show how internally generated supervision remains insufficient under this minimal formulation.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
Think or Remember? Detecting and Directing LLMs Towards Memorization or Generalization
Dec 24, 2024


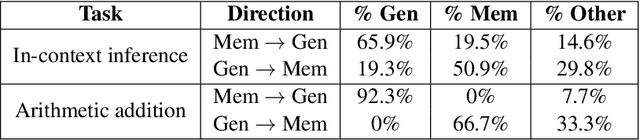
In this paper, we explore the foundational mechanisms of memorization and generalization in Large Language Models (LLMs), inspired by the functional specialization observed in the human brain. Our investigation serves as a case study leveraging specially designed datasets and experimental-scale LLMs to lay the groundwork for understanding these behaviors. Specifically, we aim to first enable LLMs to exhibit both memorization and generalization by training with the designed dataset, then (a) examine whether LLMs exhibit neuron-level spatial differentiation for memorization and generalization, (b) predict these behaviors using model internal representations, and (c) steer the behaviors through inference-time interventions. Our findings reveal that neuron-wise differentiation of memorization and generalization is observable in LLMs, and targeted interventions can successfully direct their behavior.
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
Nov 09, 2024



Augmenting LLMs with context leads to improved performance across many applications. Despite much research on Retrieval Augmented Generation (RAG) systems, an open question is whether errors arise because LLMs fail to utilize the context from retrieval or the context itself is insufficient to answer the query. To shed light on this, we develop a new notion of sufficient context, along with a way to classify instances that have enough information to answer the query. We then use sufficient context to analyze several models and datasets. By stratifying errors based on context sufficiency, we find that proprietary LLMs (Gemini, GPT, Claude) excel at answering queries when the context is sufficient, but often output incorrect answers instead of abstaining when the context is not. On the other hand, open-source LLMs (Llama, Mistral, Gemma) hallucinate or abstain often, even with sufficient context. We further categorize cases when the context is useful, and improves accuracy, even though it does not fully answer the query and the model errs without the context. Building on our findings, we explore ways to reduce hallucinations in RAG systems, including a new selective generation method that leverages sufficient context information for guided abstention. Our method improves the fraction of correct answers among times where the model responds by 2-10% for Gemini, GPT, and Gemma.
SLED: Self Logits Evolution Decoding for Improving Factuality in Large Language Models
Nov 01, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their outputs can sometimes be unreliable or factually incorrect. To address this, we introduce Self Logits Evolution Decoding (SLED), a novel decoding framework that enhances the truthfulness of LLMs without relying on external knowledge bases or requiring further fine-tuning. From an optimization perspective, our SLED framework leverages the latent knowledge embedded within the LLM by contrasting the output logits from the final layer with those from early layers. It then utilizes an approximate gradient approach to enable latent knowledge to guide the self-refinement of outputs, thereby effectively improving factual accuracy. Extensive experiments have been conducted on established benchmarks across a diverse range of model families (LLaMA 2, LLaMA 3, Gemma) and scales (from 2B to 70B), including more advanced architectural configurations such as the mixture of experts (MoE). Our evaluation spans a wide variety of tasks, including multi-choice, open-generation, and adaptations to chain-of-thought reasoning tasks. The results demonstrate that SLED consistently improves factual accuracy by up to 20\% compared to existing decoding methods while maintaining natural language fluency and negligible latency overhead. Furthermore, it can be flexibly combined with other decoding methods to further enhance their performance.
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
Attributed Text Generation via Post-hoc Research and Revision
Oct 17, 2022
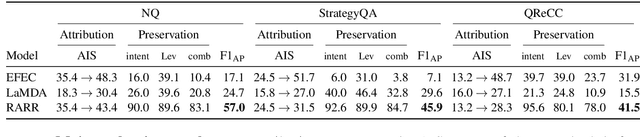
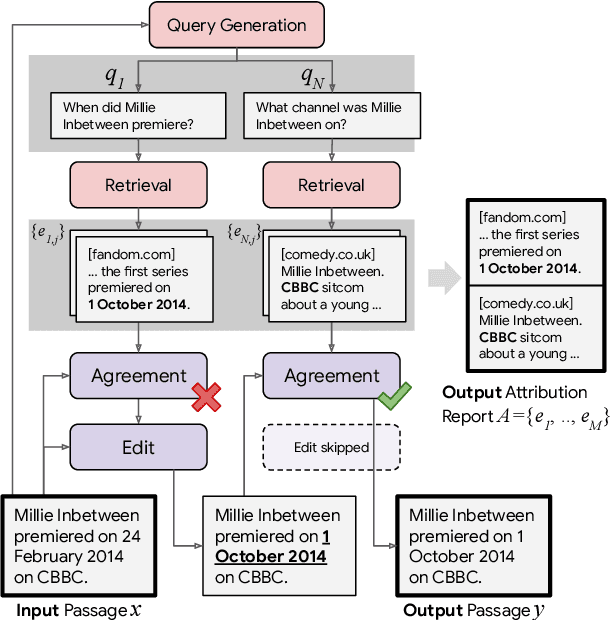
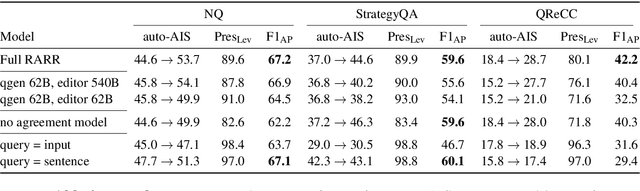
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.
Representative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022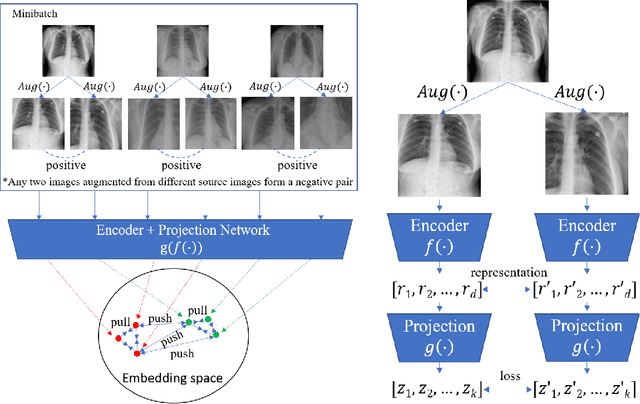
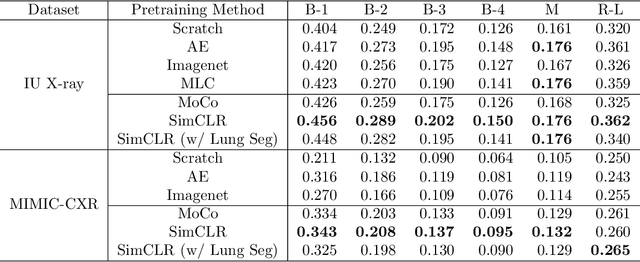

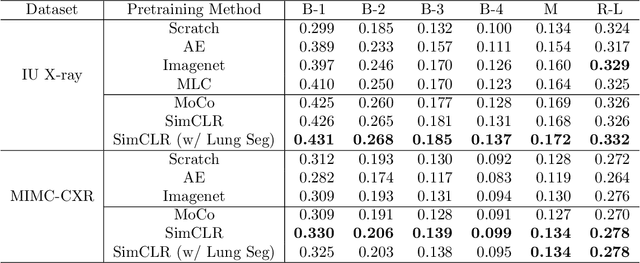
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.