 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJESTR: Joint Embedding Space Technique for Ranking Candidate Molecules for the Annotation of Untargeted Metabolomics Data
Nov 25, 2024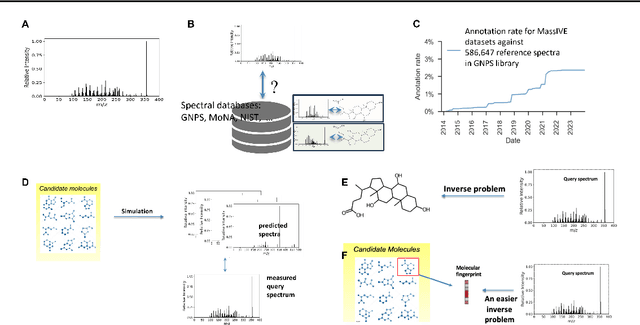

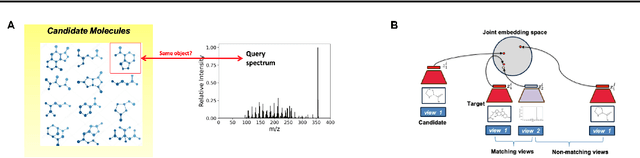
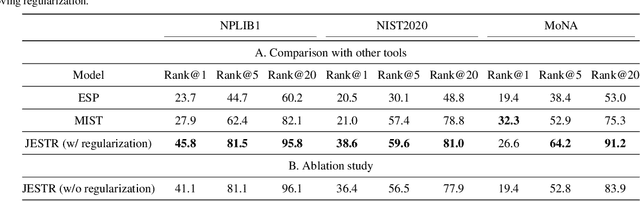
Motivation: A major challenge in metabolomics is annotation: assigning molecular structures to mass spectral fragmentation patterns. Despite recent advances in molecule-to-spectra and in spectra-to-molecular fingerprint prediction (FP), annotation rates remain low. Results: We introduce in this paper a novel paradigm (JESTR) for annotation. Unlike prior approaches that explicitly construct molecular fingerprints or spectra, JESTR leverages the insight that molecules and their corresponding spectra are views of the same data and effectively embeds their representations in a joint space. Candidate structures are ranked based on cosine similarity between the embeddings of query spectrum and each candidate. We evaluate JESTR against mol-to-spec and spec-to-FP annotation tools on three datasets. On average, for rank@[1-5], JESTR outperforms other tools by 23.6%-71.6%. We further demonstrate the strong value of regularization with candidate molecules during training, boosting rank@1 performance by 11.4% and enhancing the model's ability to discern between target and candidate molecules. Through JESTR, we offer a novel promising avenue towards accurate annotation, therefore unlocking valuable insights into the metabolome.
Learning Vision from Models Rivals Learning Vision from Data
Dec 28, 2023



We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.
Scaling Laws of Synthetic Images for Model Training for Now
Dec 07, 2023



Recent significant advances in text-to-image models unlock the possibility of training vision systems using synthetic images, potentially overcoming the difficulty of collecting curated data at scale. It is unclear, however, how these models behave at scale, as more synthetic data is added to the training set. In this paper we study the scaling laws of synthetic images generated by state of the art text-to-image models, for the training of supervised models: image classifiers with label supervision, and CLIP with language supervision. We identify several factors, including text prompts, classifier-free guidance scale, and types of text-to-image models, that significantly affect scaling behavior. After tuning these factors, we observe that synthetic images demonstrate a scaling trend similar to, but slightly less effective than, real images in CLIP training, while they significantly underperform in scaling when training supervised image classifiers. Our analysis indicates that the main reason for this underperformance is the inability of off-the-shelf text-to-image models to generate certain concepts, a limitation that significantly impairs the training of image classifiers. Our findings also suggest that scaling synthetic data can be particularly effective in scenarios such as: (1) when there is a limited supply of real images for a supervised problem (e.g., fewer than 0.5 million images in ImageNet), (2) when the evaluation dataset diverges significantly from the training data, indicating the out-of-distribution scenario, or (3) when synthetic data is used in conjunction with real images, as demonstrated in the training of CLIP models.
Improve Supervised Representation Learning with Masked Image Modeling
Dec 01, 2023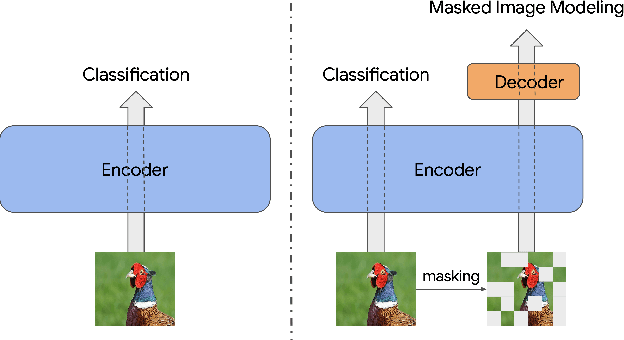
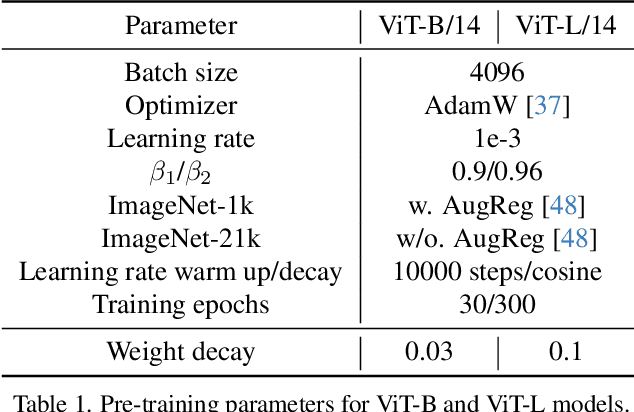
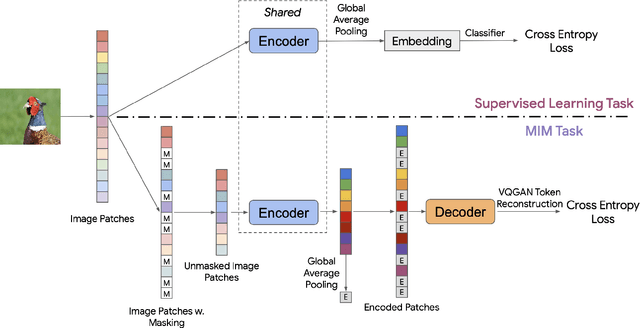
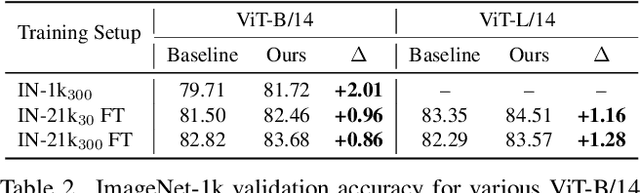
Training visual embeddings with labeled data supervision has been the de facto setup for representation learning in computer vision. Inspired by recent success of adopting masked image modeling (MIM) in self-supervised representation learning, we propose a simple yet effective setup that can easily integrate MIM into existing supervised training paradigms. In our design, in addition to the original classification task applied to a vision transformer image encoder, we add a shallow transformer-based decoder on top of the encoder and introduce an MIM task which tries to reconstruct image tokens based on masked image inputs. We show with minimal change in architecture and no overhead in inference that this setup is able to improve the quality of the learned representations for downstream tasks such as classification, image retrieval, and semantic segmentation. We conduct a comprehensive study and evaluation of our setup on public benchmarks. On ImageNet-1k, our ViT-B/14 model achieves 81.72% validation accuracy, 2.01% higher than the baseline model. On K-Nearest-Neighbor image retrieval evaluation with ImageNet-1k, the same model outperforms the baseline by 1.32%. We also show that this setup can be easily scaled to larger models and datasets. Code and checkpoints will be released.
Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency
Oct 05, 2023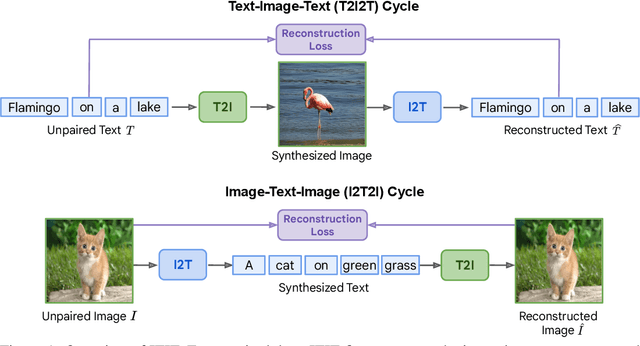
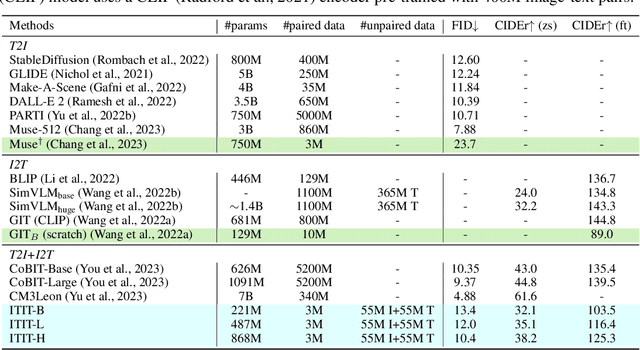
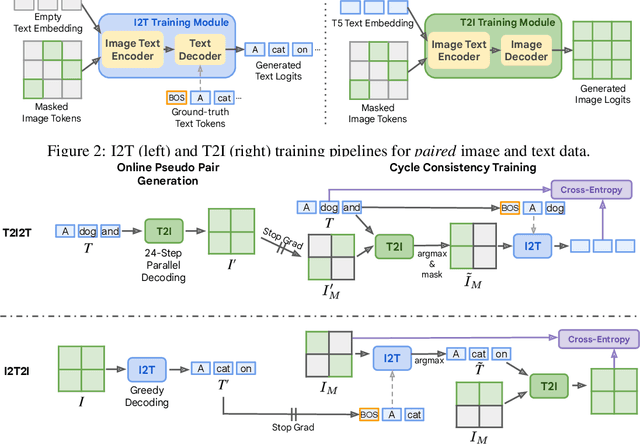
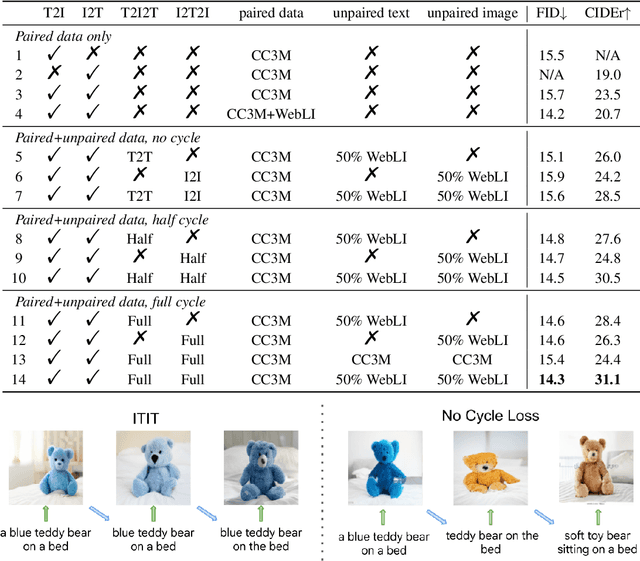
Current vision-language generative models rely on expansive corpora of paired image-text data to attain optimal performance and generalization capabilities. However, automatically collecting such data (e.g. via large-scale web scraping) leads to low quality and poor image-text correlation, while human annotation is more accurate but requires significant manual effort and expense. We introduce $\textbf{ITIT}$ ($\textbf{I}$n$\textbf{T}$egrating $\textbf{I}$mage $\textbf{T}$ext): an innovative training paradigm grounded in the concept of cycle consistency which allows vision-language training on unpaired image and text data. ITIT is comprised of a joint image-text encoder with disjoint image and text decoders that enable bidirectional image-to-text and text-to-image generation in a single framework. During training, ITIT leverages a small set of paired image-text data to ensure its output matches the input reasonably well in both directions. Simultaneously, the model is also trained on much larger datasets containing only images or texts. This is achieved by enforcing cycle consistency between the original unpaired samples and the cycle-generated counterparts. For instance, it generates a caption for a given input image and then uses the caption to create an output image, and enforces similarity between the input and output images. Our experiments show that ITIT with unpaired datasets exhibits similar scaling behavior as using high-quality paired data. We demonstrate image generation and captioning performance on par with state-of-the-art text-to-image and image-to-text models with orders of magnitude fewer (only 3M) paired image-text data.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
Jun 01, 2023We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of such models in generating high-quality images. We consider specifically the Stable Diffusion, one of the leading open source text-to-image models. We show that (1) when the generative model is configured with proper classifier-free guidance scale, training self-supervised methods on synthetic images can match or beat the real image counterpart; (2) by treating the multiple images generated from the same text prompt as positives for each other, we develop a multi-positive contrastive learning method, which we call StableRep. With solely synthetic images, the representations learned by StableRep surpass the performance of representations learned by SimCLR and CLIP using the same set of text prompts and corresponding real images, on large scale datasets. When we further add language supervision, StableRep trained with 20M synthetic images achieves better accuracy than CLIP trained with 50M real images.
StyleDrop: Text-to-Image Generation in Any Style
Jun 01, 2023
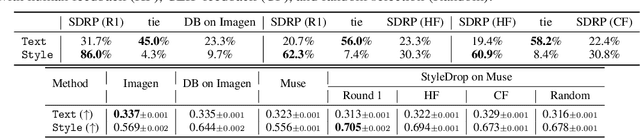


Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language and out-of-distribution effects make it hard to synthesize image styles, that leverage a specific design pattern, texture or material. In this paper, we introduce StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than $1\%$ of total model parameters) and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image that specifies the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop implemented on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: https://styledrop.github.io
Improving CLIP Training with Language Rewrites
May 31, 2023



Contrastive Language-Image Pre-training (CLIP) stands as one of the most effective and scalable methods for training transferable vision models using paired image and text data. CLIP models are trained using contrastive loss, which typically relies on data augmentations to prevent overfitting and shortcuts. However, in the CLIP training paradigm, data augmentations are exclusively applied to image inputs, while language inputs remain unchanged throughout the entire training process, limiting the exposure of diverse texts to the same image. In this paper, we introduce Language augmented CLIP (LaCLIP), a simple yet highly effective approach to enhance CLIP training through language rewrites. Leveraging the in-context learning capability of large language models, we rewrite the text descriptions associated with each image. These rewritten texts exhibit diversity in sentence structure and vocabulary while preserving the original key concepts and meanings. During training, LaCLIP randomly selects either the original texts or the rewritten versions as text augmentations for each image. Extensive experiments on CC3M, CC12M, RedCaps and LAION-400M datasets show that CLIP pre-training with language rewrites significantly improves the transfer performance without computation or memory overhead during training. Specifically for ImageNet zero-shot accuracy, LaCLIP outperforms CLIP by 8.2% on CC12M and 2.4% on LAION-400M. Code is available at https://github.com/LijieFan/LaCLIP.
Steerable Equivariant Representation Learning
Feb 22, 2023



Pre-trained deep image representations are useful for post-training tasks such as classification through transfer learning, image retrieval, and object detection. Data augmentations are a crucial aspect of pre-training robust representations in both supervised and self-supervised settings. Data augmentations explicitly or implicitly promote invariance in the embedding space to the input image transformations. This invariance reduces generalization to those downstream tasks which rely on sensitivity to these particular data augmentations. In this paper, we propose a method of learning representations that are instead equivariant to data augmentations. We achieve this equivariance through the use of steerable representations. Our representations can be manipulated directly in embedding space via learned linear maps. We demonstrate that our resulting steerable and equivariant representations lead to better performance on transfer learning and robustness: e.g. we improve linear probe top-1 accuracy by between 1% to 3% for transfer; and ImageNet-C accuracy by upto 3.4%. We further show that the steerability of our representations provides significant speedup (nearly 50x) for test-time augmentations; by applying a large number of augmentations for out-of-distribution detection, we significantly improve OOD AUC on the ImageNet-C dataset over an invariant representation.