 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELF: Embedded Language Flows
May 11, 2026Diffusion and flow-based models have become the de facto approaches for generating continuous data, e.g., in domains such as images and videos. Their success has attracted growing interest in applying them to language modeling. Unlike their image-domain counterparts, today's leading diffusion language models (DLMs) primarily operate over discrete tokens. In this paper, we show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. We propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network. This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG). Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
DREAM: Where Visual Understanding Meets Text-to-Image Generation
Mar 03, 2026Unifying visual representation learning and text-to-image (T2I) generation within a single model remains a central challenge in multimodal learning. We introduce DREAM, a unified framework that jointly optimizes discriminative and generative objectives, while learning strong visual representations. DREAM is built on two key techniques: During training, Masking Warmup, a progressive masking schedule, begins with minimal masking to establish the contrastive alignment necessary for representation learning, then gradually transitions to full masking for stable generative training. At inference, DREAM employs Semantically Aligned Decoding to align partially masked image candidates with the target text and select the best one for further decoding, improving text-image fidelity (+6.3%) without external rerankers. Trained solely on CC12M, DREAM achieves 72.7% ImageNet linear-probing accuracy (+1.1% over CLIP) and an FID of 4.25 (+6.2% over FLUID), with consistent gains in few-shot classification, semantic segmentation, and depth estimation. These results demonstrate that discriminative and generative objectives can be synergistic, allowing unified multimodal models that excel at both visual understanding and generation.
Generative Modeling via Drifting
Feb 04, 2026Generative modeling can be formulated as learning a mapping f such that its pushforward distribution matches the data distribution. The pushforward behavior can be carried out iteratively at inference time, for example in diffusion and flow-based models. In this paper, we propose a new paradigm called Drifting Models, which evolve the pushforward distribution during training and naturally admit one-step inference. We introduce a drifting field that governs the sample movement and achieves equilibrium when the distributions match. This leads to a training objective that allows the neural network optimizer to evolve the distribution. In experiments, our one-step generator achieves state-of-the-art results on ImageNet at 256 x 256 resolution, with an FID of 1.54 in latent space and 1.61 in pixel space. We hope that our work opens up new opportunities for high-quality one-step generation.
Physiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
One-step Latent-free Image Generation with Pixel Mean Flows
Jan 29, 2026Modern diffusion/flow-based models for image generation typically exhibit two core characteristics: (i) using multi-step sampling, and (ii) operating in a latent space. Recent advances have made encouraging progress on each aspect individually, paving the way toward one-step diffusion/flow without latents. In this work, we take a further step towards this goal and propose "pixel MeanFlow" (pMF). Our core guideline is to formulate the network output space and the loss space separately. The network target is designed to be on a presumed low-dimensional image manifold (i.e., x-prediction), while the loss is defined via MeanFlow in the velocity space. We introduce a simple transformation between the image manifold and the average velocity field. In experiments, pMF achieves strong results for one-step latent-free generation on ImageNet at 256x256 resolution (2.22 FID) and 512x512 resolution (2.48 FID), filling a key missing piece in this regime. We hope that our study will further advance the boundaries of diffusion/flow-based generative models.
Back to Basics: Let Denoising Generative Models Denoise
Nov 17, 2025Today's denoising diffusion models do not "denoise" in the classical sense, i.e., they do not directly predict clean images. Rather, the neural networks predict noise or a noised quantity. In this paper, we suggest that predicting clean data and predicting noised quantities are fundamentally different. According to the manifold assumption, natural data should lie on a low-dimensional manifold, whereas noised quantities do not. With this assumption, we advocate for models that directly predict clean data, which allows apparently under-capacity networks to operate effectively in very high-dimensional spaces. We show that simple, large-patch Transformers on pixels can be strong generative models: using no tokenizer, no pre-training, and no extra loss. Our approach is conceptually nothing more than "$\textbf{Just image Transformers}$", or $\textbf{JiT}$, as we call it. We report competitive results using JiT with large patch sizes of 16 and 32 on ImageNet at resolutions of 256 and 512, where predicting high-dimensional noised quantities can fail catastrophically. With our networks mapping back to the basics of the manifold, our research goes back to basics and pursues a self-contained paradigm for Transformer-based diffusion on raw natural data.
Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
Fractal Generative Models
Feb 25, 2025Modularization is a cornerstone of computer science, abstracting complex functions into atomic building blocks. In this paper, we introduce a new level of modularization by abstracting generative models into atomic generative modules. Analogous to fractals in mathematics, our method constructs a new type of generative model by recursively invoking atomic generative modules, resulting in self-similar fractal architectures that we call fractal generative models. As a running example, we instantiate our fractal framework using autoregressive models as the atomic generative modules and examine it on the challenging task of pixel-by-pixel image generation, demonstrating strong performance in both likelihood estimation and generation quality. We hope this work could open a new paradigm in generative modeling and provide a fertile ground for future research. Code is available at https://github.com/LTH14/fractalgen.
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
Oct 17, 2024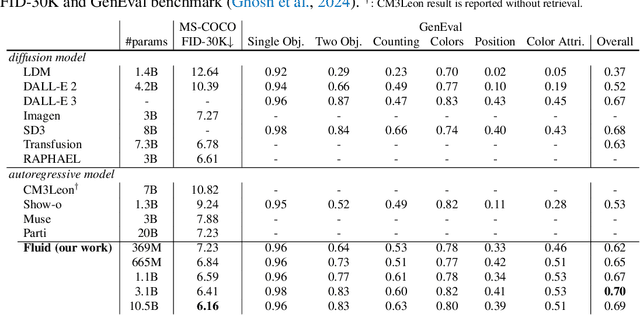
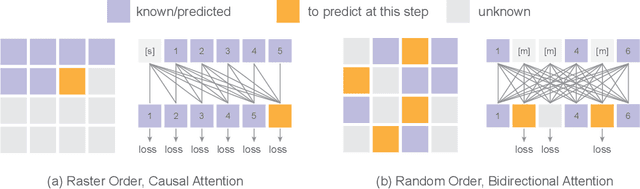
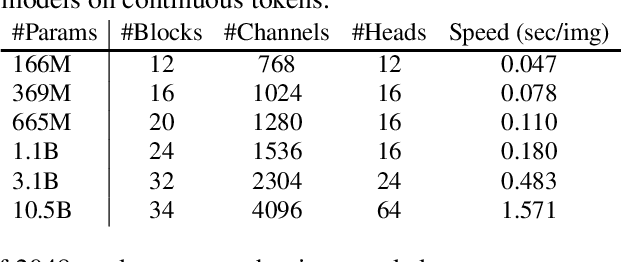
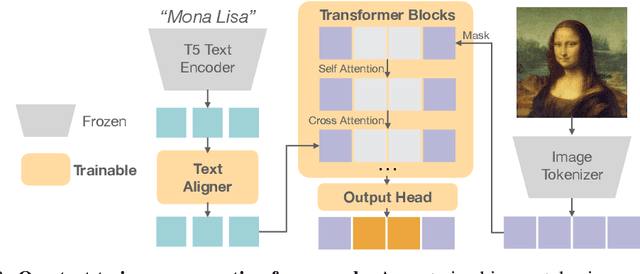
Scaling up autoregressive models in vision has not proven as beneficial as in large language models. In this work, we investigate this scaling problem in the context of text-to-image generation, focusing on two critical factors: whether models use discrete or continuous tokens, and whether tokens are generated in a random or fixed raster order using BERT- or GPT-like transformer architectures. Our empirical results show that, while all models scale effectively in terms of validation loss, their evaluation performance -- measured by FID, GenEval score, and visual quality -- follows different trends. Models based on continuous tokens achieve significantly better visual quality than those using discrete tokens. Furthermore, the generation order and attention mechanisms significantly affect the GenEval score: random-order models achieve notably better GenEval scores compared to raster-order models. Inspired by these findings, we train Fluid, a random-order autoregressive model on continuous tokens. Fluid 10.5B model achieves a new state-of-the-art zero-shot FID of 6.16 on MS-COCO 30K, and 0.69 overall score on the GenEval benchmark. We hope our findings and results will encourage future efforts to further bridge the scaling gap between vision and language models.