 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss
Dec 29, 2025Mixture-of-Experts (MoE) models lack explicit constraints to ensure the router's decisions align well with the experts' capabilities, which ultimately limits model performance. To address this, we propose expert-router coupling (ERC) loss, a lightweight auxiliary loss that tightly couples the router's decisions with expert capabilities. Our approach treats each expert's router embedding as a proxy token for the tokens assigned to that expert, and feeds perturbed router embeddings through the experts to obtain internal activations. The ERC loss enforces two constraints on these activations: (1) Each expert must exhibit higher activation for its own proxy token than for the proxy tokens of any other expert. (2) Each proxy token must elicit stronger activation from its corresponding expert than from any other expert. These constraints jointly ensure that each router embedding faithfully represents its corresponding expert's capability, while each expert specializes in processing the tokens actually routed to it. The ERC loss is computationally efficient, operating only on n^2 activations, where n is the number of experts. This represents a fixed cost independent of batch size, unlike prior coupling methods that scale with the number of tokens (often millions per batch). Through pre-training MoE-LLMs ranging from 3B to 15B parameters and extensive analysis on trillions of tokens, we demonstrate the effectiveness of the ERC loss. Moreover, the ERC loss offers flexible control and quantitative tracking of expert specialization levels during training, providing valuable insights into MoEs.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
DeMod: A Holistic Tool with Explainable Detection and Personalized Modification for Toxicity Censorship
Nov 04, 2024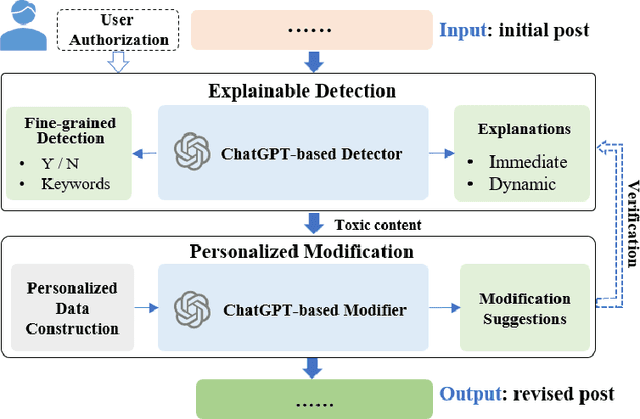
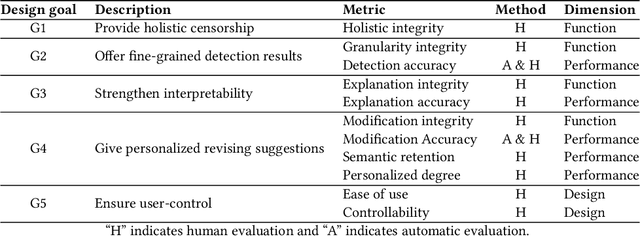
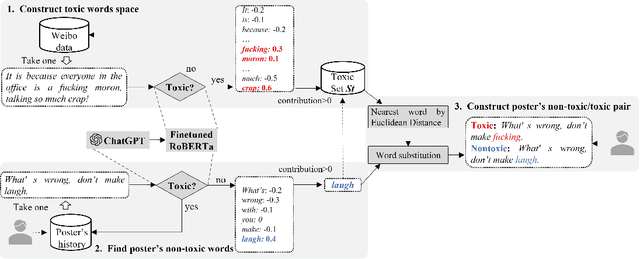
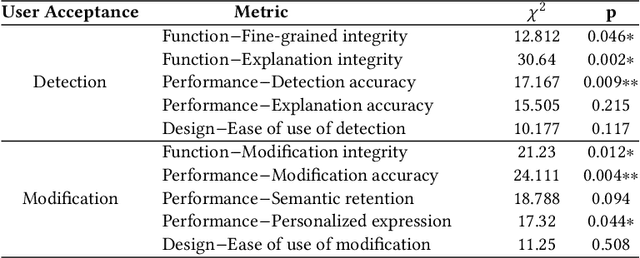
Although there have been automated approaches and tools supporting toxicity censorship for social posts, most of them focus on detection. Toxicity censorship is a complex process, wherein detection is just an initial task and a user can have further needs such as rationale understanding and content modification. For this problem, we conduct a needfinding study to investigate people's diverse needs in toxicity censorship and then build a ChatGPT-based censorship tool named DeMod accordingly. DeMod is equipped with the features of explainable Detection and personalized Modification, providing fine-grained detection results, detailed explanations, and personalized modification suggestions. We also implemented the tool and recruited 35 Weibo users for evaluation. The results suggest DeMod's multiple strengths like the richness of functionality, the accuracy of censorship, and ease of use. Based on the findings, we further propose several insights into the design of content censorship systems.
Advancing Multimodal Medical Capabilities of Gemini
May 06, 2024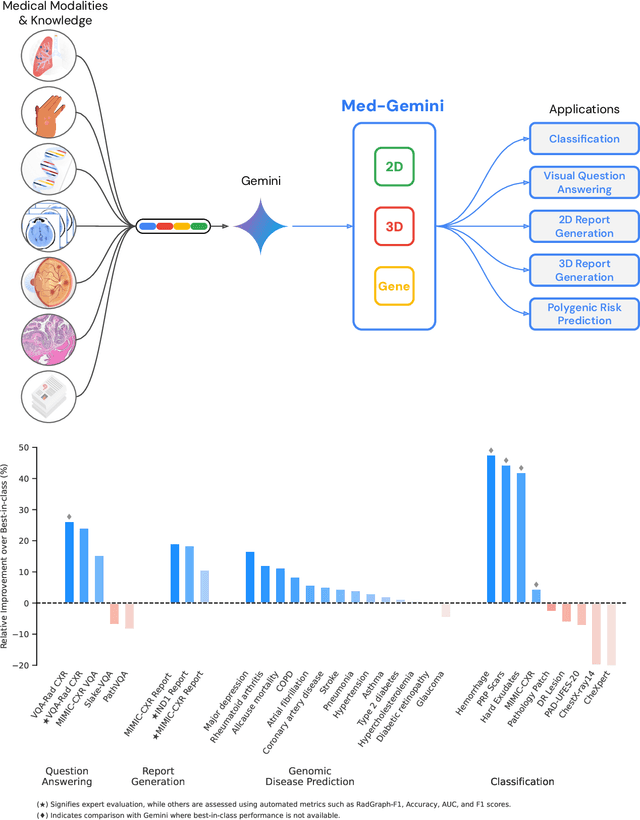
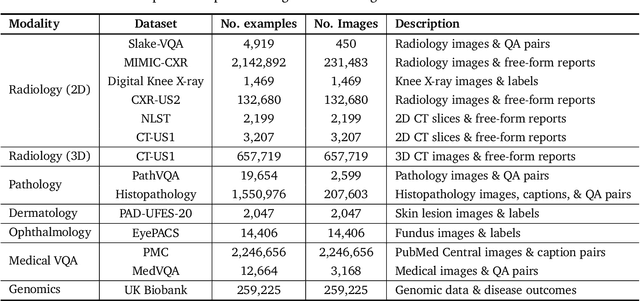

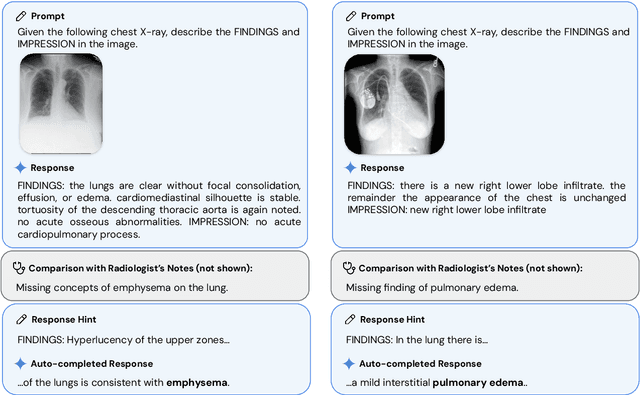
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
Mar 28, 2024



Image retrieval, i.e., finding desired images given a reference image, inherently encompasses rich, multi-faceted search intents that are difficult to capture solely using image-based measures. Recent work leverages text instructions to allow users to more freely express their search intents. However, existing work primarily focuses on image pairs that are visually similar and/or can be characterized by a small set of pre-defined relations. The core thesis of this paper is that text instructions can enable retrieving images with richer relations beyond visual similarity. To show this, we introduce MagicLens, a series of self-supervised image retrieval models that support open-ended instructions. MagicLens is built on a key novel insight: image pairs that naturally occur on the same web pages contain a wide range of implicit relations (e.g., inside view of), and we can bring those implicit relations explicit by synthesizing instructions via large multimodal models (LMMs) and large language models (LLMs). Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, MagicLens achieves comparable or better results on eight benchmarks of various image retrieval tasks than prior state-of-the-art (SOTA) methods. Remarkably, it outperforms previous SOTA but with a 50X smaller model size on multiple benchmarks. Additional human analyses on a 1.4M-image unseen corpus further demonstrate the diversity of search intents supported by MagicLens.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.