 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Diffusion for 3D Indoor Scene Synthesis
May 31, 2024



Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
PolyMaX: General Dense Prediction with Mask Transformer
Nov 09, 2023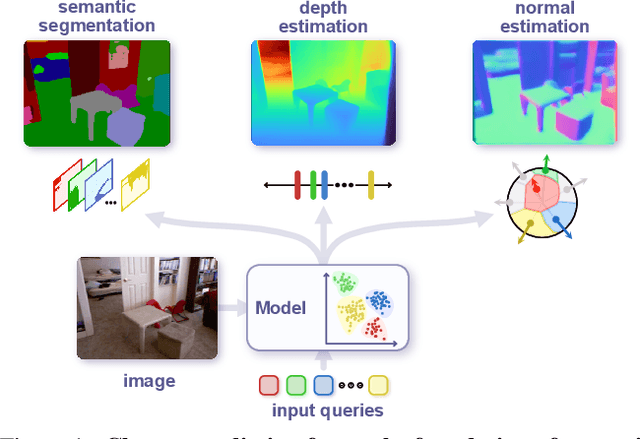
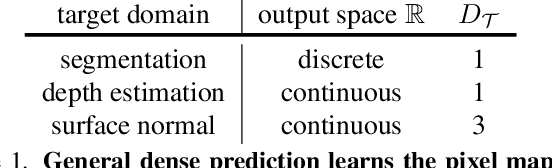
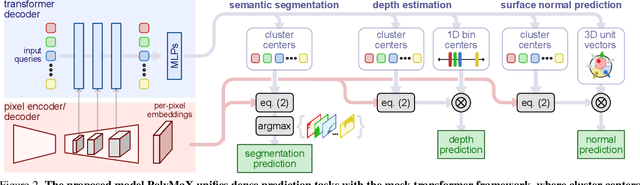
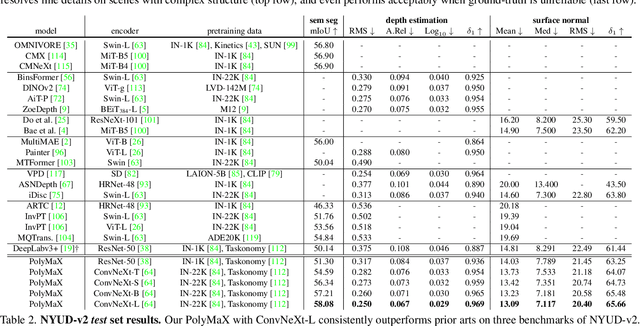
Dense prediction tasks, such as semantic segmentation, depth estimation, and surface normal prediction, can be easily formulated as per-pixel classification (discrete outputs) or regression (continuous outputs). This per-pixel prediction paradigm has remained popular due to the prevalence of fully convolutional networks. However, on the recent frontier of segmentation task, the community has been witnessing a shift of paradigm from per-pixel prediction to cluster-prediction with the emergence of transformer architectures, particularly the mask transformers, which directly predicts a label for a mask instead of a pixel. Despite this shift, methods based on the per-pixel prediction paradigm still dominate the benchmarks on the other dense prediction tasks that require continuous outputs, such as depth estimation and surface normal prediction. Motivated by the success of DORN and AdaBins in depth estimation, achieved by discretizing the continuous output space, we propose to generalize the cluster-prediction based method to general dense prediction tasks. This allows us to unify dense prediction tasks with the mask transformer framework. Remarkably, the resulting model PolyMaX demonstrates state-of-the-art performance on three benchmarks of NYUD-v2 dataset. We hope our simple yet effective design can inspire more research on exploiting mask transformers for more dense prediction tasks. Code and model will be made available.
SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
Sep 21, 2023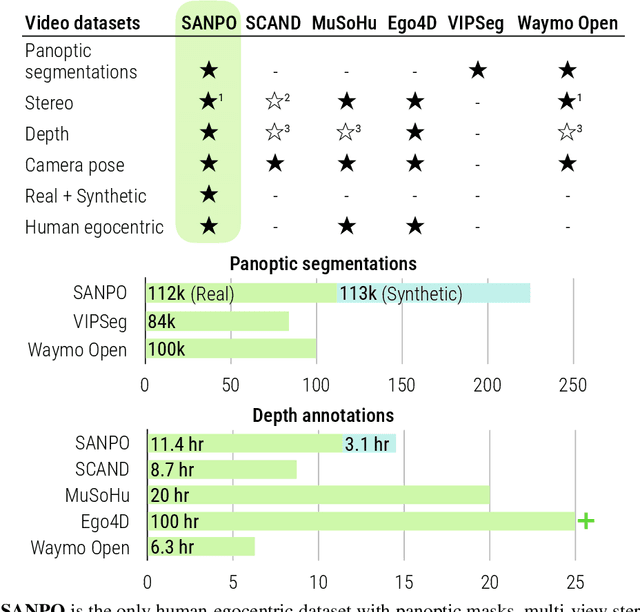
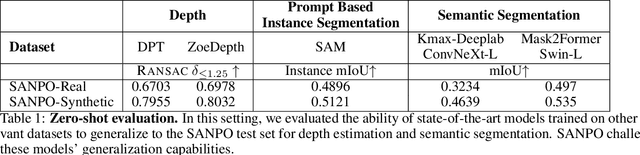
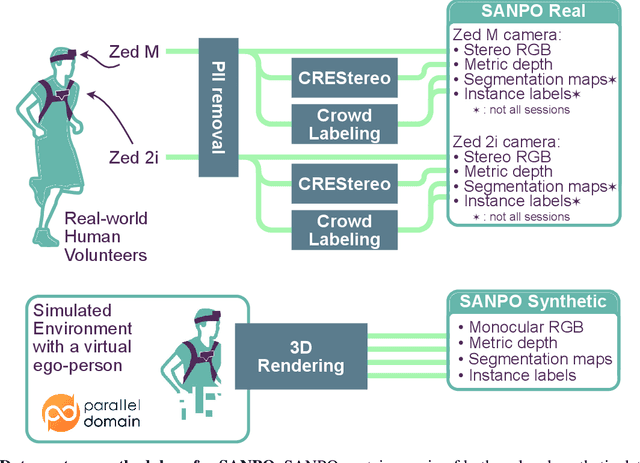
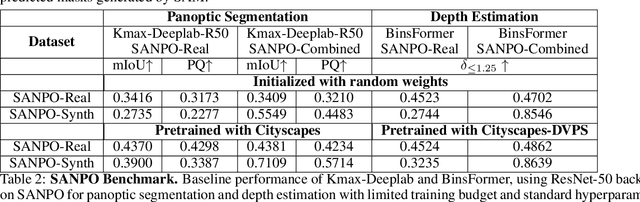
We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems. SANPO is available here: https://google-research-datasets.github.io/sanpo_dataset/