 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Video Masked Autoencoders to 128 frames
Nov 20, 2024



Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
Sep 21, 2023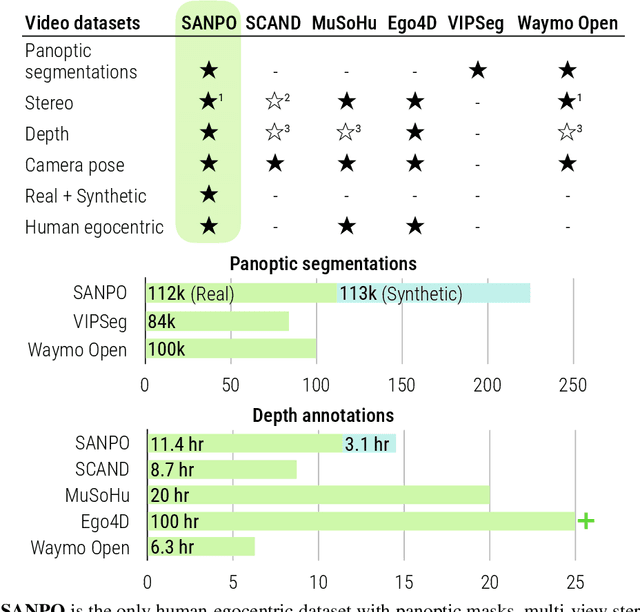
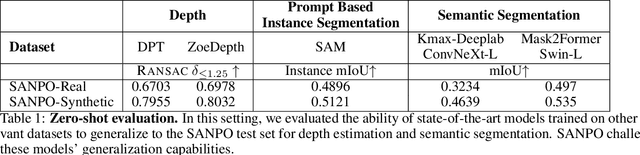
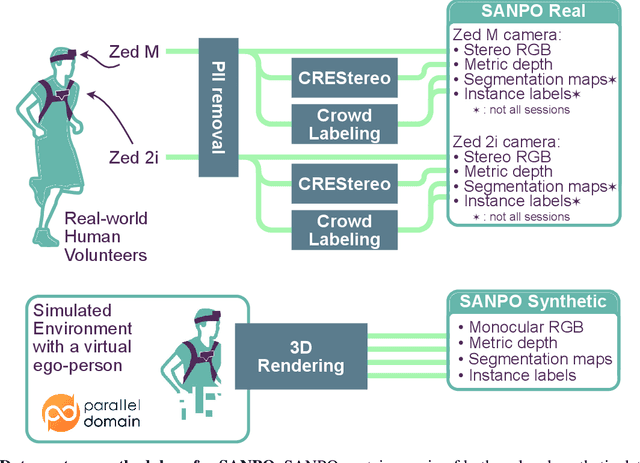
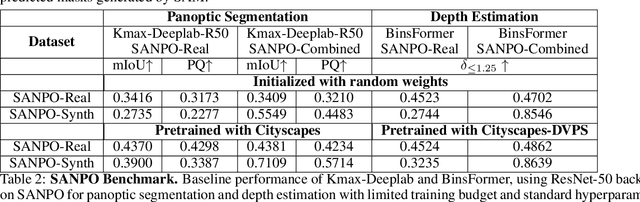
We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems. SANPO is available here: https://google-research-datasets.github.io/sanpo_dataset/
Efficient Image Representation Learning with Federated Sampled Softmax
Mar 09, 2022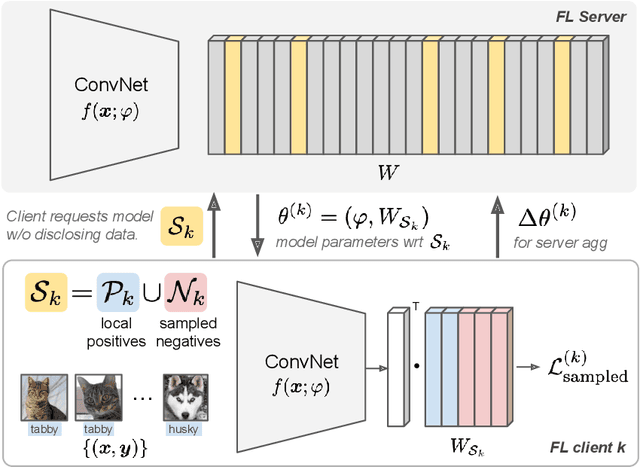
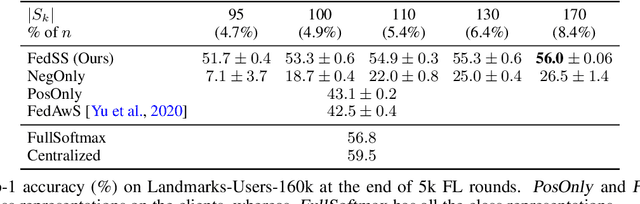
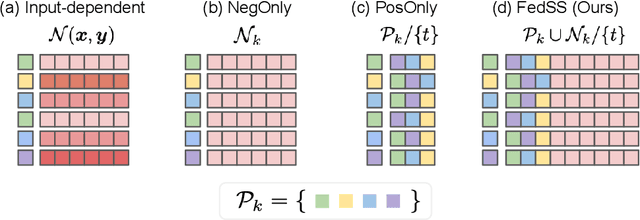
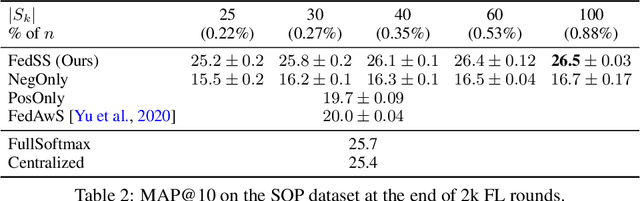
Learning image representations on decentralized data can bring many benefits in cases where data cannot be aggregated across data silos. Softmax cross entropy loss is highly effective and commonly used for learning image representations. Using a large number of classes has proven to be particularly beneficial for the descriptive power of such representations in centralized learning. However, doing so on decentralized data with Federated Learning is not straightforward as the demand on FL clients' computation and communication increases proportionally to the number of classes. In this work we introduce federated sampled softmax (FedSS), a resource-efficient approach for learning image representation with Federated Learning. Specifically, the FL clients sample a set of classes and optimize only the corresponding model parameters with respect to a sampled softmax objective that approximates the global full softmax objective. We examine the loss formulation and empirically show that our method significantly reduces the number of parameters transferred to and optimized by the client devices, while performing on par with the standard full softmax method. This work creates a possibility for efficiently learning image representations on decentralized data with a large number of classes under the federated setting.