 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyMaX: General Dense Prediction with Mask Transformer
Nov 09, 2023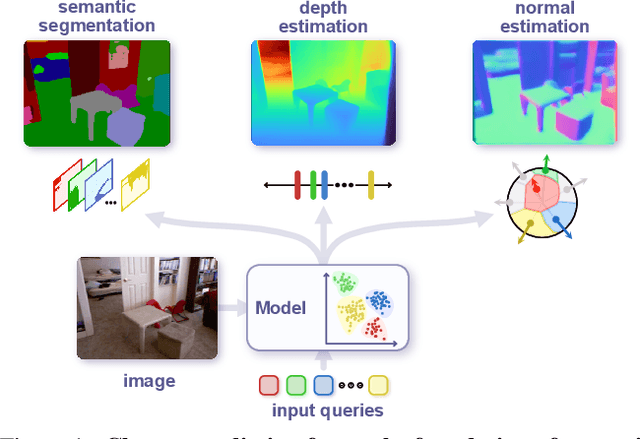
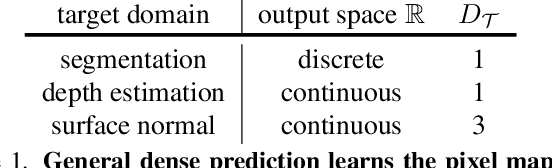
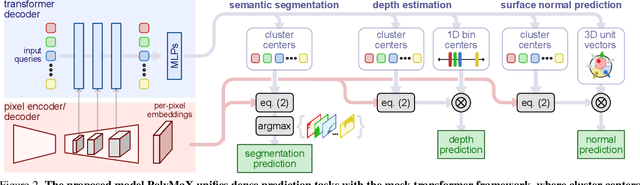
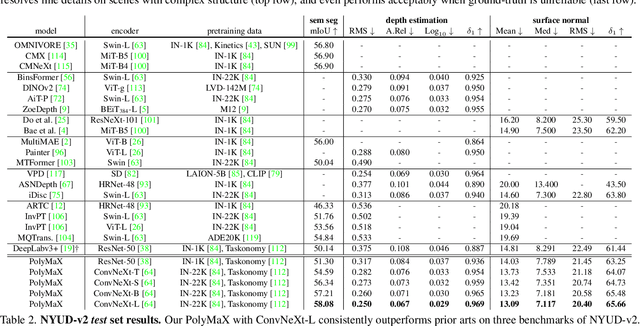
Dense prediction tasks, such as semantic segmentation, depth estimation, and surface normal prediction, can be easily formulated as per-pixel classification (discrete outputs) or regression (continuous outputs). This per-pixel prediction paradigm has remained popular due to the prevalence of fully convolutional networks. However, on the recent frontier of segmentation task, the community has been witnessing a shift of paradigm from per-pixel prediction to cluster-prediction with the emergence of transformer architectures, particularly the mask transformers, which directly predicts a label for a mask instead of a pixel. Despite this shift, methods based on the per-pixel prediction paradigm still dominate the benchmarks on the other dense prediction tasks that require continuous outputs, such as depth estimation and surface normal prediction. Motivated by the success of DORN and AdaBins in depth estimation, achieved by discretizing the continuous output space, we propose to generalize the cluster-prediction based method to general dense prediction tasks. This allows us to unify dense prediction tasks with the mask transformer framework. Remarkably, the resulting model PolyMaX demonstrates state-of-the-art performance on three benchmarks of NYUD-v2 dataset. We hope our simple yet effective design can inspire more research on exploiting mask transformers for more dense prediction tasks. Code and model will be made available.
SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
Sep 21, 2023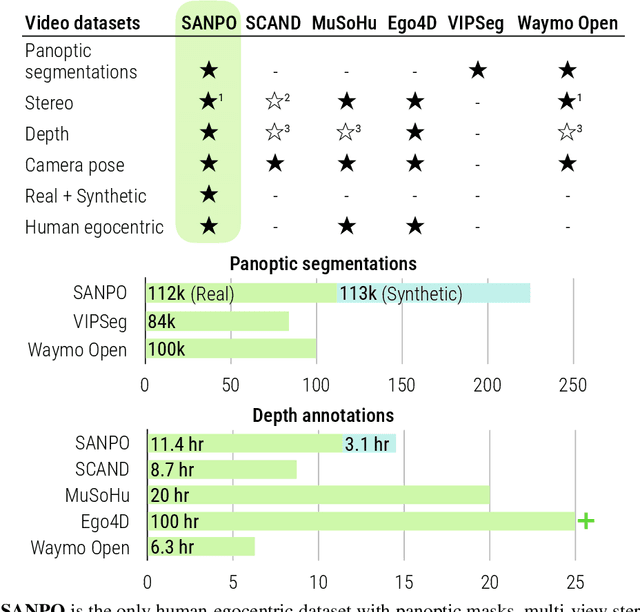
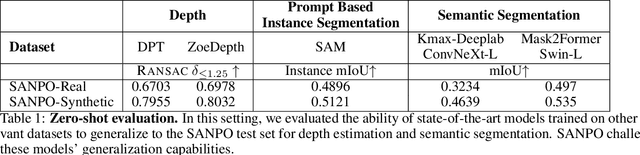
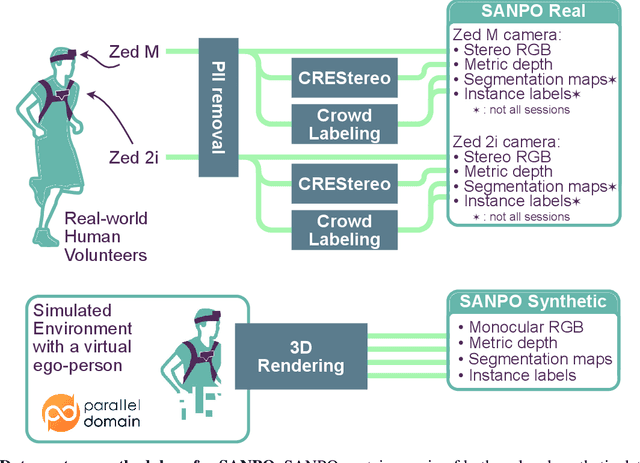
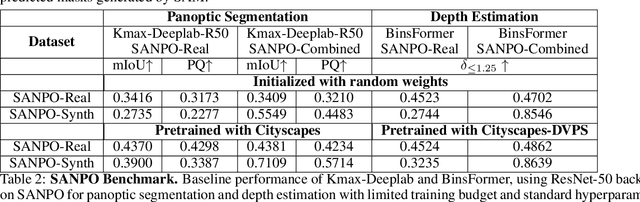
We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems. SANPO is available here: https://google-research-datasets.github.io/sanpo_dataset/
MemSAC: Memory Augmented Sample Consistency for Large Scale Domain Adaptation
Jul 25, 2022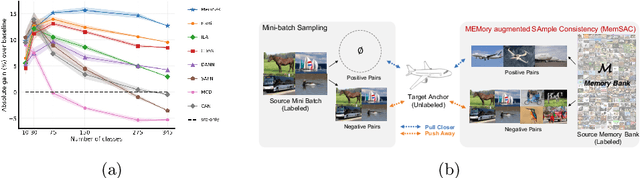



Practical real world datasets with plentiful categories introduce new challenges for unsupervised domain adaptation like small inter-class discriminability, that existing approaches relying on domain invariance alone cannot handle sufficiently well. In this work we propose MemSAC, which exploits sample level similarity across source and target domains to achieve discriminative transfer, along with architectures that scale to a large number of categories. For this purpose, we first introduce a memory augmented approach to efficiently extract pairwise similarity relations between labeled source and unlabeled target domain instances, suited to handle an arbitrary number of classes. Next, we propose and theoretically justify a novel variant of the contrastive loss to promote local consistency among within-class cross domain samples while enforcing separation between classes, thus preserving discriminative transfer from source to target. We validate the advantages of MemSAC with significant improvements over previous state-of-the-art on multiple challenging transfer tasks designed for large-scale adaptation, such as DomainNet with 345 classes and fine-grained adaptation on Caltech-UCSD birds dataset with 200 classes. We also provide in-depth analysis and insights into the effectiveness of MemSAC.
Reducing Racial Bias in Facial Age Prediction using Unsupervised Domain Adaptation in Regression
Apr 05, 2021


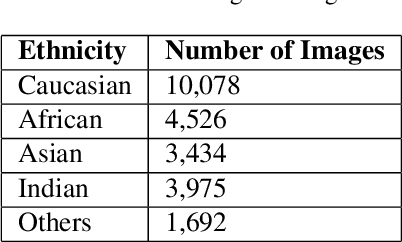
We propose an approach for unsupervised domain adaptation for the task of estimating someone's age from a given face image. In order to avoid the propagation of racial bias in most publicly available face image datasets into the inefficacy of models trained on them, we perform domain adaptation to motivate the predictor to learn features that are invariant to ethnicity, enhancing the generalization performance across faces of people from different ethnic backgrounds. Exploiting the ordinality of age, we also impose ranking constraints on the prediction of the model and design our model such that it takes as input a pair of images, and outputs both the relative age difference and the rank of the first identity with respect to the other in terms of their ages. Furthermore, we implement Multi-Dimensional Scaling to retrieve absolute ages from the predicted age differences from as few as two labeled images from the domain to be adapted to. We experiment with a publicly available dataset with age labels, dividing it into subsets based on the ethnicity labels, and evaluating the performance of our approach on the data from an ethnicity different from the one that the model is trained on. Additionally, we impose a constraint to preserve the sanity of the predictions with respect to relative and absolute ages, and another to ensure the smoothness of the predictions with respect to the input. We experiment extensively and compare various domain adaptation approaches for the task of regression.
Instance Level Affinity-Based Transfer for Unsupervised Domain Adaptation
Apr 03, 2021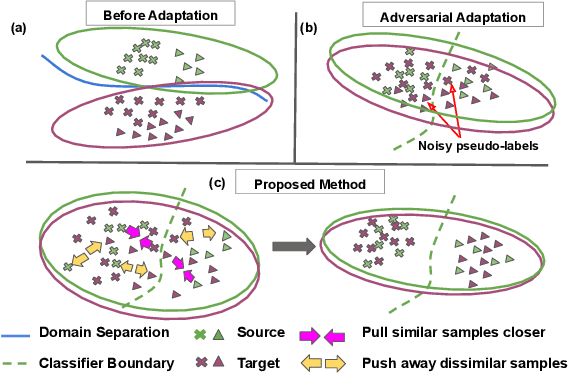

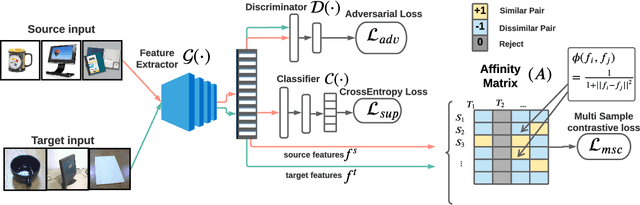

Domain adaptation deals with training models using large scale labeled data from a specific source domain and then adapting the knowledge to certain target domains that have few or no labels. Many prior works learn domain agnostic feature representations for this purpose using a global distribution alignment objective which does not take into account the finer class specific structure in the source and target domains. We address this issue in our work and propose an instance affinity based criterion for source to target transfer during adaptation, called ILA-DA. We first propose a reliable and efficient method to extract similar and dissimilar samples across source and target, and utilize a multi-sample contrastive loss to drive the domain alignment process. ILA-DA simultaneously accounts for intra-class clustering as well as inter-class separation among the categories, resulting in less noisy classifier boundaries, improved transferability and increased accuracy. We verify the effectiveness of ILA-DA by observing consistent improvements in accuracy over popular domain adaptation approaches on a variety of benchmark datasets and provide insights into the proposed alignment approach. Code will be made publicly available at https://github.com/astuti/ILA-DA.