 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
Tell, Don't Show!: Language Guidance Eases Transfer Across Domains in Images and Videos
Mar 08, 2024



We introduce LaGTran, a novel framework that utilizes readily available or easily acquired text descriptions to guide robust transfer of discriminative knowledge from labeled source to unlabeled target data with domain shifts. While unsupervised adaptation methods have been established to address this problem, they show limitations in handling challenging domain shifts due to their exclusive operation within the pixel-space. Motivated by our observation that semantically richer text modality has more favorable transfer properties, we devise a transfer mechanism to use a source-trained text-classifier to generate predictions on the target text descriptions, and utilize these predictions as supervision for the corresponding images. Our approach driven by language guidance is surprisingly easy and simple, yet significantly outperforms all prior approaches on challenging datasets like GeoNet and DomainNet, validating its extreme effectiveness. To further extend the scope of our study beyond images, we introduce a new benchmark to study ego-exo transfer in videos and find that our language-aided LaGTran yields significant gains in this highly challenging and non-trivial transfer setting. Code, models, and proposed datasets are publicly available at https://tarun005.github.io/lagtran/.
GeoNet: Benchmarking Unsupervised Adaptation across Geographies
Mar 27, 2023In recent years, several efforts have been aimed at improving the robustness of vision models to domains and environments unseen during training. An important practical problem pertains to models deployed in a new geography that is under-represented in the training dataset, posing a direct challenge to fair and inclusive computer vision. In this paper, we study the problem of geographic robustness and make three main contributions. First, we introduce a large-scale dataset GeoNet for geographic adaptation containing benchmarks across diverse tasks like scene recognition (GeoPlaces), image classification (GeoImNet) and universal adaptation (GeoUniDA). Second, we investigate the nature of distribution shifts typical to the problem of geographic adaptation and hypothesize that the major source of domain shifts arise from significant variations in scene context (context shift), object design (design shift) and label distribution (prior shift) across geographies. Third, we conduct an extensive evaluation of several state-of-the-art unsupervised domain adaptation algorithms and architectures on GeoNet, showing that they do not suffice for geographical adaptation, and that large-scale pre-training using large vision models also does not lead to geographic robustness. Our dataset is publicly available at https://tarun005.github.io/GeoNet.
Open-world Instance Segmentation: Top-down Learning with Bottom-up Supervision
Mar 09, 2023



Many top-down architectures for instance segmentation achieve significant success when trained and tested on pre-defined closed-world taxonomy. However, when deployed in the open world, they exhibit notable bias towards seen classes and suffer from significant performance drop. In this work, we propose a novel approach for open world instance segmentation called bottom-Up and top-Down Open-world Segmentation (UDOS) that combines classical bottom-up segmentation algorithms within a top-down learning framework. UDOS first predicts parts of objects using a top-down network trained with weak supervision from bottom-up segmentations. The bottom-up segmentations are class-agnostic and do not overfit to specific taxonomies. The part-masks are then fed into affinity-based grouping and refinement modules to predict robust instance-level segmentations. UDOS enjoys both the speed and efficiency from the top-down architectures and the generalization ability to unseen categories from bottom-up supervision. We validate the strengths of UDOS on multiple cross-category as well as cross-dataset transfer tasks from 5 challenging datasets including MS-COCO, LVIS, ADE20k, UVO and OpenImages, achieving significant improvements over state-of-the-art across the board. Our code and models are available on our project page.
Cluster-to-adapt: Few Shot Domain Adaptation for Semantic Segmentation across Disjoint Labels
Aug 04, 2022
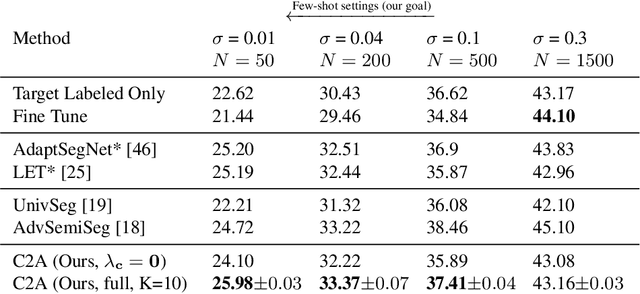
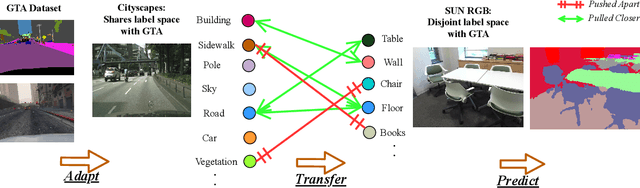
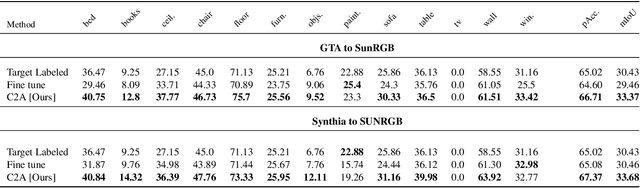
Domain adaptation for semantic segmentation across datasets consisting of the same categories has seen several recent successes. However, a more general scenario is when the source and target datasets correspond to non-overlapping label spaces. For example, categories in segmentation datasets change vastly depending on the type of environment or application, yet share many valuable semantic relations. Existing approaches based on feature alignment or discrepancy minimization do not take such category shift into account. In this work, we present Cluster-to-Adapt (C2A), a computationally efficient clustering-based approach for domain adaptation across segmentation datasets with completely different, but possibly related categories. We show that such a clustering objective enforced in a transformed feature space serves to automatically select categories across source and target domains that can be aligned for improving the target performance, while preventing negative transfer for unrelated categories. We demonstrate the effectiveness of our approach through experiments on the challenging problem of outdoor to indoor adaptation for semantic segmentation in few-shot as well as zero-shot settings, with consistent improvements in performance over existing approaches and baselines in all cases.
MemSAC: Memory Augmented Sample Consistency for Large Scale Domain Adaptation
Jul 25, 2022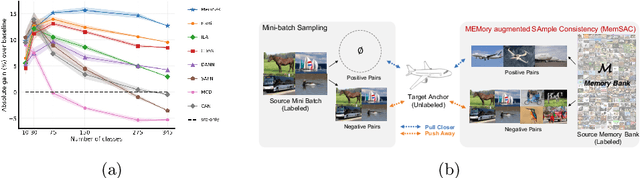



Practical real world datasets with plentiful categories introduce new challenges for unsupervised domain adaptation like small inter-class discriminability, that existing approaches relying on domain invariance alone cannot handle sufficiently well. In this work we propose MemSAC, which exploits sample level similarity across source and target domains to achieve discriminative transfer, along with architectures that scale to a large number of categories. For this purpose, we first introduce a memory augmented approach to efficiently extract pairwise similarity relations between labeled source and unlabeled target domain instances, suited to handle an arbitrary number of classes. Next, we propose and theoretically justify a novel variant of the contrastive loss to promote local consistency among within-class cross domain samples while enforcing separation between classes, thus preserving discriminative transfer from source to target. We validate the advantages of MemSAC with significant improvements over previous state-of-the-art on multiple challenging transfer tasks designed for large-scale adaptation, such as DomainNet with 345 classes and fine-grained adaptation on Caltech-UCSD birds dataset with 200 classes. We also provide in-depth analysis and insights into the effectiveness of MemSAC.
Instance Level Affinity-Based Transfer for Unsupervised Domain Adaptation
Apr 03, 2021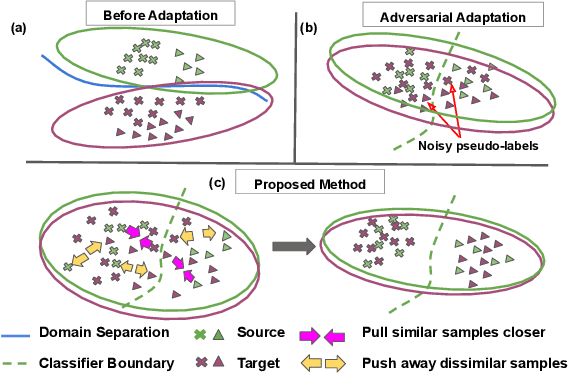

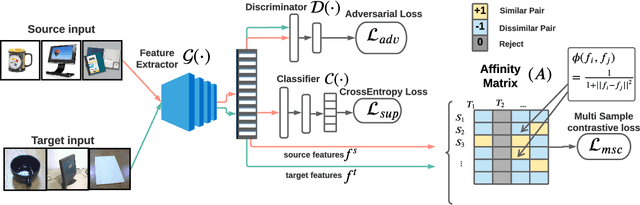

Domain adaptation deals with training models using large scale labeled data from a specific source domain and then adapting the knowledge to certain target domains that have few or no labels. Many prior works learn domain agnostic feature representations for this purpose using a global distribution alignment objective which does not take into account the finer class specific structure in the source and target domains. We address this issue in our work and propose an instance affinity based criterion for source to target transfer during adaptation, called ILA-DA. We first propose a reliable and efficient method to extract similar and dissimilar samples across source and target, and utilize a multi-sample contrastive loss to drive the domain alignment process. ILA-DA simultaneously accounts for intra-class clustering as well as inter-class separation among the categories, resulting in less noisy classifier boundaries, improved transferability and increased accuracy. We verify the effectiveness of ILA-DA by observing consistent improvements in accuracy over popular domain adaptation approaches on a variety of benchmark datasets and provide insights into the proposed alignment approach. Code will be made publicly available at https://github.com/astuti/ILA-DA.
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation
Dec 15, 2020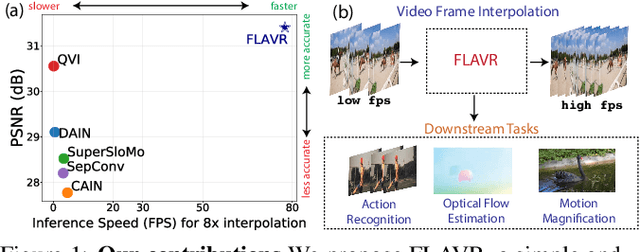
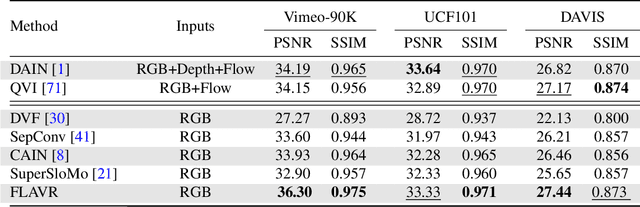
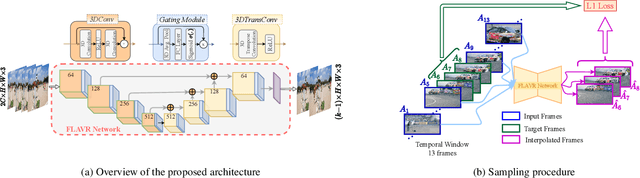

A majority of approaches solve the problem of video frame interpolation by computing bidirectional optical flow between adjacent frames of a video followed by a suitable warping algorithm to generate the output frames. However, methods relying on optical flow often fail to model occlusions and complex non-linear motions directly from the video and introduce additional bottlenecks unsuitable for real time deployment. To overcome these limitations, we propose a flexible and efficient architecture that makes use of 3D space-time convolutions to enable end to end learning and inference for the task of video frame interpolation. Our method efficiently learns to reason about non-linear motions, complex occlusions and temporal abstractions resulting in improved performance on video interpolation, while requiring no additional inputs in the form of optical flow or depth maps. Due to its simplicity, our proposed method improves the inference speed by 384x compared to the current most accurate method and 23x compared to the current fastest on 8x interpolation. In addition, we evaluate our model on a wide range of challenging settings and consistently demonstrate superior qualitative and quantitative results compared with current methods on various popular benchmarks including Vimeo-90K, UCF101, DAVIS, Adobe, and GoPro. Finally, we demonstrate that video frame interpolation can serve as a useful self-supervised pretext task for action recognition, optical flow estimation, and motion magnification.