 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic
Mar 10, 2026Large language model (LLM)-based AI systems have shown promise for patient-facing diagnostic and management conversations in simulated settings. Translating these systems into clinical practice requires assessment in real-world workflows with rigorous safety oversight. We report a prospective, single-arm feasibility study of an LLM-based conversational AI, the Articulate Medical Intelligence Explorer (AMIE), conducting clinical history taking and presentation of potential diagnoses for patients to discuss with their provider at urgent care appointments at a leading academic medical center. 100 adult patients completed an AMIE text-chat interaction up to 5 days before their appointment. We sought to assess the conversational safety and quality, patient and clinician experience, and clinical reasoning capabilities compared to primary care providers (PCPs). Human safety supervisors monitored all patient-AMIE interactions in real time and did not need to intervene to stop any consultations based on pre-defined criteria. Patients reported high satisfaction and their attitudes towards AI improved after interacting with AMIE (p < 0.001). PCPs found AMIE's output useful with a positive impact on preparedness. AMIE's differential diagnosis (DDx) included the final diagnosis, per chart review 8 weeks post-encounter, in 90% of cases, with 75% top-3 accuracy. Blinded assessment of AMIE and PCP DDx and management (Mx) plans suggested similar overall DDx and Mx plan quality, without significant differences for DDx (p = 0.6) and appropriateness and safety of Mx (p = 0.1 and 1.0, respectively). PCPs outperformed AMIE in the practicality (p = 0.003) and cost effectiveness (p = 0.004) of Mx. While further research is needed, this study demonstrates the initial feasibility, safety, and user acceptance of conversational AI in a real-world setting, representing crucial steps towards clinical translation.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
Exploiting the Potential of Seq2Seq Models as Robust Few-Shot Learners
Jul 27, 2023

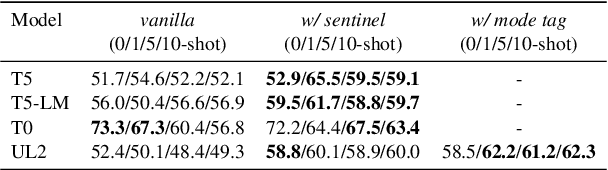

In-context learning, which offers substantial advantages over fine-tuning, is predominantly observed in decoder-only models, while encoder-decoder (i.e., seq2seq) models excel in methods that rely on weight updates. Recently, a few studies have demonstrated the feasibility of few-shot learning with seq2seq models; however, this has been limited to tasks that align well with the seq2seq architecture, such as summarization and translation. Inspired by these initial studies, we provide a first-ever extensive experiment comparing the in-context few-shot learning capabilities of decoder-only and encoder-decoder models on a broad range of tasks. Furthermore, we propose two methods to more effectively elicit in-context learning ability in seq2seq models: objective-aligned prompting and a fusion-based approach. Remarkably, our approach outperforms a decoder-only model that is six times larger and exhibits significant performance improvements compared to conventional seq2seq models across a variety of settings. We posit that, with the right configuration and prompt design, seq2seq models can be highly effective few-shot learners for a wide spectrum of applications.
Pushing the Accuracy-Group Robustness Frontier with Introspective Self-play
Feb 11, 2023Standard empirical risk minimization (ERM) training can produce deep neural network (DNN) models that are accurate on average but under-perform in under-represented population subgroups, especially when there are imbalanced group distributions in the long-tailed training data. Therefore, approaches that improve the accuracy-group robustness trade-off frontier of a DNN model (i.e. improving worst-group accuracy without sacrificing average accuracy, or vice versa) is of crucial importance. Uncertainty-based active learning (AL) can potentially improve the frontier by preferentially sampling underrepresented subgroups to create a more balanced training dataset. However, the quality of uncertainty estimates from modern DNNs tend to degrade in the presence of spurious correlations and dataset bias, compromising the effectiveness of AL for sampling tail groups. In this work, we propose Introspective Self-play (ISP), a simple approach to improve the uncertainty estimation of a deep neural network under dataset bias, by adding an auxiliary introspection task requiring a model to predict the bias for each data point in addition to the label. We show that ISP provably improves the bias-awareness of the model representation and the resulting uncertainty estimates. On two real-world tabular and language tasks, ISP serves as a simple "plug-in" for AL model training, consistently improving both the tail-group sampling rate and the final accuracy-fairness trade-off frontier of popular AL methods.
Dense but Efficient VideoQA for Intricate Compositional Reasoning
Oct 19, 2022
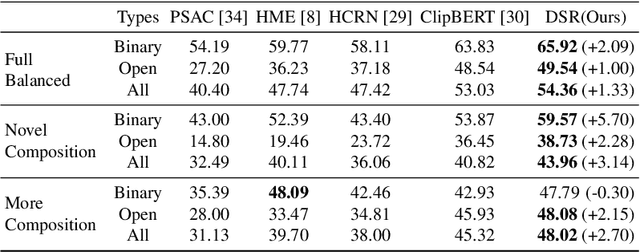
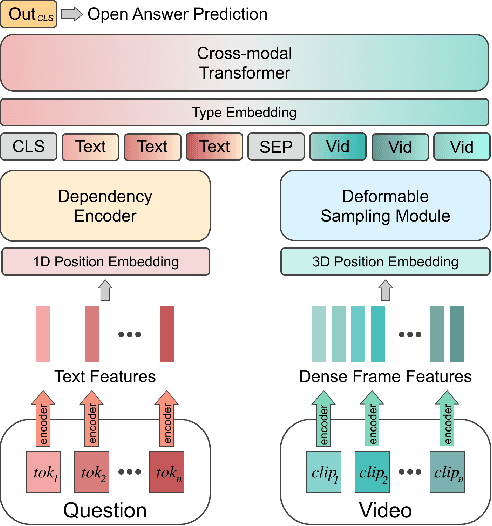
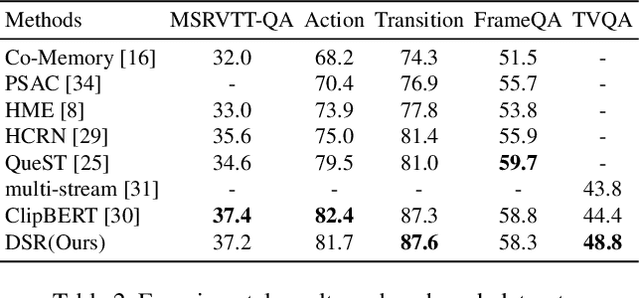
It is well known that most of the conventional video question answering (VideoQA) datasets consist of easy questions requiring simple reasoning processes. However, long videos inevitably contain complex and compositional semantic structures along with the spatio-temporal axis, which requires a model to understand the compositional structures inherent in the videos. In this paper, we suggest a new compositional VideoQA method based on transformer architecture with a deformable attention mechanism to address the complex VideoQA tasks. The deformable attentions are introduced to sample a subset of informative visual features from the dense visual feature map to cover a temporally long range of frames efficiently. Furthermore, the dependency structure within the complex question sentences is also combined with the language embeddings to readily understand the relations among question words. Extensive experiments and ablation studies show that the suggested dense but efficient model outperforms other baselines.
PePe: Personalized Post-editing Model utilizing User-generated Post-edits
Sep 21, 2022
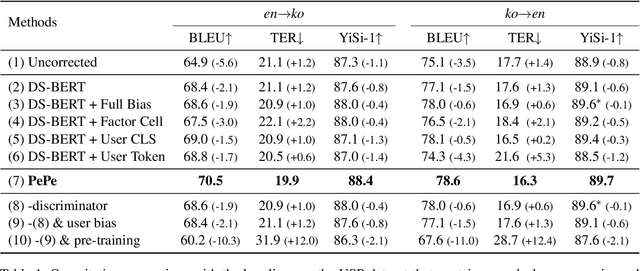
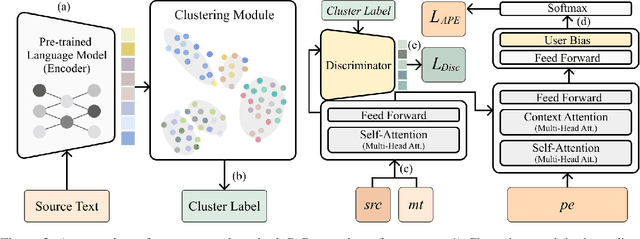
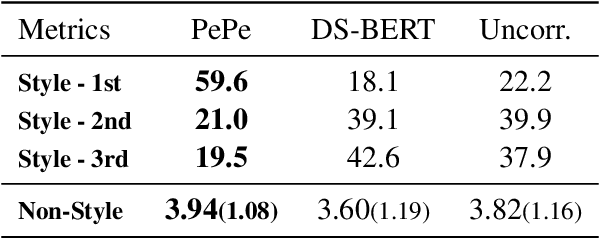
Incorporating personal preference is crucial in advanced machine translation tasks. Despite the recent advancement of machine translation, it remains a demanding task to properly reflect personal style. In this paper, we introduce a personalized automatic post-editing framework to address this challenge, which effectively generates sentences considering distinct personal behaviors. To build this framework, we first collect post-editing data that connotes the user preference from a live machine translation system. Specifically, real-world users enter source sentences for translation and edit the machine-translated outputs according to the user's preferred style. We then propose a model that combines a discriminator module and user-specific parameters on the APE framework. Experimental results show that the proposed method outperforms other baseline models on four different metrics (i.e., BLEU, TER, YiSi-1, and human evaluation).
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021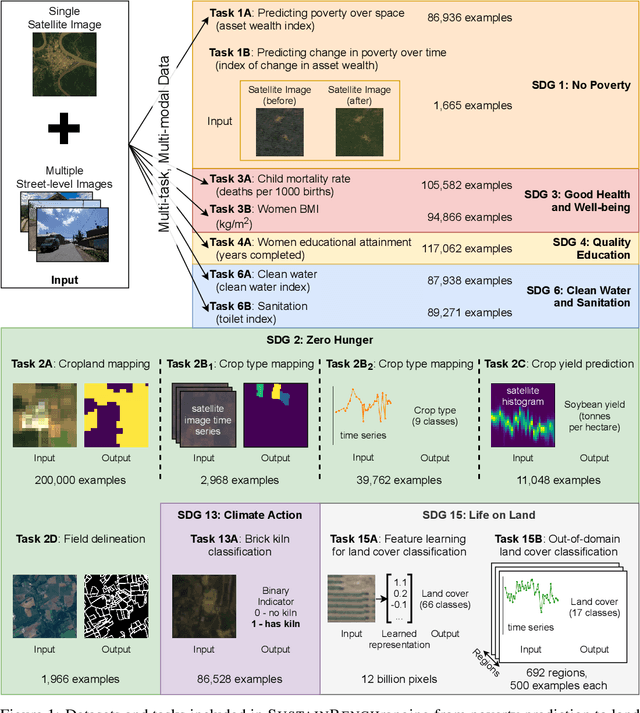
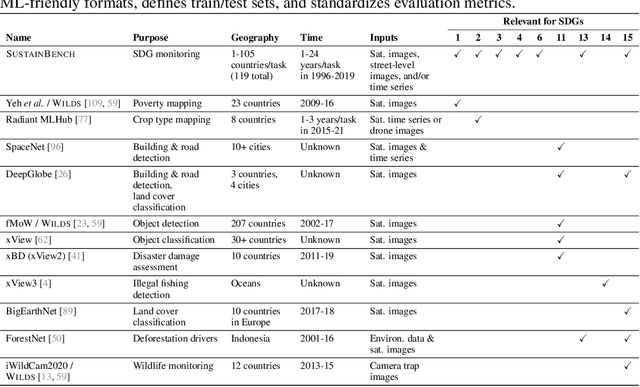
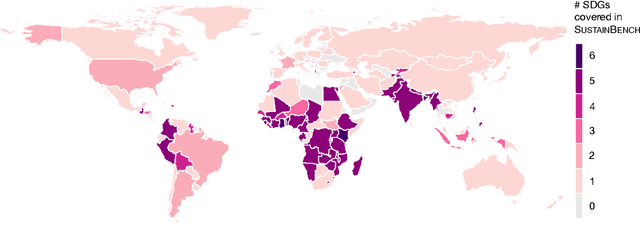
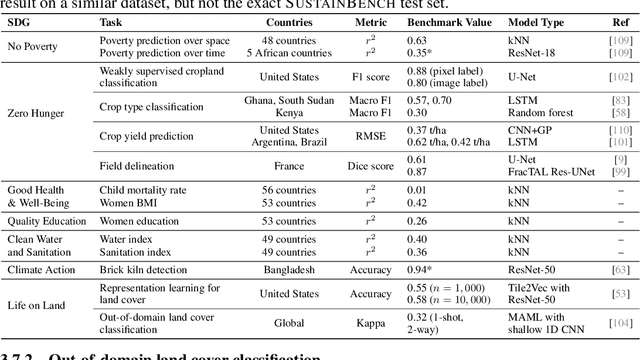
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
BiaSwap: Removing dataset bias with bias-tailored swapping augmentation
Aug 23, 2021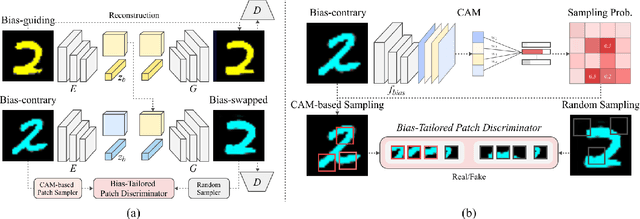
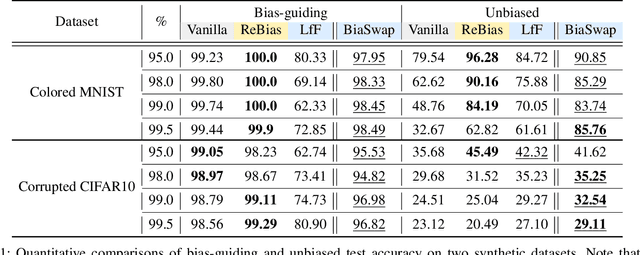

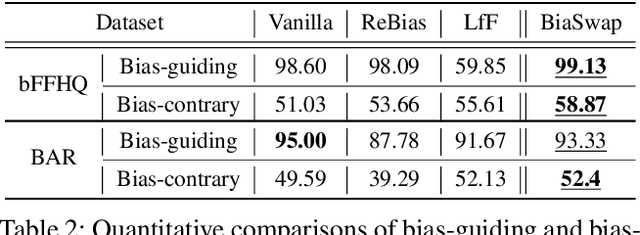
Deep neural networks often make decisions based on the spurious correlations inherent in the dataset, failing to generalize in an unbiased data distribution. Although previous approaches pre-define the type of dataset bias to prevent the network from learning it, recognizing the bias type in the real dataset is often prohibitive. This paper proposes a novel bias-tailored augmentation-based approach, BiaSwap, for learning debiased representation without requiring supervision on the bias type. Assuming that the bias corresponds to the easy-to-learn attributes, we sort the training images based on how much a biased classifier can exploits them as shortcut and divide them into bias-guiding and bias-contrary samples in an unsupervised manner. Afterwards, we integrate the style-transferring module of the image translation model with the class activation maps of such biased classifier, which enables to primarily transfer the bias attributes learned by the classifier. Therefore, given the pair of bias-guiding and bias-contrary, BiaSwap generates the bias-swapped image which contains the bias attributes from the bias-contrary images, while preserving bias-irrelevant ones in the bias-guiding images. Given such augmented images, BiaSwap demonstrates the superiority in debiasing against the existing baselines over both synthetic and real-world datasets. Even without careful supervision on the bias, BiaSwap achieves a remarkable performance on both unbiased and bias-guiding samples, implying the improved generalization capability of the model.
Learning Debiased Representation via Disentangled Feature Augmentation
Jul 03, 2021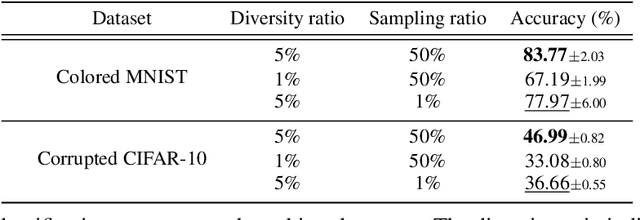
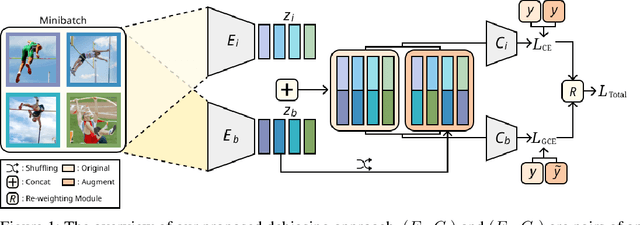

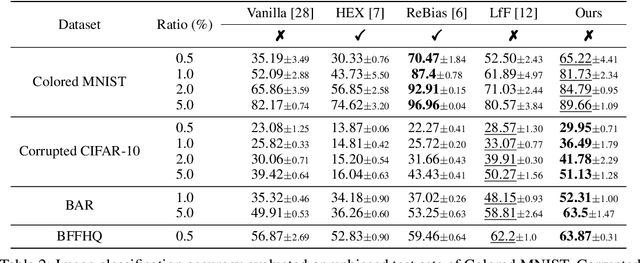
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as real-world datasets.