 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Direct Preference Optimization for Medical Large Vision-Language Models
Jan 25, 2026Large Vision-Language Models (LVLMs) hold significant promise for medical applications, yet their deployment is often constrained by insufficient alignment and reliability. While Direct Preference Optimization (DPO) has emerged as a potent framework for refining model responses, its efficacy in high-stakes medical contexts remains underexplored, lacking the rigorous empirical groundwork necessary to guide future methodological advances. To bridge this gap, we present the first comprehensive examination of diverse DPO variants within the medical domain, evaluating nine distinct formulations across two medical LVLMs: LLaVA-Med and HuatuoGPT-Vision. Our results reveal several critical limitations: current DPO approaches often yield inconsistent gains over supervised fine-tuning, with their efficacy varying significantly across different tasks and backbones. Furthermore, they frequently fail to resolve fundamental visual misinterpretation errors. Building on these insights, we present a targeted preference construction strategy as a proof-of-concept that explicitly addresses visual misinterpretation errors frequently observed in existing DPO models. This design yields a 3.6% improvement over the strongest existing DPO baseline on visual question-answering tasks. To support future research, we release our complete framework, including all training data, model checkpoints, and our codebase at https://github.com/dmis-lab/med-vlm-dpo.
LAPIS: Language Model-Augmented Police Investigation System
Jul 31, 2024Crime situations are race against time. An AI-assisted criminal investigation system, providing prompt but precise legal counsel is in need for police officers. We introduce LAPIS (Language Model Augmented Police Investigation System), an automated system that assists police officers to perform rational and legal investigative actions. We constructed a finetuning dataset and retrieval knowledgebase specialized in crime investigation legal reasoning task. We extended the dataset's quality by incorporating manual curation efforts done by a group of domain experts. We then finetuned the pretrained weights of a smaller Korean language model to the newly constructed dataset and integrated it with the crime investigation knowledgebase retrieval approach. Experimental results show LAPIS' potential in providing reliable legal guidance for police officers, even better than the proprietary GPT-4 model. Qualitative analysis on the rationales generated by LAPIS demonstrate the model's reasoning ability to leverage the premises and derive legally correct conclusions.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.
Test Time Embedding Normalization for Popularity Bias Mitigation
Sep 01, 2023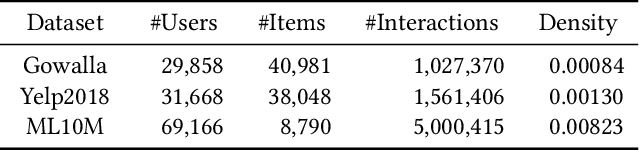
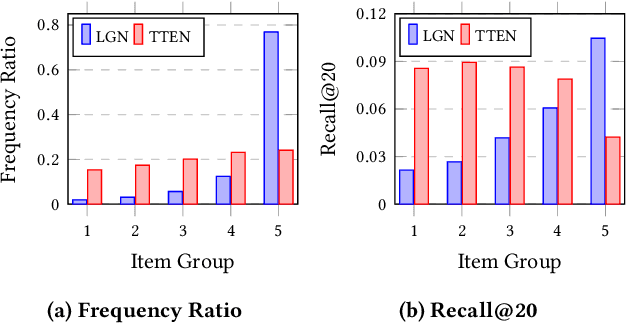
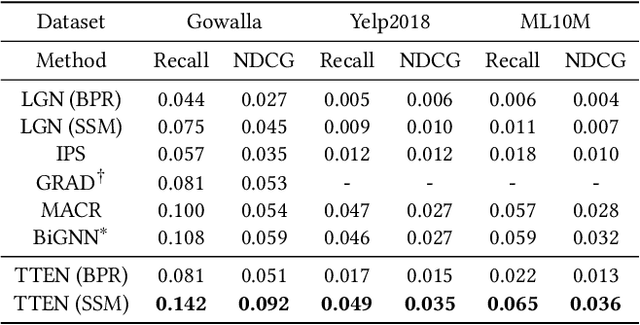
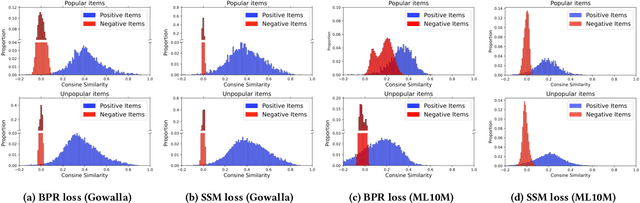
Popularity bias is a widespread problem in the field of recommender systems, where popular items tend to dominate recommendation results. In this work, we propose 'Test Time Embedding Normalization' as a simple yet effective strategy for mitigating popularity bias, which surpasses the performance of the previous mitigation approaches by a significant margin. Our approach utilizes the normalized item embedding during the inference stage to control the influence of embedding magnitude, which is highly correlated with item popularity. Through extensive experiments, we show that our method combined with the sampled softmax loss effectively reduces popularity bias compare to previous approaches for bias mitigation. We further investigate the relationship between user and item embeddings and find that the angular similarity between embeddings distinguishes preferable and non-preferable items regardless of their popularity. The analysis explains the mechanism behind the success of our approach in eliminating the impact of popularity bias. Our code is available at https://github.com/ml-postech/TTEN.
Exploiting the Potential of Seq2Seq Models as Robust Few-Shot Learners
Jul 27, 2023

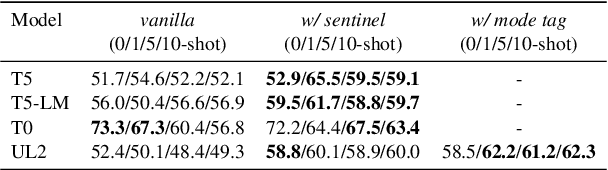

In-context learning, which offers substantial advantages over fine-tuning, is predominantly observed in decoder-only models, while encoder-decoder (i.e., seq2seq) models excel in methods that rely on weight updates. Recently, a few studies have demonstrated the feasibility of few-shot learning with seq2seq models; however, this has been limited to tasks that align well with the seq2seq architecture, such as summarization and translation. Inspired by these initial studies, we provide a first-ever extensive experiment comparing the in-context few-shot learning capabilities of decoder-only and encoder-decoder models on a broad range of tasks. Furthermore, we propose two methods to more effectively elicit in-context learning ability in seq2seq models: objective-aligned prompting and a fusion-based approach. Remarkably, our approach outperforms a decoder-only model that is six times larger and exhibits significant performance improvements compared to conventional seq2seq models across a variety of settings. We posit that, with the right configuration and prompt design, seq2seq models can be highly effective few-shot learners for a wide spectrum of applications.
Item-based Variational Auto-encoder for Fair Music Recommendation
Oct 24, 2022We present our solution for the EvalRS DataChallenge. The EvalRS DataChallenge aims to build a more realistic recommender system considering accuracy, fairness, and diversity in evaluation. Our proposed system is based on an ensemble between an item-based variational auto-encoder (VAE) and a Bayesian personalized ranking matrix factorization (BPRMF). To mitigate the bias in popularity, we use an item-based VAE for each popularity group with an additional fairness regularization. To make a reasonable recommendation even the predictions are inaccurate, we combine the recommended list of BPRMF and that of item-based VAE. Through the experiments, we demonstrate that the item-based VAE with fairness regularization significantly reduces popularity bias compared to the user-based VAE. The ensemble between the item-based VAE and BPRMF makes the top-1 item similar to the ground truth even the predictions are inaccurate. Finally, we propose a `Coefficient Variance based Fairness' as a novel evaluation metric based on our reflections from the extensive experiments.