 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Outlier-Safe Pre-Training for Robust 4-Bit Quantization of Large Language Models
Jun 24, 2025Extreme activation outliers in Large Language Models (LLMs) critically degrade quantization performance, hindering efficient on-device deployment. While channel-wise operations and adaptive gradient scaling are recognized causes, practical mitigation remains challenging. We introduce Outlier-Safe Pre-Training (OSP), a practical guideline that proactively prevents outlier formation rather than relying on post-hoc mitigation. OSP combines three key innovations: (1) the Muon optimizer, eliminating privileged bases while maintaining training efficiency; (2) Single-Scale RMSNorm, preventing channel-wise amplification; and (3) a learnable embedding projection, redistributing activation magnitudes originating from embedding matrices. We validate OSP by training a 1.4B-parameter model on 1 trillion tokens, which is the first production-scale LLM trained without such outliers. Under aggressive 4-bit quantization, our OSP model achieves a 35.7 average score across 10 benchmarks (compared to 26.5 for an Adam-trained model), with only a 2% training overhead. Remarkably, OSP models exhibit near-zero excess kurtosis (0.04) compared to extreme values (1818.56) in standard models, fundamentally altering LLM quantization behavior. Our work demonstrates that outliers are not inherent to LLMs but are consequences of training strategies, paving the way for more efficient LLM deployment. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Outlier-Safe-Pre-Training.
Rationale-Guided Retrieval Augmented Generation for Medical Question Answering
Nov 01, 2024



Large language models (LLM) hold significant potential for applications in biomedicine, but they struggle with hallucinations and outdated knowledge. While retrieval-augmented generation (RAG) is generally employed to address these issues, it also has its own set of challenges: (1) LLMs are vulnerable to irrelevant or incorrect context, (2) medical queries are often not well-targeted for helpful information, and (3) retrievers are prone to bias toward the specific source corpus they were trained on. In this study, we present RAG$^2$ (RAtionale-Guided RAG), a new framework for enhancing the reliability of RAG in biomedical contexts. RAG$^2$ incorporates three key innovations: a small filtering model trained on perplexity-based labels of rationales, which selectively augments informative snippets of documents while filtering out distractors; LLM-generated rationales as queries to improve the utility of retrieved snippets; a structure designed to retrieve snippets evenly from a comprehensive set of four biomedical corpora, effectively mitigating retriever bias. Our experiments demonstrate that RAG$^2$ improves the state-of-the-art LLMs of varying sizes, with improvements of up to 6.1\%, and it outperforms the previous best medical RAG model by up to 5.6\% across three medical question-answering benchmarks. Our code is available at https://github.com/dmis-lab/RAG2.
CompAct: Compressing Retrieved Documents Actively for Question Answering
Jul 12, 2024Retrieval-augmented generation supports language models to strengthen their factual groundings by providing external contexts. However, language models often face challenges when given extensive information, diminishing their effectiveness in solving questions. Context compression tackles this issue by filtering out irrelevant information, but current methods still struggle in realistic scenarios where crucial information cannot be captured with a single-step approach. To overcome this limitation, we introduce CompAct, a novel framework that employs an active strategy to condense extensive documents without losing key information. Our experiments demonstrate that CompAct brings significant improvements in both performance and compression rate on multi-hop question-answering (QA) benchmarks. CompAct flexibly operates as a cost-efficient plug-in module with various off-the-shelf retrievers or readers, achieving exceptionally high compression rates (47x).
OLAPH: Improving Factuality in Biomedical Long-form Question Answering
May 21, 2024

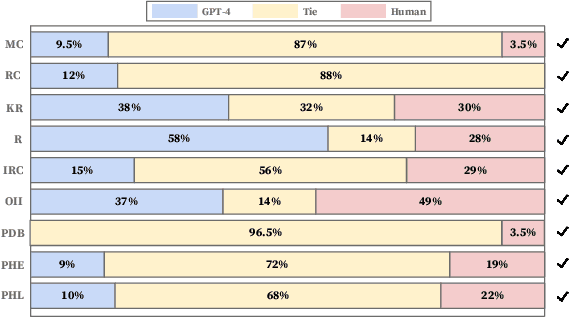

In the medical domain, numerous scenarios necessitate the long-form generation ability of large language models (LLMs). Specifically, when addressing patients' questions, it is essential that the model's response conveys factual claims, highlighting the need for an automated method to evaluate those claims. Thus, we introduce MedLFQA, a benchmark dataset reconstructed using long-form question-answering datasets related to the biomedical domain. We use MedLFQA to facilitate the automatic evaluations of factuality. We also propose OLAPH, a simple and novel framework that enables the improvement of factuality through automatic evaluations. The OLAPH framework iteratively trains LLMs to mitigate hallucinations using sampling predictions and preference optimization. In other words, we iteratively set the highest-scoring response as a preferred response derived from sampling predictions and train LLMs to align with the preferred response that improves factuality. We highlight that, even on evaluation metrics not used during training, LLMs trained with our OLAPH framework demonstrate significant performance improvement in factuality. Our findings reveal that a 7B LLM trained with our OLAPH framework can provide long answers comparable to the medical experts' answers in terms of factuality. We believe that our work could shed light on gauging the long-text generation ability of LLMs in the medical domain. Our code and datasets are available at https://github.com/dmis-lab/OLAPH}{https://github.com/dmis-lab/OLAPH.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.