 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolDeTox: Evaluating Language Model's Stepwise Fragment Editing for Molecular Detoxification
May 12, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have recently shown promising capabilities in various scientific domain. In particular, these advances have opened new opportunities in drug discovery, where the ability to understand and modify molecular structures is critical for optimizing drug properties such as efficacy and toxicity. However, existing models and benchmarks often overlook toxicity-related challenges, focusing primarily on general property optimization without adequately addressing safety concerns. In addition, even existing toxicity repair benchmarks suffer from limited data diversity, low structural validity of generated molecules, and heavy reliance on proxy models for toxicity assessment. To address these limitations, we propose MolDeTox, a novel benchmark for molecular detoxification, designed to enable fine-grained and reliable evaluation of toxicity-aware molecular optimization across stepwise tasks. We evaluate a wide range of general-purpose LLMs and VLMs under diverse settings, and demonstrate that understanding and generating molecules at the fragment-level improves structural validity and enhances the quality of generated molecules. Moreover, through detailed task-level performance analysis, MolDeTox provides an interpretable benchmark that enables a deeper understanding of the detoxification process. Our dataset is available at : https://huggingface.co/datasets/MolDeTox/MolDeTox
Benchmarking Direct Preference Optimization for Medical Large Vision-Language Models
Jan 25, 2026Large Vision-Language Models (LVLMs) hold significant promise for medical applications, yet their deployment is often constrained by insufficient alignment and reliability. While Direct Preference Optimization (DPO) has emerged as a potent framework for refining model responses, its efficacy in high-stakes medical contexts remains underexplored, lacking the rigorous empirical groundwork necessary to guide future methodological advances. To bridge this gap, we present the first comprehensive examination of diverse DPO variants within the medical domain, evaluating nine distinct formulations across two medical LVLMs: LLaVA-Med and HuatuoGPT-Vision. Our results reveal several critical limitations: current DPO approaches often yield inconsistent gains over supervised fine-tuning, with their efficacy varying significantly across different tasks and backbones. Furthermore, they frequently fail to resolve fundamental visual misinterpretation errors. Building on these insights, we present a targeted preference construction strategy as a proof-of-concept that explicitly addresses visual misinterpretation errors frequently observed in existing DPO models. This design yields a 3.6% improvement over the strongest existing DPO baseline on visual question-answering tasks. To support future research, we release our complete framework, including all training data, model checkpoints, and our codebase at https://github.com/dmis-lab/med-vlm-dpo.
Spinal Line Detection for Posture Evaluation through Train-ing-free 3D Human Body Reconstruction with 2D Depth Images
Dec 14, 2025The spinal angle is an important indicator of body balance. It is important to restore the 3D shape of the human body and estimate the spine center line. Existing mul-ti-image-based body restoration methods require expensive equipment and complex pro-cedures, and single image-based body restoration methods have limitations in that it is difficult to accurately estimate the internal structure such as the spine center line due to occlusion and viewpoint limitation. This study proposes a method to compensate for the shortcomings of the multi-image-based method and to solve the limitations of the sin-gle-image method. We propose a 3D body posture analysis system that integrates depth images from four directions to restore a 3D human model and automatically estimate the spine center line. Through hierarchical matching of global and fine registration, restora-tion to noise and occlusion is performed. Also, the Adaptive Vertex Reduction is applied to maintain the resolution and shape reliability of the mesh, and the accuracy and stabil-ity of spinal angle estimation are simultaneously secured by using the Level of Detail en-semble. The proposed method achieves high-precision 3D spine registration estimation without relying on training data or complex neural network models, and the verification confirms the improvement of matching quality.
Conditional Temporal Neural Processes with Covariance Loss
Apr 01, 2025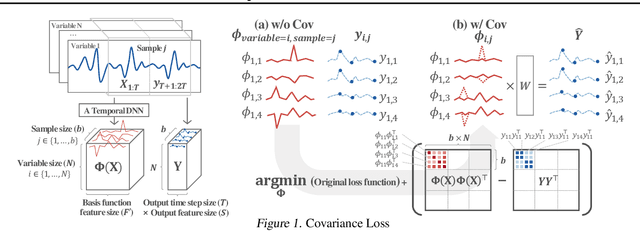



We introduce a novel loss function, Covariance Loss, which is conceptually equivalent to conditional neural processes and has a form of regularization so that is applicable to many kinds of neural networks. With the proposed loss, mappings from input variables to target variables are highly affected by dependencies of target variables as well as mean activation and mean dependencies of input and target variables. This nature enables the resulting neural networks to become more robust to noisy observations and recapture missing dependencies from prior information. In order to show the validity of the proposed loss, we conduct extensive sets of experiments on real-world datasets with state-of-the-art models and discuss the benefits and drawbacks of the proposed Covariance Loss.
* 11 pages, 18 figures
Exploring Multimodal Perception in Large Language Models Through Perceptual Strength Ratings
Mar 10, 2025This study investigated the multimodal perception of large language models (LLMs), focusing on their ability to capture human-like perceptual strength ratings across sensory modalities. Utilizing perceptual strength ratings as a benchmark, the research compared GPT-3.5, GPT-4, GPT-4o, and GPT-4o-mini, highlighting the influence of multimodal inputs on grounding and linguistic reasoning. While GPT-4 and GPT-4o demonstrated strong alignment with human evaluations and significant advancements over smaller models, qualitative analyses revealed distinct differences in processing patterns, such as multisensory overrating and reliance on loose semantic associations. Despite integrating multimodal capabilities, GPT-4o did not exhibit superior grounding compared to GPT-4, raising questions about their role in improving human-like grounding. These findings underscore how LLMs' reliance on linguistic patterns can both approximate and diverge from human embodied cognition, revealing limitations in replicating sensory experiences.
Recommendations for Comprehensive and Independent Evaluation of Machine Learning-Based Earth System Models
Oct 24, 2024Machine learning (ML) is a revolutionary technology with demonstrable applications across multiple disciplines. Within the Earth science community, ML has been most visible for weather forecasting, producing forecasts that rival modern physics-based models. Given the importance of deepening our understanding and improving predictions of the Earth system on all time scales, efforts are now underway to develop forecasting models into Earth-system models (ESMs), capable of representing all components of the coupled Earth system (or their aggregated behavior) and their response to external changes. Modeling the Earth system is a much more difficult problem than weather forecasting, not least because the model must represent the alternate (e.g., future) coupled states of the system for which there are no historical observations. Given that the physical principles that enable predictions about the response of the Earth system are often not explicitly coded in these ML-based models, demonstrating the credibility of ML-based ESMs thus requires us to build evidence of their consistency with the physical system. To this end, this paper puts forward five recommendations to enhance comprehensive, standardized, and independent evaluation of ML-based ESMs to strengthen their credibility and promote their wider use.
Learning from Negative Samples in Generative Biomedical Entity Linking
Aug 29, 2024



Generative models have become widely used in biomedical entity linking (BioEL) due to their excellent performance and efficient memory usage. However, these models are usually trained only with positive samples--entities that match the input mention's identifier--and do not explicitly learn from hard negative samples, which are entities that look similar but have different meanings. To address this limitation, we introduce ANGEL (Learning from Negative Samples in Generative Biomedical Entity Linking), the first framework that trains generative BioEL models using negative samples. Specifically, a generative model is initially trained to generate positive samples from the knowledge base for given input entities. Subsequently, both correct and incorrect outputs are gathered from the model's top-k predictions. The model is then updated to prioritize the correct predictions through direct preference optimization. Our models fine-tuned with ANGEL outperform the previous best baseline models by up to an average top-1 accuracy of 1.4% on five benchmarks. When incorporating our framework into pre-training, the performance improvement further increases to 1.7%, demonstrating its effectiveness in both the pre-training and fine-tuning stages. Our code is available at https://github.com/dmis-lab/ANGEL.
LAPIS: Language Model-Augmented Police Investigation System
Jul 31, 2024Crime situations are race against time. An AI-assisted criminal investigation system, providing prompt but precise legal counsel is in need for police officers. We introduce LAPIS (Language Model Augmented Police Investigation System), an automated system that assists police officers to perform rational and legal investigative actions. We constructed a finetuning dataset and retrieval knowledgebase specialized in crime investigation legal reasoning task. We extended the dataset's quality by incorporating manual curation efforts done by a group of domain experts. We then finetuned the pretrained weights of a smaller Korean language model to the newly constructed dataset and integrated it with the crime investigation knowledgebase retrieval approach. Experimental results show LAPIS' potential in providing reliable legal guidance for police officers, even better than the proprietary GPT-4 model. Qualitative analysis on the rationales generated by LAPIS demonstrate the model's reasoning ability to leverage the premises and derive legally correct conclusions.
MultiPragEval: Multilingual Pragmatic Evaluation of Large Language Models
Jun 11, 2024



As the capabilities of LLMs expand, it becomes increasingly important to evaluate them beyond basic knowledge assessment, focusing on higher-level language understanding. This study introduces MultiPragEval, a robust test suite designed for the multilingual pragmatic evaluation of LLMs across English, German, Korean, and Chinese. Comprising 1200 question units categorized according to Grice's Cooperative Principle and its four conversational maxims, MultiPragEval enables an in-depth assessment of LLMs' contextual awareness and their ability to infer implied meanings. Our findings demonstrate that Claude3-Opus significantly outperforms other models in all tested languages, establishing a state-of-the-art in the field. Among open-source models, Solar-10.7B and Qwen1.5-14B emerge as strong competitors. This study not only leads the way in the multilingual evaluation of LLMs in pragmatic inference but also provides valuable insights into the nuanced capabilities necessary for advanced language comprehension in AI systems.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.