 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: AI Co-Scientist for Material Research
Apr 15, 2026Large language models (LLMs) have enabled agentic AI systems for scientific discovery, but most approaches remain limited to textbased reasoning without automated experimental verification. We propose MIND, an LLM-driven framework for automated hypothesis validation in materials research. MIND organizes the scientific discovery process into hypothesis refinement, experimentation, and debate-based validation within a multi-agent pipeline. For experimental verification, the system integrates Machine Learning Interatomic Potentials, particularly SevenNet-Omni, enabling scalable in-silico experiments. We also provide a web-based user interface for automated hypothesis testing. The modular design allows additional experimental modules to be integrated, making the framework adaptable to broader scientific workflows. The code is available at: https://github.com/IMMS-Ewha/MIND, and a demonstration video at: https://youtu.be/lqiFe1OQzN4.
QUATRO: Query-Adaptive Trust Region Policy Optimization for LLM Fine-tuning
Feb 04, 2026GRPO-style reinforcement learning (RL)-based LLM fine-tuning algorithms have recently gained popularity. Relying on heuristic trust-region approximations, however, they can lead to brittle optimization behavior, as global importance-ratio clipping and group-wise normalization fail to regulate samples whose importance ratios fall outside the clipping range. We propose Query-Adaptive Trust-Region policy Optimization (QUATRO), which directly enforces trust-region constraints through a principled optimization. This yields a clear and interpretable objective that enables explicit control over policy updates and stable, entropy-controlled optimization, with a stabilizer terms arising intrinsically from the exact trust-region formulation. Empirically verified on diverse mathematical reasoning benchmarks, QUATRO shows stable training under increased policy staleness and aggressive learning rates, maintaining well-controlled entropy throughout training.
Deep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
Are Generative AI systems Capable of Supporting Information Needs of Patients?
Jan 31, 2024



Patients managing a complex illness such as cancer face a complex information challenge where they not only must learn about their illness but also how to manage it. Close interaction with healthcare experts (radiologists, oncologists) can improve patient learning and thereby, their disease outcome. However, this approach is resource intensive and takes expert time away from other critical tasks. Given the recent advancements in Generative AI models aimed at improving the healthcare system, our work investigates whether and how generative visual question answering systems can responsibly support patient information needs in the context of radiology imaging data. We conducted a formative need-finding study in which participants discussed chest computed tomography (CT) scans and associated radiology reports of a fictitious close relative with a cardiothoracic radiologist. Using thematic analysis of the conversation between participants and medical experts, we identified commonly occurring themes across interactions, including clarifying medical terminology, locating the problems mentioned in the report in the scanned image, understanding disease prognosis, discussing the next diagnostic steps, and comparing treatment options. Based on these themes, we evaluated two state-of-the-art generative visual language models against the radiologist's responses. Our results reveal variability in the quality of responses generated by the models across various themes. We highlight the importance of patient-facing generative AI systems to accommodate a diverse range of conversational themes, catering to the real-world informational needs of patients.
A Domain-Independent Agent Architecture for Adaptive Operation in Evolving Open Worlds
Jun 09, 2023



Model-based reasoning agents are ill-equipped to act in novel situations in which their model of the environment no longer sufficiently represents the world. We propose HYDRA - a framework for designing model-based agents operating in mixed discrete-continuous worlds, that can autonomously detect when the environment has evolved from its canonical setup, understand how it has evolved, and adapt the agents' models to perform effectively. HYDRA is based upon PDDL+, a rich modeling language for planning in mixed, discrete-continuous environments. It augments the planning module with visual reasoning, task selection, and action execution modules for closed-loop interaction with complex environments. HYDRA implements a novel meta-reasoning process that enables the agent to monitor its own behavior from a variety of aspects. The process employs a diverse set of computational methods to maintain expectations about the agent's own behavior in an environment. Divergences from those expectations are useful in detecting when the environment has evolved and identifying opportunities to adapt the underlying models. HYDRA builds upon ideas from diagnosis and repair and uses a heuristics-guided search over model changes such that they become competent in novel conditions. The HYDRA framework has been used to implement novelty-aware agents for three diverse domains - CartPole++ (a higher dimension variant of a classic control problem), Science Birds (an IJCAI competition problem), and PogoStick (a specific problem domain in Minecraft). We report empirical observations from these domains to demonstrate the efficacy of various components in the novelty meta-reasoning process.
HAiVA: Hybrid AI-assisted Visual Analysis Framework to Study the Effects of Cloud Properties on Climate Patterns
May 13, 2023

Clouds have a significant impact on the Earth's climate system. They play a vital role in modulating Earth's radiation budget and driving regional changes in temperature and precipitation. This makes clouds ideal for climate intervention techniques like Marine Cloud Brightening (MCB) which refers to modification in cloud reflectivity, thereby cooling the surrounding region. However, to avoid unintended effects of MCB, we need a better understanding of the complex cloud to climate response function. Designing and testing such interventions scenarios with conventional Earth System Models is computationally expensive. Therefore, we propose a hybrid AI-assisted visual analysis framework to drive such scientific studies and facilitate interactive what-if investigation of different MCB intervention scenarios to assess their intended and unintended impacts on climate patterns. We work with a team of climate scientists to develop a suite of hybrid AI models emulating cloud-climate response function and design a tightly coupled frontend interactive visual analysis system to perform different MCB intervention experiments.
Accelerating exploration of Marine Cloud Brightening impacts on tipping points Using an AI Implementation of Fluctuation-Dissipation Theorem
Feb 03, 2023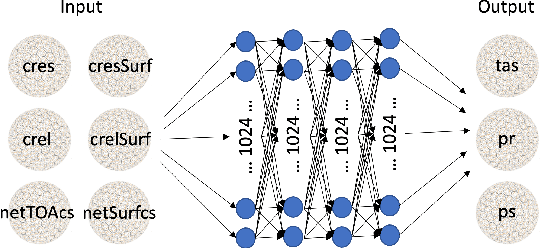

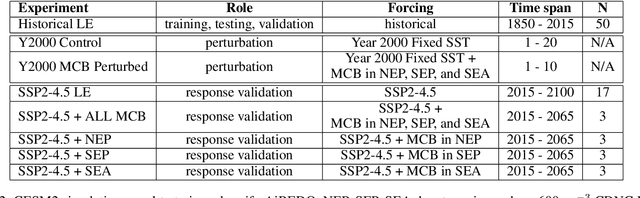
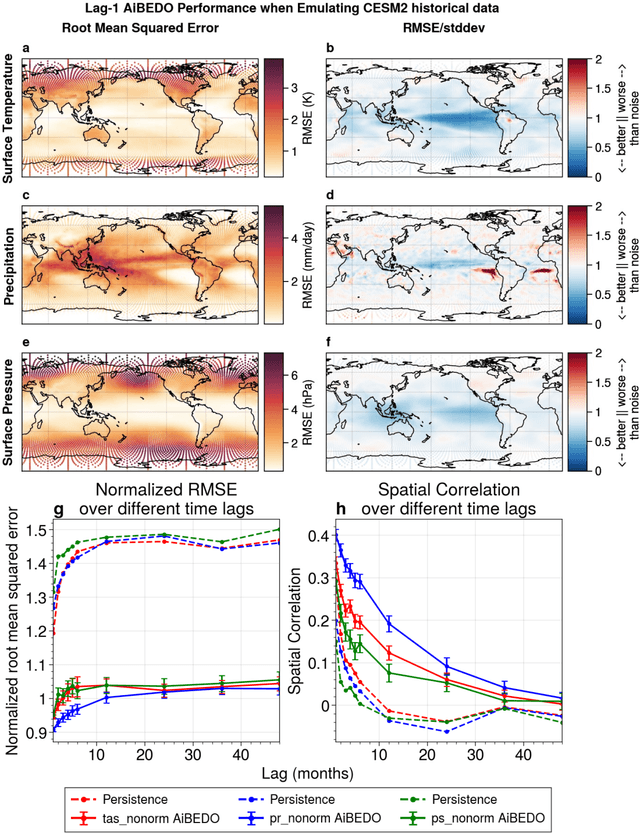
Marine cloud brightening (MCB) is a proposed climate intervention technology to partially offset greenhouse gas warming and possibly avoid crossing climate tipping points. The impacts of MCB on regional climate are typically estimated using computationally expensive Earth System Model (ESM) simulations, preventing a thorough assessment of the large possibility space of potential MCB interventions. Here, we describe an AI model, named AiBEDO, that can be used to rapidly projects climate responses to forcings via a novel application of the Fluctuation-Dissipation Theorem (FDT). AiBEDO is a Multilayer Perceptron (MLP) model that uses maps monthly-mean radiation anomalies to surface climate anomalies at a range of time lags. By leveraging a large existing dataset of ESM simulations containing internal climate noise, we use AiBEDO to construct an FDT operator that successfully projects climate responses to MCB forcing, when evaluated against ESM simulations. We propose that AiBEDO-FDT can be used to optimize MCB forcing patterns to reduce tipping point risks while minimizing negative side effects in other parts of the climate.
Continuous-Time Video Generation via Learning Motion Dynamics with Neural ODE
Dec 21, 2021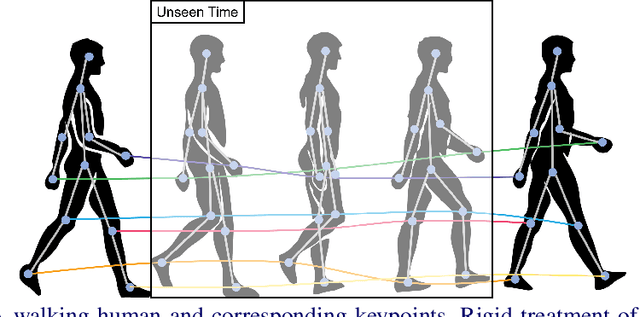
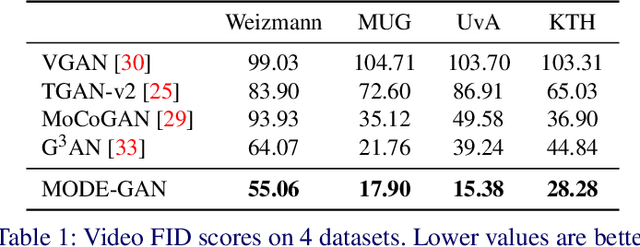
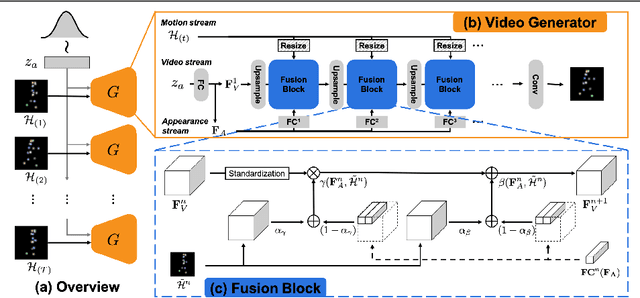

In order to perform unconditional video generation, we must learn the distribution of the real-world videos. In an effort to synthesize high-quality videos, various studies attempted to learn a mapping function between noise and videos, including recent efforts to separate motion distribution and appearance distribution. Previous methods, however, learn motion dynamics in discretized, fixed-interval timesteps, which is contrary to the continuous nature of motion of a physical body. In this paper, we propose a novel video generation approach that learns separate distributions for motion and appearance, the former modeled by neural ODE to learn natural motion dynamics. Specifically, we employ a two-stage approach where the first stage converts a noise vector to a sequence of keypoints in arbitrary frame rates, and the second stage synthesizes videos based on the given keypoints sequence and the appearance noise vector. Our model not only quantitatively outperforms recent baselines for video generation, but also demonstrates versatile functionality such as dynamic frame rate manipulation and motion transfer between two datasets, thus opening new doors to diverse video generation applications.
Vid-ODE: Continuous-Time Video Generation with Neural Ordinary Differential Equation
Oct 16, 2020
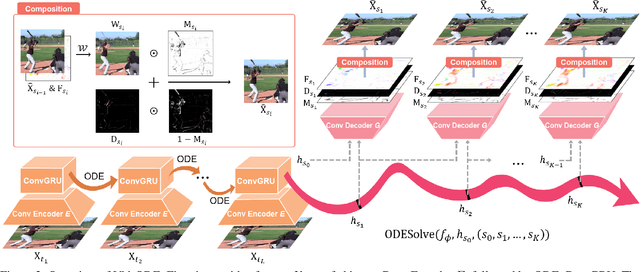
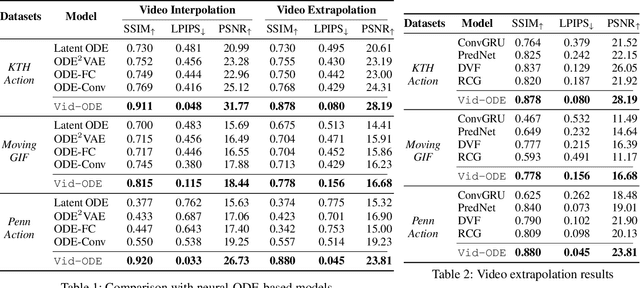

Video generation models often operate under the assumption of fixed frame rates, which leads to suboptimal performance when it comes to handling flexible frame rates (e.g., increasing the frame rate of more dynamic portion of the video as well as handling missing video frames). To resolve the restricted nature of existing video generation models' ability to handle arbitrary timesteps, we propose continuous-time video generation by combining neural ODE (Vid-ODE) with pixel-level video processing techniques. Using ODE-ConvGRU as an encoder, a convolutional version of the recently proposed neural ODE, which enables us to learn continuous-time dynamics, Vid-ODE can learn the spatio-temporal dynamics of input videos of flexible frame rates. The decoder integrates the learned dynamics function to synthesize video frames at any given timesteps, where the pixel-level composition technique is used to maintain the sharpness of individual frames. With extensive experiments on four real-world video datasets, we verify that the proposed Vid-ODE outperforms state-of-the-art approaches under various video generation settings, both within the trained time range (interpolation) and beyond the range (extrapolation). To the best of our knowledge, Vid-ODE is the first work successfully performing continuous-time video generation using real-world videos.
Deep-dust: Predicting concentrations of fine dust in Seoul using LSTM
Jan 29, 2019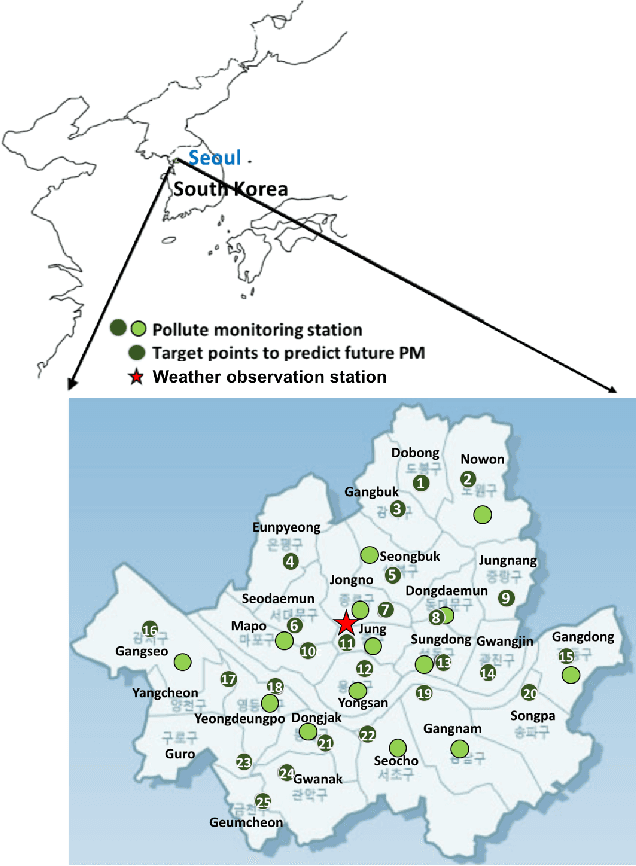
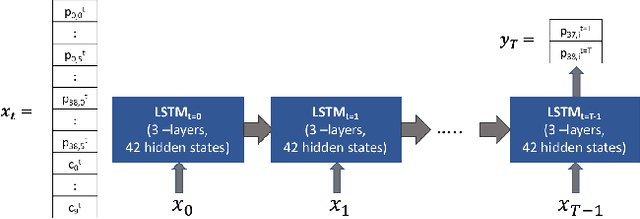
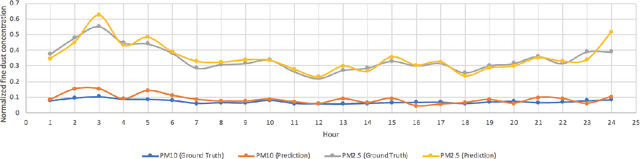

Polluting fine dusts in South Korea which are mainly consisted of biomass burning and fugitive dust blown from dust belt is significant problem these days. Predicting concentrations of fine dust particles in Seoul is challenging because they are product of complicate chemical reactions among gaseous pollutants and also influenced by dynamical interactions between pollutants and multiple climate variables. Elaborating state-of-art time series analysis techniques using deep learning, non-linear interactions between multiple variables can be captured and used to predict future dust concentration. In this work, we propose the LSTM based model to predict hourly concentration of fine dust at target location in Seoul based on previous concentration of pollutants, dust concentrations and climate variables in surrounding area. Our results show that proposed model successfully predicts future dust concentrations at 25 target districts(Gu) in Seoul.
* 3 pages, 3 figures, 1 tabel