 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Uncertainty from Deep Learning for Trustworthy Materials Discovery Workflows
Dec 02, 2020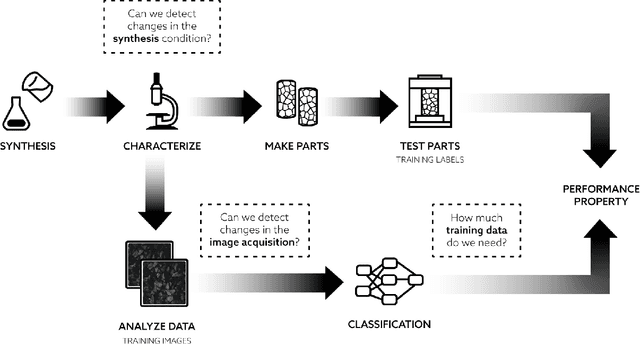


In this paper, we leverage predictive uncertainty of deep neural networks to answer challenging questions material scientists usually encounter in deep learning based materials applications workflows. First, we show that by leveraging predictive uncertainty, a user can determine the required training data set size necessary to achieve a certain classification accuracy. Next, we propose uncertainty guided decision referral to detect and refrain from making decisions on confusing samples. Finally, we show that predictive uncertainty can also be used to detect out-of-distribution test samples. We find that this scheme is accurate enough to detect a wide range of real-world shifts in data, such as changes in the image acquisition conditions or changes in the synthesis conditions. Using microstructure information from scanning electron microscope images as an example use case, we show that leveraging uncertainty-aware deep learning can significantly improve both the performance (up to 3% increase in accuracy) and the dependability (ECE reduction up to 3.5 times) of classification models.
Probabilistic Neighbourhood Component Analysis: Sample Efficient Uncertainty Estimation in Deep Learning
Jul 18, 2020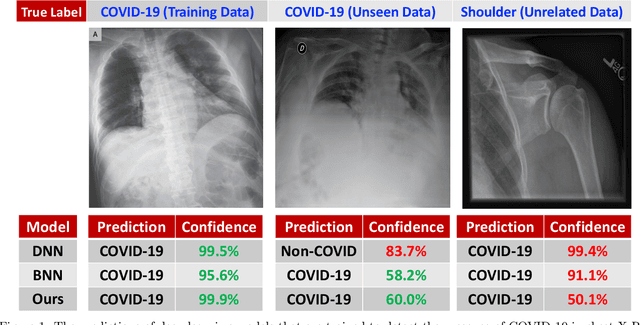

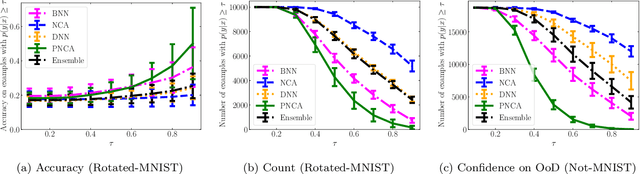
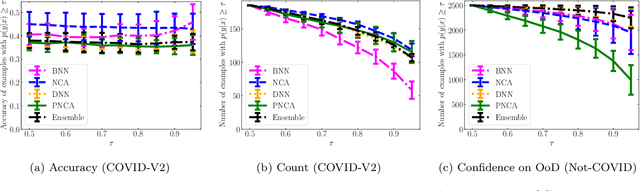
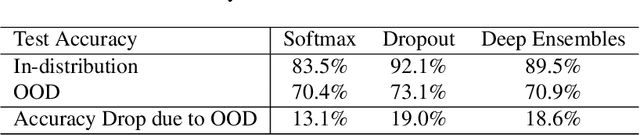
While Deep Neural Networks (DNNs) achieve state-of-the-art accuracy in various applications, they often fall short in accurately estimating their predictive uncertainty and, in turn, fail to recognize when these predictions may be wrong. Several uncertainty-aware models, such as Bayesian Neural Network (BNNs) and Deep Ensembles have been proposed in the literature for quantifying predictive uncertainty. However, research in this area has been largely confined to the big data regime. In this work, we show that the uncertainty estimation capability of state-of-the-art BNNs and Deep Ensemble models degrades significantly when the amount of training data is small. To address the issue of accurate uncertainty estimation in the small-data regime, we propose a probabilistic generalization of the popular sample-efficient non-parametric kNN approach. Our approach enables deep kNN classifier to accurately quantify underlying uncertainties in its prediction. We demonstrate the usefulness of the proposed approach by achieving superior uncertainty quantification as compared to state-of-the-art on a real-world application of COVID-19 diagnosis from chest X-Rays. Our code is available at https://github.com/ankurmallick/sample-efficient-uq
Explainable Deep Learning for Uncovering Actionable Scientific Insights for Materials Discovery and Design
Jul 16, 2020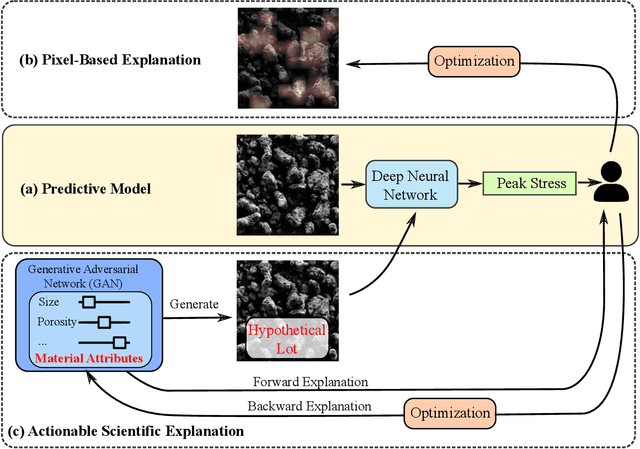


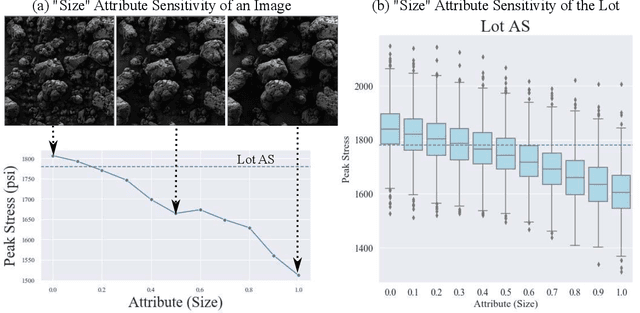
The scientific community has been increasingly interested in harnessing the power of deep learning to solve various domain challenges. However, despite the effectiveness in building predictive models, fundamental challenges exist in extracting actionable knowledge from deep neural networks due to their opaque nature. In this work, we propose techniques for exploring the behavior of deep learning models by injecting domain-specific actionable attributes as tunable "knobs" in the analysis pipeline. By incorporating the domain knowledge in a generative modeling framework, we are not only able to better understand the behavior of these black-box models, but also provide scientists with actionable insights that can potentially lead to fundamental discoveries.
Actionable Attribution Maps for Scientific Machine Learning
Jun 30, 2020

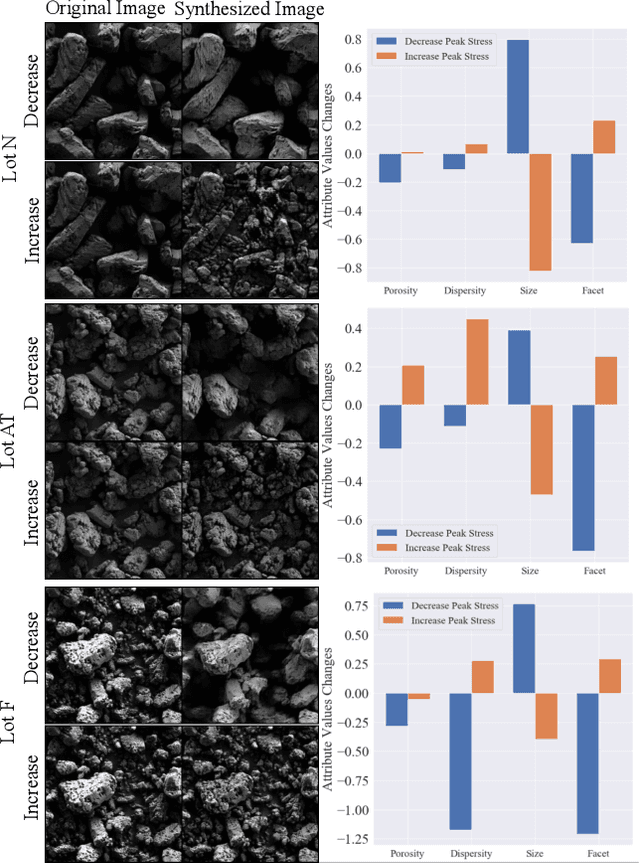
The scientific community has been increasingly interested in harnessing the power of deep learning to solve various domain challenges. However, despite the effectiveness in building predictive models, fundamental challenges exist in extracting actionable knowledge from the deep neural network due to their opaque nature. In this work, we propose techniques for exploring the behavior of deep learning models by injecting domain-specific actionable concepts as tunable ``knobs'' in the analysis pipeline. By incorporating the domain knowledge with generative modeling, we are not only able to better understand the behavior of these black-box models, but also provide scientists with actionable insights that can potentially lead to fundamental discoveries.
Mix-n-Match: Ensemble and Compositional Methods for Uncertainty Calibration in Deep Learning
Mar 16, 2020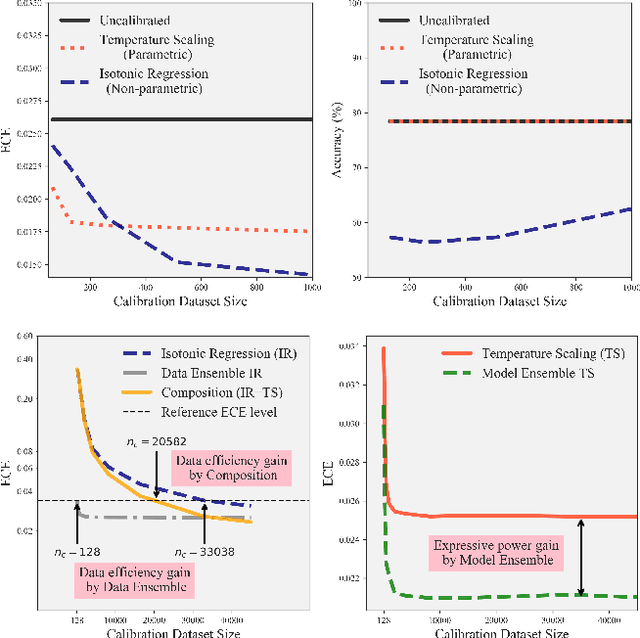
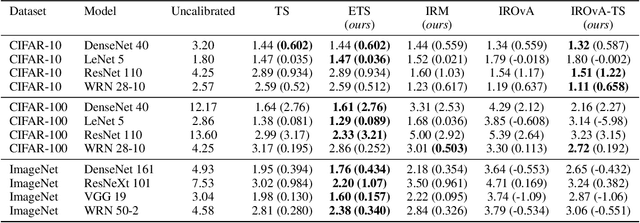
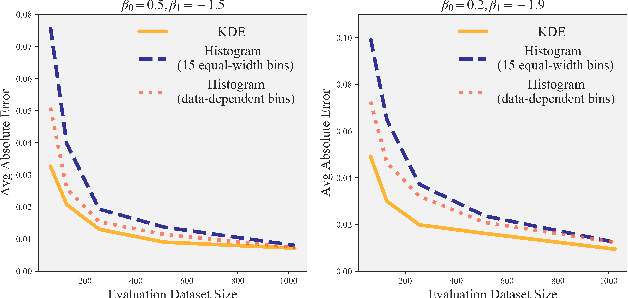
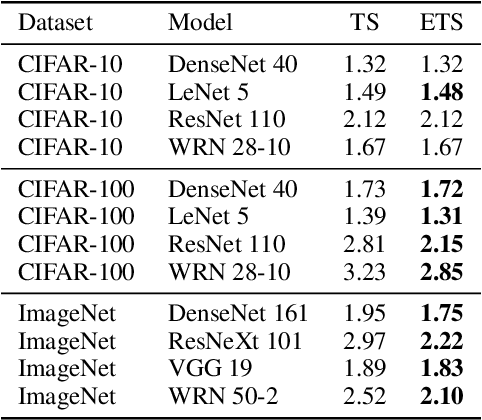
This paper studies the problem of post-hoc calibration of machine learning classifiers. We introduce the following desiderata for uncertainty calibration: (a) accuracy-preserving, (b) data-efficient, and (c) high expressive power. We show that none of the existing methods satisfy all three requirements, and demonstrate how Mix-n-Match calibration strategies (i.e., ensemble and composition) can help achieve remarkably better data-efficiency and expressive power while provably preserving classification accuracy of the original classifier. We also show that existing calibration error estimators (e.g., histogram-based ECE) are unreliable especially in small-data regime. Therefore, we propose an alternative data-efficient kernel density-based estimator for a reliable evaluation of the calibration performance and prove its asymptotically unbiasedness and consistency.
Pipelines for Procedural Information Extraction from Scientific Literature: Towards Recipes using Machine Learning and Data Science
Dec 16, 2019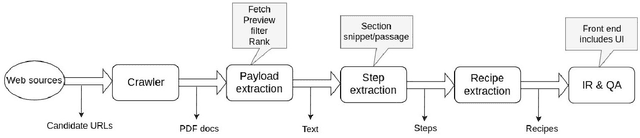
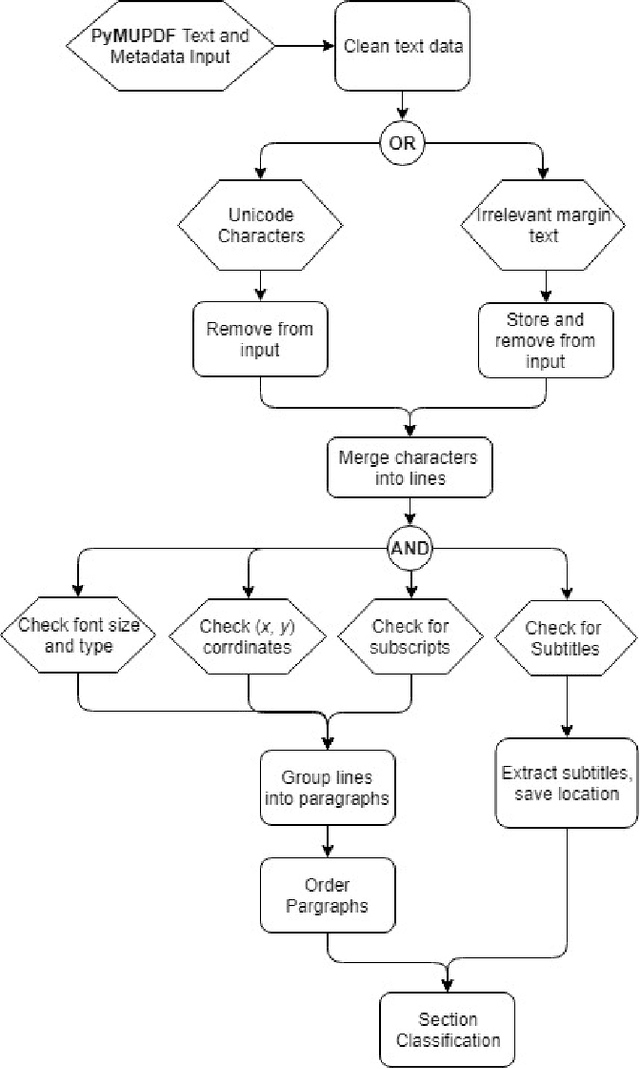
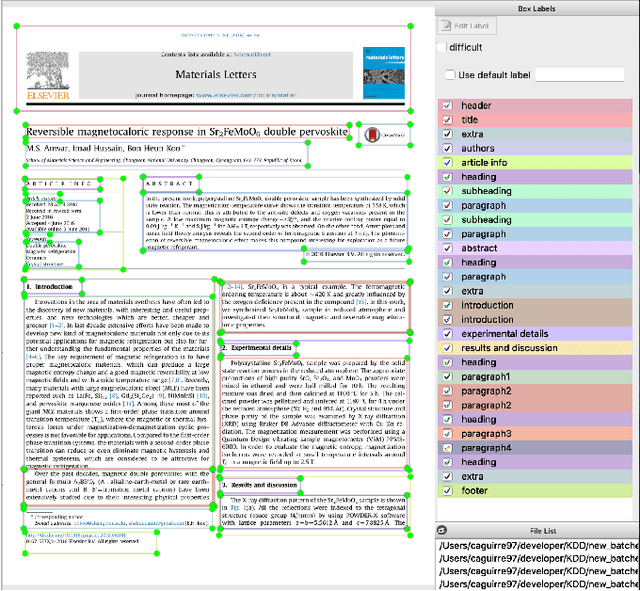

This paper describes a machine learning and data science pipeline for structured information extraction from documents, implemented as a suite of open-source tools and extensions to existing tools. It centers around a methodology for extracting procedural information in the form of recipes, stepwise procedures for creating an artifact (in this case synthesizing a nanomaterial), from published scientific literature. From our overall goal of producing recipes from free text, we derive the technical objectives of a system consisting of pipeline stages: document acquisition and filtering, payload extraction, recipe step extraction as a relationship extraction task, recipe assembly, and presentation through an information retrieval interface with question answering (QA) functionality. This system meets computational information and knowledge management (CIKM) requirements of metadata-driven payload extraction, named entity extraction, and relationship extraction from text. Functional contributions described in this paper include semi-supervised machine learning methods for PDF filtering and payload extraction tasks, followed by structured extraction and data transformation tasks beginning with section extraction, recipe steps as information tuples, and finally assembled recipes. Measurable objective criteria for extraction quality include precision and recall of recipe steps, ordering constraints, and QA accuracy, precision, and recall. Results, key novel contributions, and significant open problems derived from this work center around the attribution of these holistic quality measures to specific machine learning and inference stages of the pipeline, each with their performance measures. The desired recipes contain identified preconditions, material inputs, and operations, and constitute the overall output generated by our computational information and knowledge management (CIKM) system.
Deep Probabilistic Kernels for Sample-Efficient Learning
Oct 13, 2019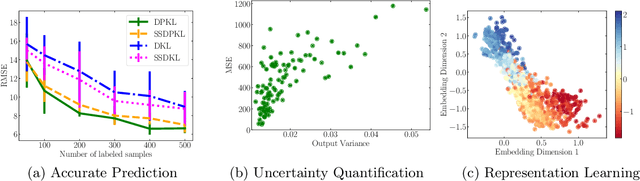
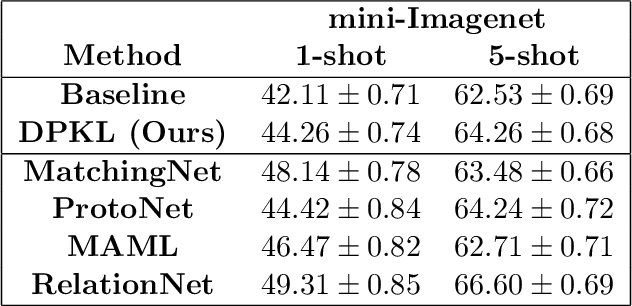
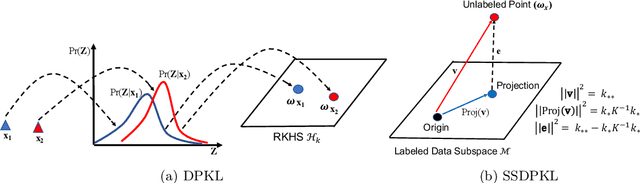
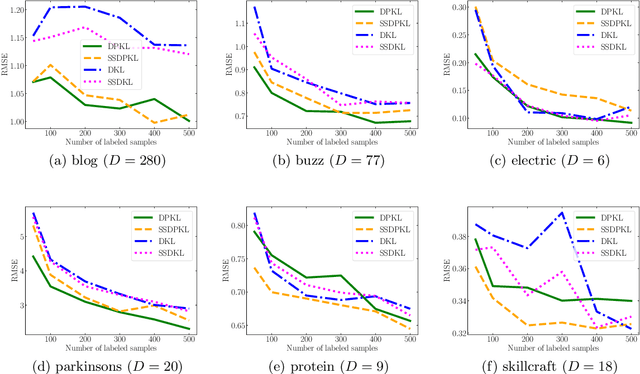
Gaussian Processes (GPs) with an appropriate kernel are known to provide accurate predictions and uncertainty estimates even with very small amounts of labeled data. However, GPs are generally unable to learn a good representation that can encode intricate structures in high dimensional data. The representation power of GPs depends heavily on kernel functions used to quantify the similarity between data points. Traditional GP kernels are not very effective at capturing similarity between high dimensional data points, while methods that use deep neural networks to learn a kernel are not sample-efficient. To overcome these drawbacks, we propose deep probabilistic kernels which use a probabilistic neural network to map high-dimensional data to a probability distribution in a low dimensional subspace, and leverage the rich work on kernels between distributions to capture the similarity between these distributions. Experiments on a variety of datasets show that building a GP using this covariance kernel solves the conflicting problems of representation learning and sample efficiency. Our model can be extended beyond GPs to other small-data paradigms such as few-shot classification where we show competitive performance with state-of-the-art models on the mini-Imagenet dataset.
Reliable and Explainable Machine Learning Methods for Accelerated Material Discovery
Jan 05, 2019
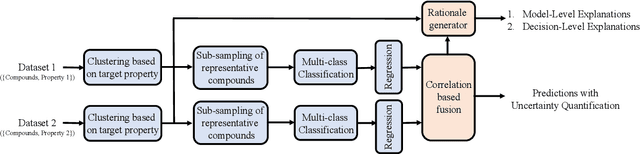
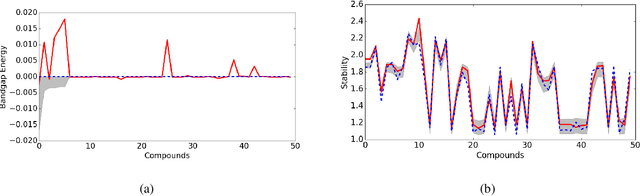
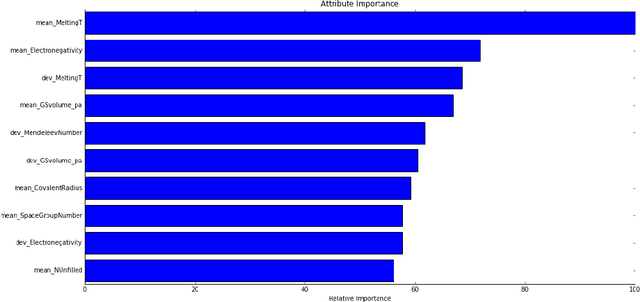
Material scientists are increasingly adopting the use of machine learning (ML) for making potentially important decisions, such as, discovery, development, optimization, synthesis and characterization of materials. However, despite ML's impressive performance in commercial applications, several unique challenges exist when applying ML in materials science applications. In such a context, the contributions of this work are twofold. First, we identify common pitfalls of existing ML techniques when learning from underrepresented/imbalanced material data. Specifically, we show that with imbalanced data, standard methods for assessing quality of ML models break down and lead to misleading conclusions. Furthermore, we found that the model's own confidence score cannot be trusted and model introspection methods (using simpler models) do not help as they result in loss of predictive performance (reliability-explainability trade-off). Second, to overcome these challenges, we propose a general-purpose explainable and reliable machine-learning framework. Specifically, we propose a novel pipeline that employs an ensemble of simpler models to reliably predict material properties. We also propose a transfer learning technique and show that the performance loss due to models' simplicity can be overcome by exploiting correlations among different material properties. A new evaluation metric and a trust score to better quantify the confidence in the predictions are also proposed. To improve the interpretability, we add a rationale generator component to our framework which provides both model-level and decision-level explanations. Finally, we demonstrate the versatility of our technique on two applications: 1) predicting properties of crystalline compounds, and 2) identifying novel potentially stable solar cell materials.