 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciVisAgentSkills: Design and Evaluation of Agent Skills for Scientific Data Analysis and Visualization
Jun 04, 2026Recent advances in agentic visualization have enabled the translation of natural language into executable scientific visualization (SciVis) workflows. While general-purpose coding agents show strong capabilities, they often lack the tool-specific expertise required for SciVis tasks. In this work, we present SciVisAgentSkills, a collection of reusable agent skills that augment coding agents for scientific data analysis and visualization by encoding environment assumptions, tool usage patterns, and domain heuristics across scientific tools such as ParaView, napari, VMD, and TTK. We evaluate these skills on Codex and Claude Code using SciVisAgentBench, a benchmark of 108 expert-designed multi-step tasks. Results show that agent skills improve mean task scores across the evaluated suites, with token-efficiency benefits that depend on the agent harness and tool setting. These findings highlight the importance of structured procedural knowledge for enabling reliable, long-horizon SciVis workflows, while also showing that skills should be studied alongside the execution harness that loads and applies them. The skills are available at https://github.com/KuangshiAi/SciVisAgentSkills.
Toward AI VIS Co-Scientists: A General and End-to-End Agent Harness for Solving Complex Data Visualization Tasks
May 20, 2026The ability to inspect, interpret, and communicate complex data is crucial for virtually any scientific endeavor, but often requires significant expertise outside the core domain ranging from data management and analysis to visualization design and implementation. We present an end-to-end agentic harness that, based on only the data and a high level description of the tasks, independently designs custom visual analysis applications (VIS apps). This represents an important step towards a general AI co-scientist envisioned by many as an autonomous system that can autonomously execute long horizon tasks based on high-level directions. Our proposed VIS co-scientist is an essential component of this broader AI co-scientist vision: a harness that can autonomously analyze data and design visualization solutions using a collection of agents and specialized skills that coordinate exploratory analysis, plan, configure the environment, implement, validate the interface, and most importantly evaluate the overall task completion. Each stage produces document and instruction artifacts that guide downstream work and enable iterative refinement. We validate this approach on IEEE SciVis Contests spanning multiple science and engineering fields. These contests serve as ideal proving grounds because they encode real-world complexity: ambiguous requirements, diverse data modalities, design trade-offs, and task-driven validation. Given only the data and target tasks, our system autonomously produces functional single-page VIS Apps with verified linked-view behavior, highly customized to domain experts' specified tasks and needs.
SciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
TopoPilot: Reliable Conversational Workflow Automation for Topological Data Analysis and Visualization
Mar 26, 2026Recent agentic systems demonstrate that large language models can generate scientific visualizations from natural language. However, reliability remains a major limitation: systems may execute invalid operations, introduce subtle but consequential errors, or fail to request missing information when inputs are underspecified. These issues are amplified in real-world workflows, which often exceed the complexity of standard benchmarks. Ensuring reliability in autonomous visualization pipelines therefore remains an open challenge. We present TopoPilot, a reliable and extensible agentic framework for automating complex scientific visualization workflows. TopoPilot incorporates systematic guardrails and verification mechanisms to ensure reliable operation. While we focus on topological data analysis and visualization as a primary use case, the framework is designed to generalize across visualization domains. TopoPilot adopts a reliability-centered two-agent architecture. An orchestrator agent translates user prompts into workflows composed of atomic backend actions, while a verifier agent evaluates these workflows prior to execution, enforcing structural validity and semantic consistency. This separation of interpretation and verification reduces code-generation errors and enforces correctness guarantees. A modular architecture further improves robustness by isolating components and enabling seamless integration of new descriptors and domain-specific workflows without modifying the core system. To systematically address reliability, we introduce a taxonomy of failure modes and implement targeted safeguards for each class. In evaluations simulating 1,000 multi-turn conversations across 100 prompts, including adversarial and infeasible requests, TopoPilot achieves a success rate exceeding 99%, compared to under 50% for baselines without comprehensive guardrails and checks.
Interpretable and Steerable Concept Bottleneck Sparse Autoencoders
Dec 11, 2025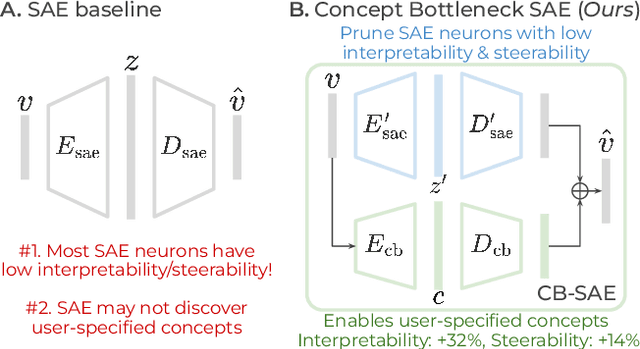



Sparse autoencoders (SAEs) promise a unified approach for mechanistic interpretability, concept discovery, and model steering in LLMs and LVLMs. However, realizing this potential requires that the learned features be both interpretable and steerable. To that end, we introduce two new computationally inexpensive interpretability and steerability metrics and conduct a systematic analysis on LVLMs. Our analysis uncovers two observations; (i) a majority of SAE neurons exhibit either low interpretability or low steerability or both, rendering them ineffective for downstream use; and (ii) due to the unsupervised nature of SAEs, user-desired concepts are often absent in the learned dictionary, thus limiting their practical utility. To address these limitations, we propose Concept Bottleneck Sparse Autoencoders (CB-SAE) - a novel post-hoc framework that prunes low-utility neurons and augments the latent space with a lightweight concept bottleneck aligned to a user-defined concept set. The resulting CB-SAE improves interpretability by +32.1% and steerability by +14.5% across LVLMs and image generation tasks. We will make our code and model weights available.
Visual Exploration of Feature Relationships in Sparse Autoencoders with Curated Concepts
Nov 08, 2025Sparse autoencoders (SAEs) have emerged as a powerful tool for uncovering interpretable features in large language models (LLMs) through the sparse directions they learn. However, the sheer number of extracted directions makes comprehensive exploration intractable. While conventional embedding techniques such as UMAP can reveal global structure, they suffer from limitations including high-dimensional compression artifacts, overplotting, and misleading neighborhood distortions. In this work, we propose a focused exploration framework that prioritizes curated concepts and their corresponding SAE features over attempts to visualize all available features simultaneously. We present an interactive visualization system that combines topology-based visual encoding with dimensionality reduction to faithfully represent both local and global relationships among selected features. This hybrid approach enables users to investigate SAE behavior through targeted, interpretable subsets, facilitating deeper and more nuanced analysis of concept representation in latent space.
An Evaluation-Centric Paradigm for Scientific Visualization Agents
Sep 18, 2025
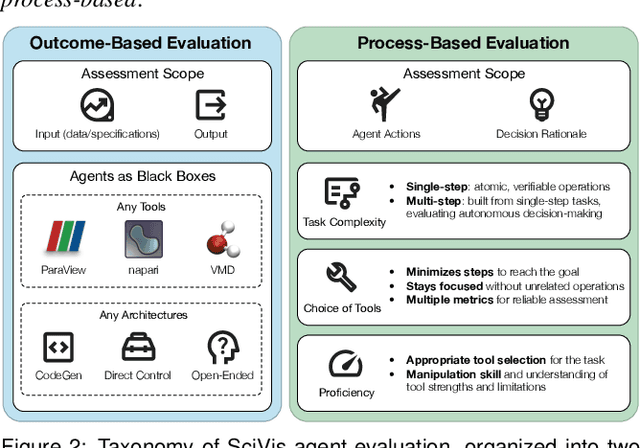
Recent advances in multi-modal large language models (MLLMs) have enabled increasingly sophisticated autonomous visualization agents capable of translating user intentions into data visualizations. However, measuring progress and comparing different agents remains challenging, particularly in scientific visualization (SciVis), due to the absence of comprehensive, large-scale benchmarks for evaluating real-world capabilities. This position paper examines the various types of evaluation required for SciVis agents, outlines the associated challenges, provides a simple proof-of-concept evaluation example, and discusses how evaluation benchmarks can facilitate agent self-improvement. We advocate for a broader collaboration to develop a SciVis agentic evaluation benchmark that would not only assess existing capabilities but also drive innovation and stimulate future development in the field.
VERIRAG: Healthcare Claim Verification via Statistical Audit in Retrieval-Augmented Generation
Jul 23, 2025Retrieval-augmented generation (RAG) systems are increasingly adopted in clinical decision support, yet they remain methodologically blind-they retrieve evidence but cannot vet its scientific quality. A paper claiming "Antioxidant proteins decreased after alloferon treatment" and a rigorous multi-laboratory replication study will be treated as equally credible, even if the former lacked scientific rigor or was even retracted. To address this challenge, we introduce VERIRAG, a framework that makes three notable contributions: (i) the Veritable, an 11-point checklist that evaluates each source for methodological rigor, including data integrity and statistical validity; (ii) a Hard-to-Vary (HV) Score, a quantitative aggregator that weights evidence by its quality and diversity; and (iii) a Dynamic Acceptance Threshold, which calibrates the required evidence based on how extraordinary a claim is. Across four datasets-comprising retracted, conflicting, comprehensive, and settled science corpora-the VERIRAG approach consistently outperforms all baselines, achieving absolute F1 scores ranging from 0.53 to 0.65, representing a 10 to 14 point improvement over the next-best method in each respective dataset. We will release all materials necessary for reproducing our results.
ParaView-MCP: An Autonomous Visualization Agent with Direct Tool Use
May 11, 2025While powerful and well-established, tools like ParaView present a steep learning curve that discourages many potential users. This work introduces ParaView-MCP, an autonomous agent that integrates modern multimodal large language models (MLLMs) with ParaView to not only lower the barrier to entry but also augment ParaView with intelligent decision support. By leveraging the state-of-the-art reasoning, command execution, and vision capabilities of MLLMs, ParaView-MCP enables users to interact with ParaView through natural language and visual inputs. Specifically, our system adopted the Model Context Protocol (MCP) - a standardized interface for model-application communication - that facilitates direct interaction between MLLMs with ParaView's Python API to allow seamless information exchange between the user, the language model, and the visualization tool itself. Furthermore, by implementing a visual feedback mechanism that allows the agent to observe the viewport, we unlock a range of new capabilities, including recreating visualizations from examples, closed-loop visualization parameter updates based on user-defined goals, and even cross-application collaboration involving multiple tools. Broadly, we believe such an agent-driven visualization paradigm can profoundly change the way we interact with visualization tools. We expect a significant uptake in the development of such visualization tools, in both visualization research and industry.
See or Recall: A Sanity Check for the Role of Vision in Solving Visualization Question Answer Tasks with Multimodal LLMs
Apr 14, 2025Recent developments in multimodal large language models (MLLM) have equipped language models to reason about vision and language jointly. This permits MLLMs to both perceive and answer questions about data visualization across a variety of designs and tasks. Applying MLLMs to a broad range of visualization tasks requires us to properly evaluate their capabilities, and the most common way to conduct evaluation is through measuring a model's visualization reasoning capability, analogous to how we would evaluate human understanding of visualizations (e.g., visualization literacy). However, we found that in the context of visualization question answering (VisQA), how an MLLM perceives and reasons about visualizations can be fundamentally different from how humans approach the same problem. During the evaluation, even without visualization, the model could correctly answer a substantial portion of the visualization test questions, regardless of whether any selection options were provided. We hypothesize that the vast amount of knowledge encoded in the language model permits factual recall that supersedes the need to seek information from the visual signal. It raises concerns that the current VisQA evaluation may not fully capture the models' visualization reasoning capabilities. To address this, we propose a comprehensive sanity check framework that integrates a rule-based decision tree and a sanity check table to disentangle the effects of "seeing" (visual processing) and "recall" (reliance on prior knowledge). This validates VisQA datasets for evaluation, highlighting where models are truly "seeing", positively or negatively affected by the factual recall, or relying on inductive biases for question answering. Our study underscores the need for careful consideration in designing future visualization understanding studies when utilizing MLLMs.