 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
Toward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
VERIRAG: Healthcare Claim Verification via Statistical Audit in Retrieval-Augmented Generation
Jul 23, 2025Retrieval-augmented generation (RAG) systems are increasingly adopted in clinical decision support, yet they remain methodologically blind-they retrieve evidence but cannot vet its scientific quality. A paper claiming "Antioxidant proteins decreased after alloferon treatment" and a rigorous multi-laboratory replication study will be treated as equally credible, even if the former lacked scientific rigor or was even retracted. To address this challenge, we introduce VERIRAG, a framework that makes three notable contributions: (i) the Veritable, an 11-point checklist that evaluates each source for methodological rigor, including data integrity and statistical validity; (ii) a Hard-to-Vary (HV) Score, a quantitative aggregator that weights evidence by its quality and diversity; and (iii) a Dynamic Acceptance Threshold, which calibrates the required evidence based on how extraordinary a claim is. Across four datasets-comprising retracted, conflicting, comprehensive, and settled science corpora-the VERIRAG approach consistently outperforms all baselines, achieving absolute F1 scores ranging from 0.53 to 0.65, representing a 10 to 14 point improvement over the next-best method in each respective dataset. We will release all materials necessary for reproducing our results.
Deep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
Enhancing Accuracy and Parameter-Efficiency of Neural Representations for Network Parameterization
Jun 29, 2024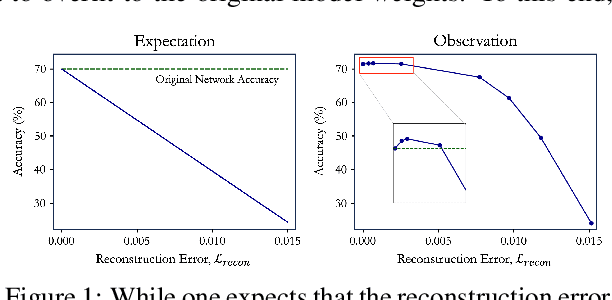
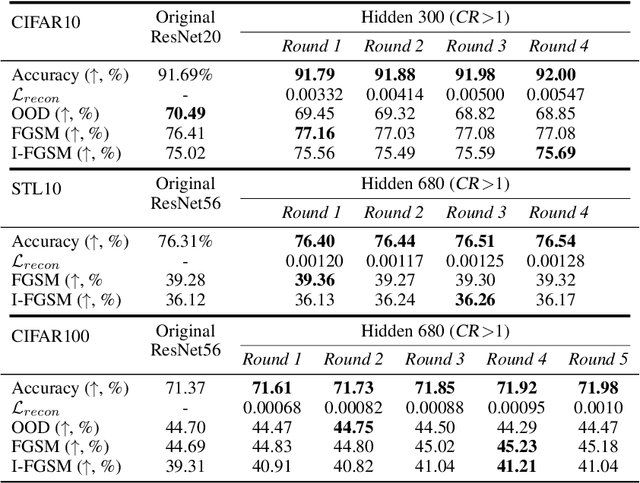
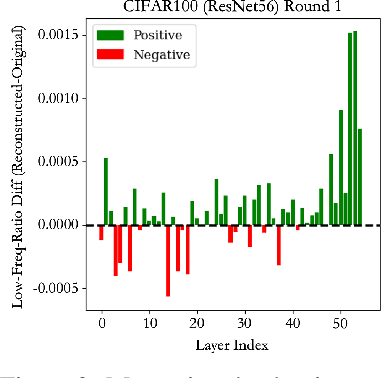
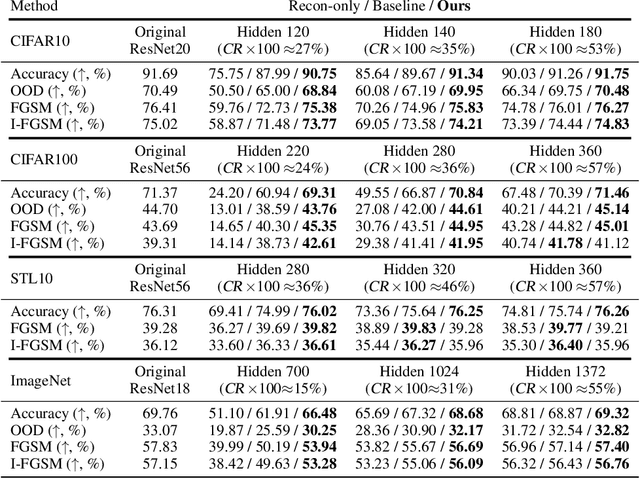
In this work, we investigate the fundamental trade-off regarding accuracy and parameter efficiency in the parameterization of neural network weights using predictor networks. We present a surprising finding that, when recovering the original model accuracy is the sole objective, it can be achieved effectively through the weight reconstruction objective alone. Additionally, we explore the underlying factors for improving weight reconstruction under parameter-efficiency constraints, and propose a novel training scheme that decouples the reconstruction objective from auxiliary objectives such as knowledge distillation that leads to significant improvements compared to state-of-the-art approaches. Finally, these results pave way for more practical scenarios, where one needs to achieve improvements on both model accuracy and predictor network parameter-efficiency simultaneously.
Topological Data Analysis Guided Segment Anything Model Prompt Optimization for Zero-Shot Segmentation in Biological Imaging
Jun 30, 2023Emerging foundation models in machine learning are models trained on vast amounts of data that have been shown to generalize well to new tasks. Often these models can be prompted with multi-modal inputs that range from natural language descriptions over images to point clouds. In this paper, we propose topological data analysis (TDA) guided prompt optimization for the Segment Anything Model (SAM) and show preliminary results in the biological image segmentation domain. Our approach replaces the standard grid search approach that is used in the original implementation and finds point locations based on their topological significance. Our results show that the TDA optimized point cloud is much better suited for finding small objects and massively reduces computational complexity despite the extra step in scenarios which require many segmentations.
Symbolic Regression via Neural-Guided Genetic Programming Population Seeding
Nov 17, 2021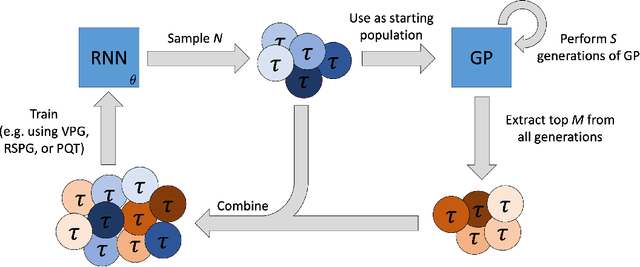

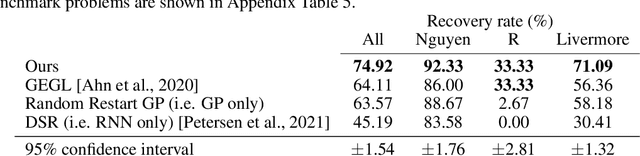
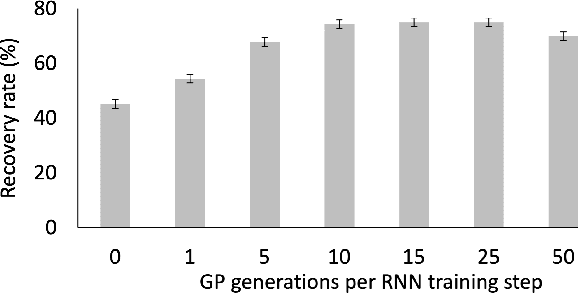
Symbolic regression is the process of identifying mathematical expressions that fit observed output from a black-box process. It is a discrete optimization problem generally believed to be NP-hard. Prior approaches to solving the problem include neural-guided search (e.g. using reinforcement learning) and genetic programming. In this work, we introduce a hybrid neural-guided/genetic programming approach to symbolic regression and other combinatorial optimization problems. We propose a neural-guided component used to seed the starting population of a random restart genetic programming component, gradually learning better starting populations. On a number of common benchmark tasks to recover underlying expressions from a dataset, our method recovers 65% more expressions than a recently published top-performing model using the same experimental setup. We demonstrate that running many genetic programming generations without interdependence on the neural-guided component performs better for symbolic regression than alternative formulations where the two are more strongly coupled. Finally, we introduce a new set of 22 symbolic regression benchmark problems with increased difficulty over existing benchmarks. Source code is provided at www.github.com/brendenpetersen/deep-symbolic-optimization.
Improving exploration in policy gradient search: Application to symbolic optimization
Jul 19, 2021
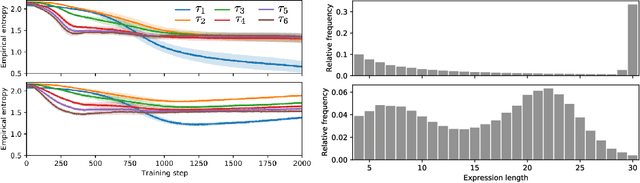
Many machine learning strategies designed to automate mathematical tasks leverage neural networks to search large combinatorial spaces of mathematical symbols. In contrast to traditional evolutionary approaches, using a neural network at the core of the search allows learning higher-level symbolic patterns, providing an informed direction to guide the search. When no labeled data is available, such networks can still be trained using reinforcement learning. However, we demonstrate that this approach can suffer from an early commitment phenomenon and from initialization bias, both of which limit exploration. We present two exploration methods to tackle these issues, building upon ideas of entropy regularization and distribution initialization. We show that these techniques can improve the performance, increase sample efficiency, and lower the complexity of solutions for the task of symbolic regression.
* Published in 1st Mathematical Reasoning in General Artificial Intelligence Workshop, ICLR 2021
Hybrid Information-driven Multi-agent Reinforcement Learning
Feb 01, 2021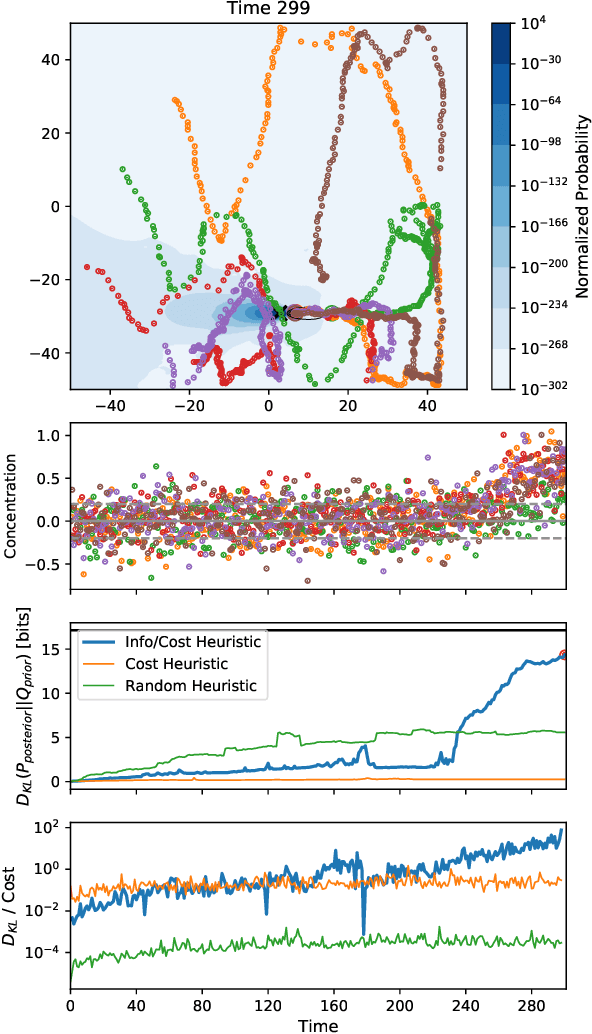

Information theoretic sensor management approaches are an ideal solution to state estimation problems when considering the optimal control of multi-agent systems, however they are too computationally intensive for large state spaces, especially when considering the limited computational resources typical of large-scale distributed multi-agent systems. Reinforcement learning (RL) is a promising alternative which can find approximate solutions to distributed optimal control problems that take into account the resource constraints inherent in many systems of distributed agents. However, the RL training can be prohibitively inefficient, especially in low-information environments where agents receive little to no feedback in large portions of the state space. We propose a hybrid information-driven multi-agent reinforcement learning (MARL) approach that utilizes information theoretic models as heuristics to help the agents navigate large sparse state spaces, coupled with information based rewards in an RL framework to learn higher-level policies. This paper presents our ongoing work towards this objective. Our preliminary findings show that such an approach can result in a system of agents that are approximately three orders of magnitude more efficient at exploring a sparse state space than naive baseline metrics. While the work is still in its early stages, it provides a promising direction for future research.