 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Reliability of Computer Use Agents
Apr 20, 2026Computer-use agents have rapidly improved on real-world tasks such as web navigation, desktop automation, and software interaction, in some cases surpassing human performance. Yet even when the task and model are unchanged, an agent that succeeds once may fail on a repeated execution of the same task. This raises a fundamental question: if an agent can succeed at a task once, what prevents it from doing so reliably? In this work, we study the sources of unreliability in computer-use agents through three factors: stochasticity during execution, ambiguity in task specification, and variability in agent behavior. We analyze these factors on OSWorld using repeated executions of the same task together with paired statistical tests that capture task-level changes across settings. Our analysis shows that reliability depends on both how tasks are specified and how agent behavior varies across executions. These findings suggest the need to evaluate agents under repeated execution, to allow agents to resolve task ambiguity through interaction, and to favor strategies that remain stable across runs.
BeautyGRPO: Aesthetic Alignment for Face Retouching via Dynamic Path Guidance and Fine-Grained Preference Modeling
Mar 01, 2026Face retouching requires removing subtle imperfections while preserving unique facial identity features, in order to enhance overall aesthetic appeal. However, existing methods suffer from a fundamental trade-off. Supervised learning on labeled data is constrained to pixel-level label mimicry, failing to capture complex subjective human aesthetic preferences. Conversely, while online reinforcement learning (RL) excels at preference alignment, its stochastic exploration paradigm conflicts with the high-fidelity demands of face retouching and often introduces noticeable noise artifacts due to accumulated stochastic drift. To address these limitations, we propose BeautyGRPO, a reinforcement learning framework that aligns face retouching with human aesthetic preferences. We construct FRPref-10K, a fine-grained preference dataset covering five key retouching dimensions, and train a specialized reward model capable of evaluating subtle perceptual differences. To reconcile exploration and fidelity, we introduce Dynamic Path Guidance (DPG). DPG stabilizes the stochastic sampling trajectory by dynamically computing an anchor-based ODE path and replanning a guided trajectory at each sampling timestep, effectively correcting stochastic drift while maintaining controlled exploration. Extensive experiments show that BeautyGRPO outperforms both specialized face retouching methods and general image editing models, achieving superior texture quality, more accurate blemish removal, and overall results that better align with human aesthetic preferences.
AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild
Feb 12, 2026Benchmarks are paramount for gauging progress in the domain of Mobile GUI Agents. In practical scenarios, users frequently fail to articulate precise directives containing full task details at the onset, and their expressions are typically ambiguous. Consequently, agents are required to converge on the user's true intent via active clarification and interaction during execution. However, existing benchmarks predominantly operate under the idealized assumption that user-issued instructions are complete and unequivocal. This paradigm focuses exclusively on assessing single-turn execution while overlooking the alignment capability of the agent. To address this limitation, we introduce AmbiBench, the first benchmark incorporating a taxonomy of instruction clarity to shift evaluation from unidirectional instruction following to bidirectional intent alignment. Grounded in Cognitive Gap theory, we propose a taxonomy of four clarity levels: Detailed, Standard, Incomplete, and Ambiguous. We construct a rigorous dataset of 240 ecologically valid tasks across 25 applications, subject to strict review protocols. Furthermore, targeting evaluation in dynamic environments, we develop MUSE (Mobile User Satisfaction Evaluator), an automated framework utilizing an MLLM-as-a-judge multi-agent architecture. MUSE performs fine-grained auditing across three dimensions: Outcome Effectiveness, Execution Quality, and Interaction Quality. Empirical results on AmbiBench reveal the performance boundaries of SoTA agents across different clarity levels, quantify the gains derived from active interaction, and validate the strong correlation between MUSE and human judgment. This work redefines evaluation standards, laying the foundation for next-generation agents capable of truly understanding user intent.
The Unreasonable Effectiveness of Scaling Agents for Computer Use
Oct 02, 2025Computer-use agents (CUAs) hold promise for automating everyday digital tasks, but their unreliability and high variance hinder their application to long-horizon, complex tasks. We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives that describe the agents' rollouts. It enables both wide exploration and principled trajectory selection, substantially improving robustness and success rates. On OSWorld, our bBoN scaling method establishes a new state of the art (SoTA) at 69.9%, significantly outperforming prior methods and approaching human-level performance at 72%, with comprehensive ablations validating key design choices. We further demonstrate strong generalization results to different operating systems on WindowsAgentArena and AndroidWorld. Crucially, our results highlight the unreasonable effectiveness of scaling CUAs, when you do it right: effective scaling requires structured trajectory understanding and selection, and bBoN provides a practical framework to achieve this.
Deep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
IIKL: Isometric Immersion Kernel Learning with Riemannian Manifold for Geometric Preservation
May 07, 2025Geometric representation learning in preserving the intrinsic geometric and topological properties for discrete non-Euclidean data is crucial in scientific applications. Previous research generally mapped non-Euclidean discrete data into Euclidean space during representation learning, which may lead to the loss of some critical geometric information. In this paper, we propose a novel Isometric Immersion Kernel Learning (IIKL) method to build Riemannian manifold and isometrically induce Riemannian metric from discrete non-Euclidean data. We prove that Isometric immersion is equivalent to the kernel function in the tangent bundle on the manifold, which explicitly guarantees the invariance of the inner product between vectors in the arbitrary tangent space throughout the learning process, thus maintaining the geometric structure of the original data. Moreover, a novel parameterized learning model based on IIKL is introduced, and an alternating training method for this model is derived using Maximum Likelihood Estimation (MLE), ensuring efficient convergence. Experimental results proved that using the learned Riemannian manifold and its metric, our model preserved the intrinsic geometric representation of data in both 3D and high-dimensional datasets successfully, and significantly improved the accuracy of downstream tasks, such as data reconstruction and classification. It is showed that our method could reduce the inner product invariant loss by more than 90% compared to state-of-the-art (SOTA) methods, also achieved an average 40% improvement in downstream reconstruction accuracy and a 90% reduction in error for geometric metrics involving isometric and conformal.
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Apr 01, 2025



Computer use agents automate digital tasks by directly interacting with graphical user interfaces (GUIs) on computers and mobile devices, offering significant potential to enhance human productivity by completing an open-ended space of user queries. However, current agents face significant challenges: imprecise grounding of GUI elements, difficulties with long-horizon task planning, and performance bottlenecks from relying on single generalist models for diverse cognitive tasks. To this end, we introduce Agent S2, a novel compositional framework that delegates cognitive responsibilities across various generalist and specialist models. We propose a novel Mixture-of-Grounding technique to achieve precise GUI localization and introduce Proactive Hierarchical Planning, dynamically refining action plans at multiple temporal scales in response to evolving observations. Evaluations demonstrate that Agent S2 establishes new state-of-the-art (SOTA) performance on three prominent computer use benchmarks. Specifically, Agent S2 achieves 18.9% and 32.7% relative improvements over leading baseline agents such as Claude Computer Use and UI-TARS on the OSWorld 15-step and 50-step evaluation. Moreover, Agent S2 generalizes effectively to other operating systems and applications, surpassing previous best methods by 52.8% on WindowsAgentArena and by 16.52% on AndroidWorld relatively. Code available at https://github.com/simular-ai/Agent-S.
DisCo-DSO: Coupling Discrete and Continuous Optimization for Efficient Generative Design in Hybrid Spaces
Dec 15, 2024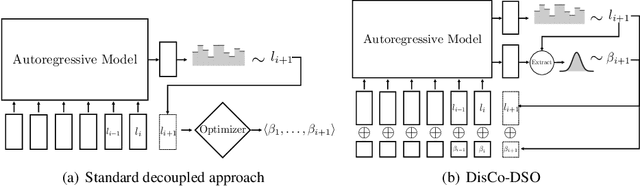
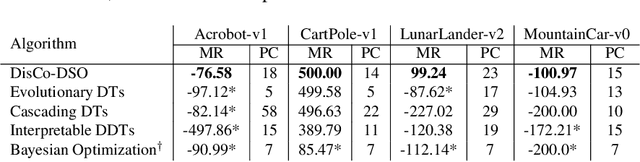
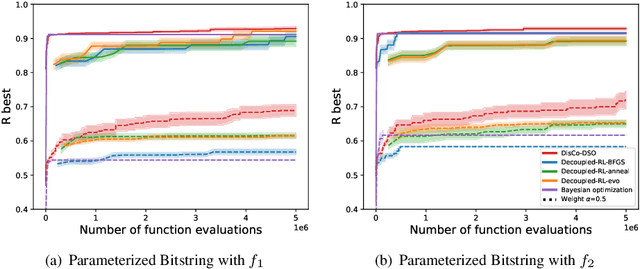
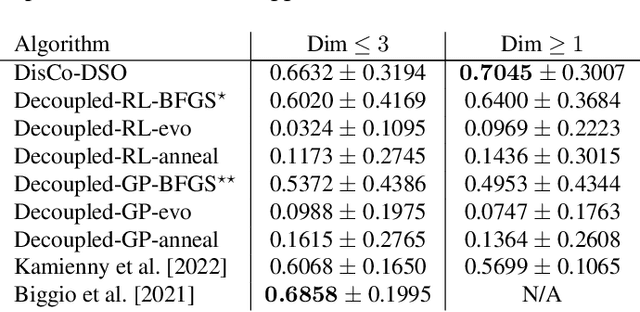
We consider the challenge of black-box optimization within hybrid discrete-continuous and variable-length spaces, a problem that arises in various applications, such as decision tree learning and symbolic regression. We propose DisCo-DSO (Discrete-Continuous Deep Symbolic Optimization), a novel approach that uses a generative model to learn a joint distribution over discrete and continuous design variables to sample new hybrid designs. In contrast to standard decoupled approaches, in which the discrete and continuous variables are optimized separately, our joint optimization approach uses fewer objective function evaluations, is robust against non-differentiable objectives, and learns from prior samples to guide the search, leading to significant improvement in performance and sample efficiency. Our experiments on a diverse set of optimization tasks demonstrate that the advantages of DisCo-DSO become increasingly evident as the complexity of the problem increases. In particular, we illustrate DisCo-DSO's superiority over the state-of-the-art methods for interpretable reinforcement learning with decision trees.
Agent S: An Open Agentic Framework that Uses Computers Like a Human
Oct 10, 2024



We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at https://github.com/simular-ai/Agent-S.
Multi-Agent Reinforcement Learning for Adaptive Mesh Refinement
Nov 04, 2022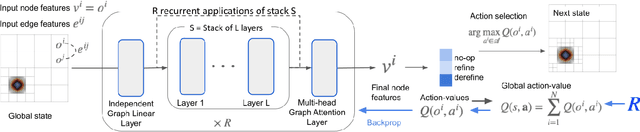
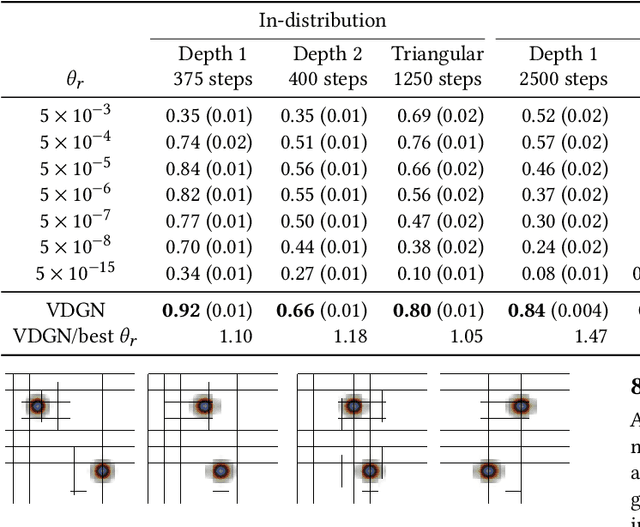
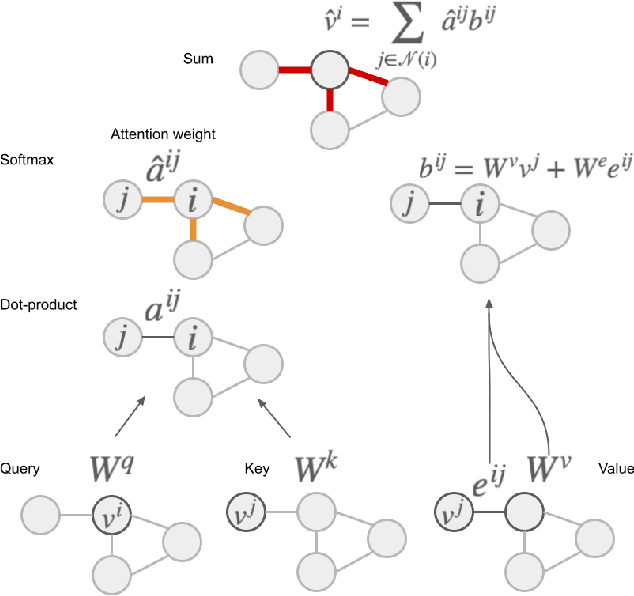
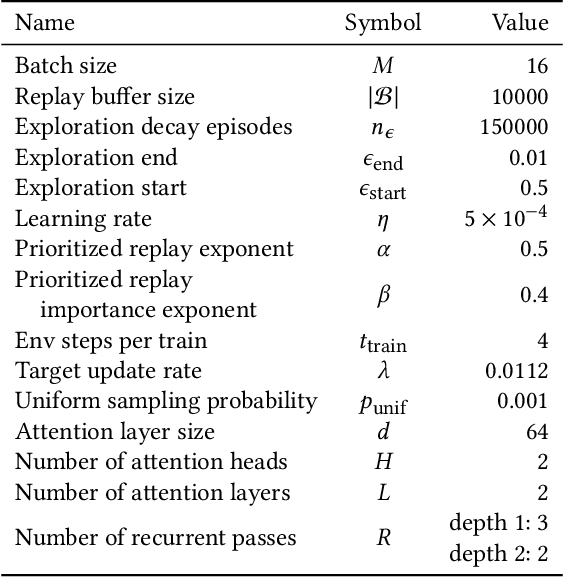
Adaptive mesh refinement (AMR) is necessary for efficient finite element simulations of complex physical phenomenon, as it allocates limited computational budget based on the need for higher or lower resolution, which varies over space and time. We present a novel formulation of AMR as a fully-cooperative Markov game, in which each element is an independent agent who makes refinement and de-refinement choices based on local information. We design a novel deep multi-agent reinforcement learning (MARL) algorithm called Value Decomposition Graph Network (VDGN), which solves the two core challenges that AMR poses for MARL: posthumous credit assignment due to agent creation and deletion, and unstructured observations due to the diversity of mesh geometries. For the first time, we show that MARL enables anticipatory refinement of regions that will encounter complex features at future times, thereby unlocking entirely new regions of the error-cost objective landscape that are inaccessible by traditional methods based on local error estimators. Comprehensive experiments show that VDGN policies significantly outperform error threshold-based policies in global error and cost metrics. We show that learned policies generalize to test problems with physical features, mesh geometries, and longer simulation times that were not seen in training. We also extend VDGN with multi-objective optimization capabilities to find the Pareto front of the tradeoff between cost and error.