 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Deep Neural Networks Always Perform Better When Eating More Data?
May 30, 2022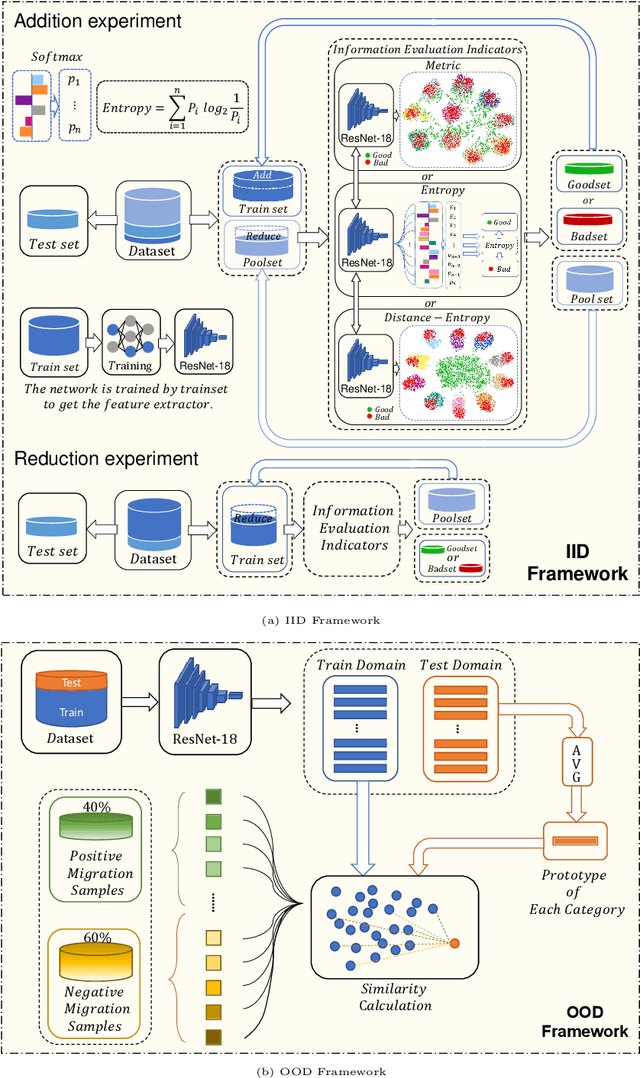
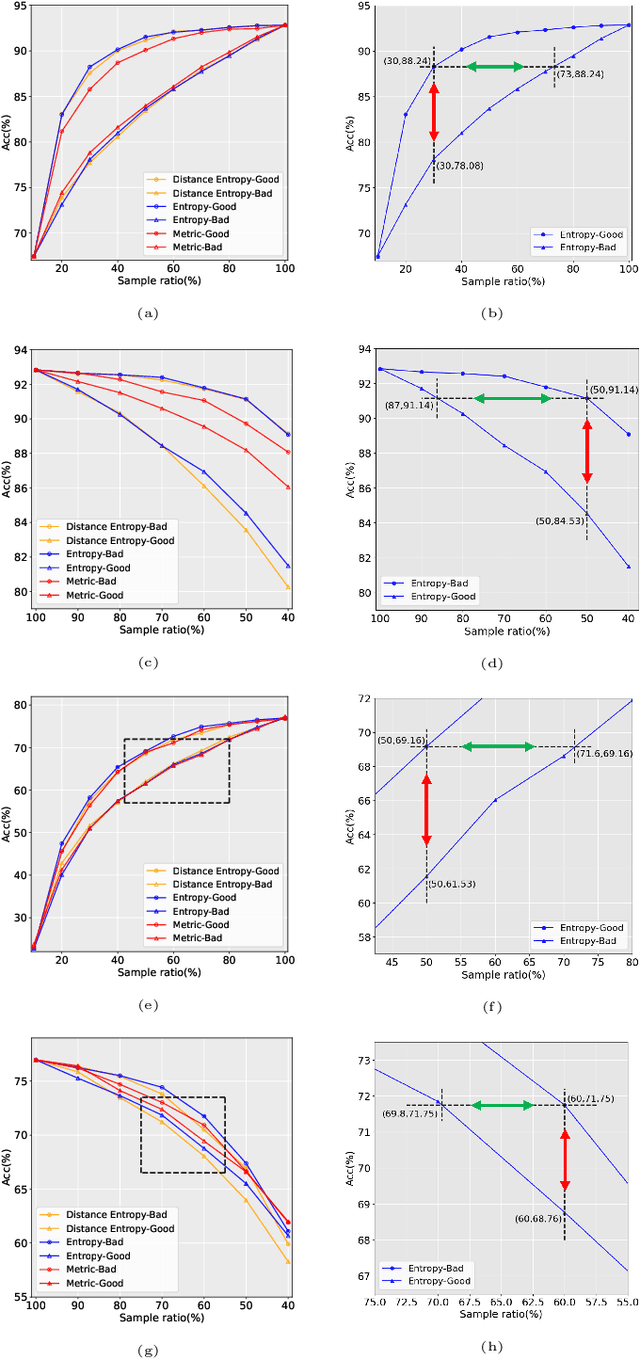
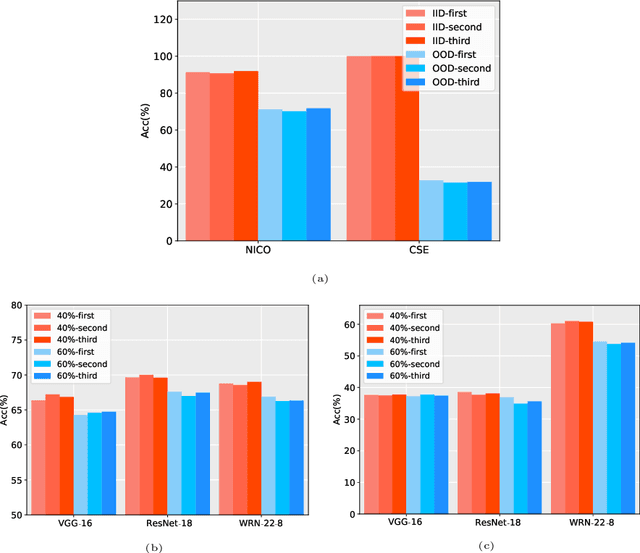
Data has now become a shortcoming of deep learning. Researchers in their own fields share the thinking that "deep neural networks might not always perform better when they eat more data," which still lacks experimental validation and a convincing guiding theory. Here to fill this lack, we design experiments from Identically Independent Distribution(IID) and Out of Distribution(OOD), which give powerful answers. For the purpose of guidance, based on the discussion of results, two theories are proposed: under IID condition, the amount of information determines the effectivity of each sample, the contribution of samples and difference between classes determine the amount of sample information and the amount of class information; under OOD condition, the cross-domain degree of samples determine the contributions, and the bias-fitting caused by irrelevant elements is a significant factor of cross-domain. The above theories provide guidance from the perspective of data, which can promote a wide range of practical applications of artificial intelligence.