 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryDocDataSet: A Benchmark for Joint Conversational Memory and Long Document Reasoning
Jun 03, 2026AI systems increasingly need to combine two demanding capabilities: navigating multi-session conversation history and performing deep reading comprehension within long documents. Yet no existing benchmark evaluates both simultaneously. We introduce MemoryDocDataSet, a synthetic benchmark of 50 micro-worlds and 1,000 QA pairs in which each instance comprises 3-5 personas, a temporal event graph spanning months of activity, 3-5 real long documents (20,000-50,000 tokens each sourced from the Caselaw Access Project), multi-session conversations grounded on those documents, and 20 question-answer pairs across five reasoning categories. The defining feature is the Hybrid source tag: questions requiring a system to first navigate conversation history to identify which document is relevant, then extract the answer from within that document. Hybrid questions account for 75.1% of the dataset. Dataset quality is characterised through a prompt-sensitivity self-consistency analysis using LLM-as-judge, yielding a median Cohen's $κ= 0.634$ across all 50 micro-worlds. We evaluate six baseline configurations spanning truncated context, long-context LLMs, retrieval-augmented generation (RAG), and memory systems. The best baseline (RAG-Both) achieves 0.358 overall F1 and 0.342 on Hybrid. Document-only retrieval (RAG-Doc) collapses to 0.267 on Hybrid despite achieving 0.453 on Doc-only questions, demonstrating a clear joint-retrieval gap that motivates architectures unifying conversational memory with long-document navigation. We release the dataset, generation pipeline, and all baseline implementations.
When Does Persona Prompting Actually Help? A Retrieval and Metric Analysis of Expert Role Injection in LLMs
May 28, 2026Persona prompting is widely used to steer large language models, yet its practical value remains unclear. Prior work often evaluates persona prompting using aggregate scores, making it difficult to determine whether expert-role prompting consistently improves response quality or instead changes responses along different quality dimensions. We study this question through a controlled comparison of four prompting conditions across 1,140 open-ended questions spanning 38 expert roles and six domains: no role prompt, a generic domain-expert prompt, embedding-based role retrieval, and a hybrid retrieval method combining embedding search with LLM-based role selection. Aggregate results show only small overall differences between conditions. However, metric-level analysis reveals a consistent tradeoff that aggregate averages obscure: role prompting systematically increases expertise depth while reducing clarity. These effects are highly conditional rather than universal. Role prompting performs best on advisory questions and in domains such as medicine and psychology, where structured expert framing and risk communication are intrinsically valuable. In contrast, baseline prompting performs better on conceptual and explanatory questions in finance, legal, science, and technology domains, where concise plain-language explanation is more important. We further show that hybrid retrieval significantly improves over embedding-only role selection, although better role retrieval does not eliminate the broader expertise-depth versus clarity tradeoff. Overall, our findings suggest that persona prompting primarily reshapes response characteristics rather than broadly improving capability, and that multi-metric evaluation is necessary for understanding its effects.
What Training Data Teaches RL Memory Agents: An Empirical Study of Curriculum Effects in Memory-Augmented QA
May 21, 2026Reinforcement learning (RL) has emerged as a viable recipe for training LLM agents to reason over external memory banks in multi-session dialogue. Existing work trains exclusively on a single benchmark, leaving open how the composition of training data shapes the skills a memory agent acquires. We present a controlled empirical study that holds architecture, RL algorithm, and all hyperparameters fixed and varies only the training curriculum across three conditions: in-domain (LoCoMo), mixed-benchmark (LoCoMo + LongMemEval), and out-of-domain (LongMemEval only). Across two benchmarks and ten question types, curriculum composition acts as a fine-grained lever on specialization rather than a uniform scaling factor on performance. The mixed curriculum yields the strongest overall F1 on both evaluation sets. Training on a narrow out-of-domain set transfers a targeted skill - temporal reasoning - despite weak aggregate performance. Per-type differences substantially exceed aggregate differences, indicating that single-number benchmark comparisons systematically underreport curriculum effects. We further report two practical lessons from adapting GRPO to a single-GPU regime: cross-benchmark mixing requires filtering format-specific noise from memory banks to preserve training signal, and binary exact-match reward produces no learning signal at the small group sizes (G = 4) required on one GPU, motivating continuous reward functions in this regime.
Improving Human Image Animation via Semantic Representation Alignment
May 11, 2026The field of image-to-video generation has made remarkable progress. However, challenges such as human limb twisting and facial distortion persist, especially when generating long videos or modeling intensive motions. Existing human image animation works address these issues by incorporating human-specific semantic representations, e.g., dense poses or ID embeddings, as additional conditions. However, conditioning on these representations could decrease the generation flexibility. Moreover, their reliance on RGB pixel supervision also lacks emphasis on learning necessary 3D geometric relationships and temporal coherence. In contrast, we introduce a novel approach named SemanticREPA that leverages these semantic representations as supervision signals through representation alignment. Specifically, we begin by training a structure alignment module that aligns the structure representations obtained from video latents with video depth estimation features. We then fix the pretrained module, and utilize it to provide additional supervision on the structure representations of the diffusion models, achieving structure rectification to generate coherent and stable human structures. Simultaneously, we develop an ID alignment module to align the ID representations of the generated videos to face recognition features. We further propose to use the predicted structure representations to refine identity restoration in relevant regions. With structure and ID alignment, our method demonstrates superior quality on extended character motions and enhanced character consistency.
TimePro: Efficient Multivariate Long-term Time Series Forecasting with Variable- and Time-Aware Hyper-state
May 27, 2025In long-term time series forecasting, different variables often influence the target variable over distinct time intervals, a challenge known as the multi-delay issue. Traditional models typically process all variables or time points uniformly, which limits their ability to capture complex variable relationships and obtain non-trivial time representations. To address this issue, we propose TimePro, an innovative Mamba-based model that constructs variate- and time-aware hyper-states. Unlike conventional approaches that merely transfer plain states across variable or time dimensions, TimePro preserves the fine-grained temporal features of each variate token and adaptively selects the focused time points to tune the plain state. The reconstructed hyper-state can perceive both variable relationships and salient temporal information, which helps the model make accurate forecasting. In experiments, TimePro performs competitively on eight real-world long-term forecasting benchmarks with satisfactory linear complexity. Code is available at https://github.com/xwmaxwma/TimePro.
MMKB-RAG: A Multi-Modal Knowledge-Based Retrieval-Augmented Generation Framework
Apr 15, 2025Recent advancements in large language models (LLMs) and multi-modal LLMs have been remarkable. However, these models still rely solely on their parametric knowledge, which limits their ability to generate up-to-date information and increases the risk of producing erroneous content. Retrieval-Augmented Generation (RAG) partially mitigates these challenges by incorporating external data sources, yet the reliance on databases and retrieval systems can introduce irrelevant or inaccurate documents, ultimately undermining both performance and reasoning quality. In this paper, we propose Multi-Modal Knowledge-Based Retrieval-Augmented Generation (MMKB-RAG), a novel multi-modal RAG framework that leverages the inherent knowledge boundaries of models to dynamically generate semantic tags for the retrieval process. This strategy enables the joint filtering of retrieved documents, retaining only the most relevant and accurate references. Extensive experiments on knowledge-based visual question-answering tasks demonstrate the efficacy of our approach: on the E-VQA dataset, our method improves performance by +4.2% on the Single-Hop subset and +0.4% on the full dataset, while on the InfoSeek dataset, it achieves gains of +7.8% on the Unseen-Q subset, +8.2% on the Unseen-E subset, and +8.1% on the full dataset. These results highlight significant enhancements in both accuracy and robustness over the current state-of-the-art MLLM and RAG frameworks.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Contrast-Unity for Partially-Supervised Temporal Sentence Grounding
Feb 18, 2025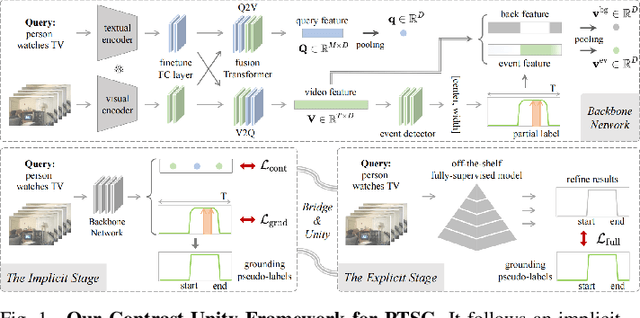
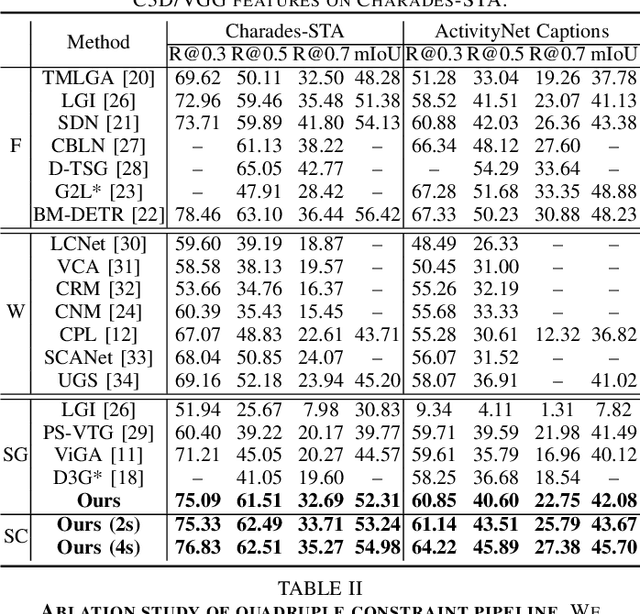
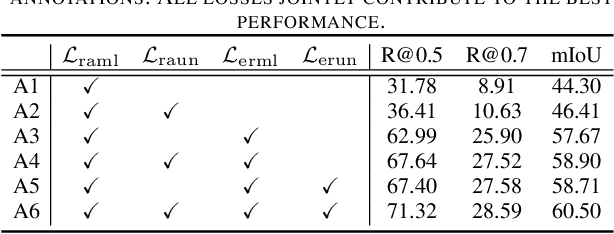
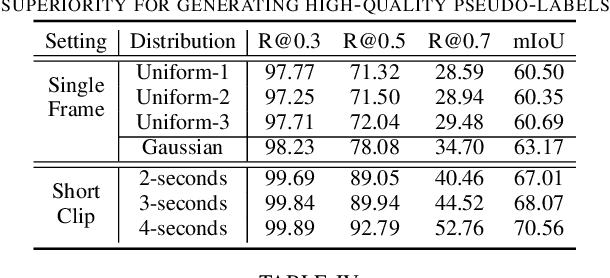
Temporal sentence grounding aims to detect event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great results but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation costs, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip is available during training. To make full use of partial labels, we specially design one contrast-unity framework, with the two-stage goal of implicit-explicit progressive grounding. In the implicit stage, we align event-query representations at fine granularity using comprehensive quadruple contrastive learning: event-query gather, event-background separation, intra-cluster compactness and inter-cluster separability. Then, high-quality representations bring acceptable grounding pseudo-labels. In the explicit stage, to explicitly optimize grounding objectives, we train one fully-supervised model using obtained pseudo-labels for grounding refinement and denoising. Extensive experiments and thoroughly ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision, as well as our superior performance.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024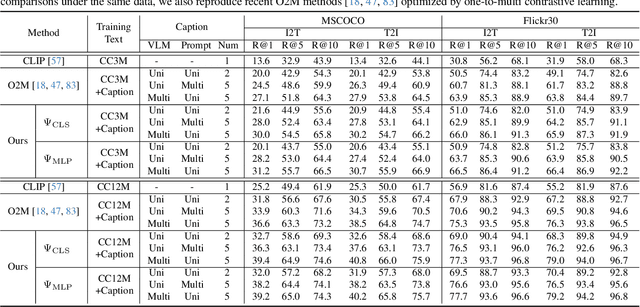
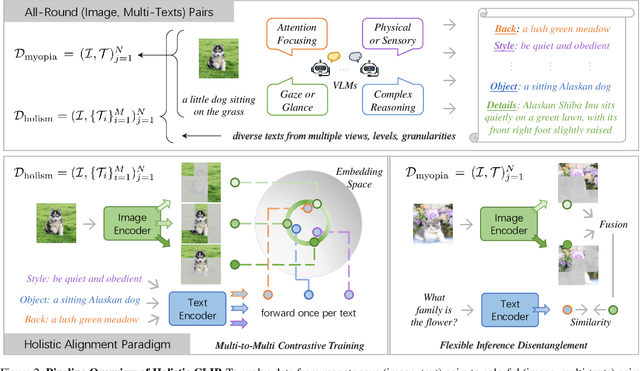
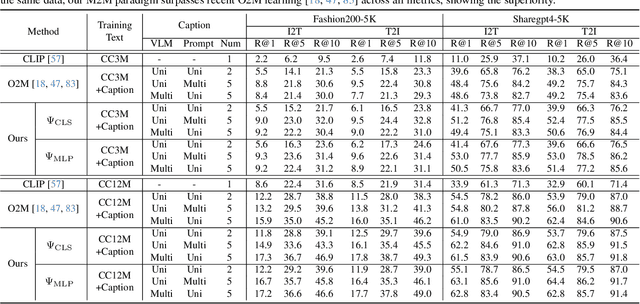
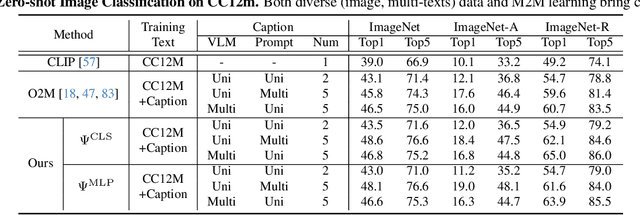
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
Branches, Assemble! Multi-Branch Cooperation Network for Large-Scale Click-Through Rate Prediction at Taobao
Nov 20, 2024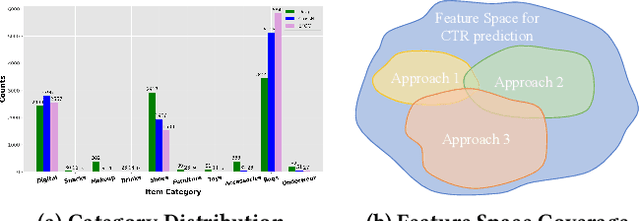
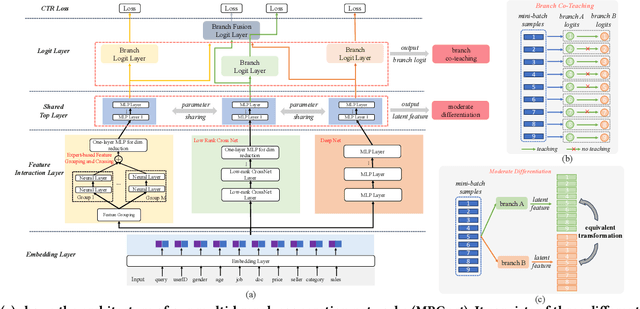

Existing click-through rate (CTR) prediction works have studied the role of feature interaction through a variety of techniques. Each interaction technique exhibits its own strength, and solely using one type could constrain the model's capability to capture the complex feature relationships, especially for industrial large-scale data with enormous users and items. Recent research shows that effective CTR models often combine an MLP network with a dedicated feature interaction network in a two-parallel structure. However, the interplay and cooperative dynamics between different streams or branches remain under-researched. In this work, we introduce a novel Multi-Branch Cooperation Network (MBCnet) which enables multiple branch networks to collaborate with each other for better complex feature interaction modeling. Specifically, MBCnet consists of three branches: the Expert-based Feature Grouping and Crossing (EFGC) branch that promotes the model's memorization ability of specific feature fields, the low rank Cross Net branch and Deep branch to enhance both explicit and implicit feature crossing for improved generalization. Among branches, a novel cooperation scheme is proposed based on two principles: branch co-teaching and moderate differentiation. Branch co-teaching encourages well-learned branches to support poorly-learned ones on specific training samples. Moderate differentiation advocates branches to maintain a reasonable level of difference in their feature representations. The cooperation strategy improves learning through mutual knowledge sharing via co-teaching and boosts the discovery of diverse feature interactions across branches. Extensive experiments on large-scale industrial datasets and online A/B test demonstrate MBCnet's superior performance, delivering a 0.09 point increase in CTR, 1.49% growth in deals, and 1.62% rise in GMV. Core codes will be released soon.