 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMask: Adapting DiT for Segmentation via Direct Mask
Mar 25, 2026Recent approaches for segmentation have leveraged pretrained generative models as feature extractors, treating segmentation as a downstream adaptation task via indirect feature retrieval. This implicit use suffers from a fundamental misalignment in representation. It also depends heavily on indirect feature extraction pipelines, which complicate the workflow and limit adaptation. In this paper, we argue that instead of indirect adaptation, segmentation tasks should be trained directly in a generative manner. We identify a key obstacle to this unified formulation: VAE latents of binary masks are sharply distributed, noise robust, and linearly separable, distinct from natural image latents. To bridge this gap, we introduce timesteps sampling strategy for binary masks that emphasizes extreme noise levels for segmentation and moderate noise for image generation, enabling harmonious joint training. We present GenMask, a DiT trains to generate black-and-white segmentation masks as well as colorful images in RGB space under the original generative objective. GenMask preserves the original DiT architecture while removing the need of feature extraction pipelines tailored for segmentation tasks. Empirically, GenMask attains state-of-the-art performance on referring and reasoning segmentation benchmarks and ablations quantify the contribution of each component.
DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Feb 13, 2026Current unified multimodal models for image generation and editing typically rely on massive parameter scales (e.g., >10B), entailing prohibitive training costs and deployment footprints. In this work, we present DeepGen 1.0, a lightweight 5B unified model that achieves comprehensive capabilities competitive with or surpassing much larger counterparts. To overcome the limitations of compact models in semantic understanding and fine-grained control, we introduce Stacked Channel Bridging (SCB), a deep alignment framework that extracts hierarchical features from multiple VLM layers and fuses them with learnable 'think tokens' to provide the generative backbone with structured, reasoning-rich guidance. We further design a data-centric training strategy spanning three progressive stages: (1) Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations, (2) Joint Supervised Fine-tuning on a high-quality mixture of generation, editing, and reasoning tasks to foster omni-capabilities, and (3) Reinforcement Learning with MR-GRPO, which leverages a mixture of reward functions and supervision signals, resulting in substantial gains in generation quality and alignment with human preferences, while maintaining stable training progress and avoiding visual artifacts. Despite being trained on only ~50M samples, DeepGen 1.0 achieves leading performance across diverse benchmarks, surpassing the 80B HunyuanImage by 28% on WISE and the 27B Qwen-Image-Edit by 37% on UniREditBench. By open-sourcing our training code, weights, and datasets, we provide an efficient, high-performance alternative to democratize unified multimodal research.
UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Editing
Feb 02, 2026Unified multimodal models often struggle with complex synthesis tasks that demand deep reasoning, and typically treat text-to-image generation and image editing as isolated capabilities rather than interconnected reasoning steps. To address this, we propose UniReason, a unified framework that harmonizes these two tasks through a dual reasoning paradigm. We formulate generation as world knowledge-enhanced planning to inject implicit constraints, and leverage editing capabilities for fine-grained visual refinement to further correct visual errors via self-reflection. This approach unifies generation and editing within a shared representation, mirroring the human cognitive process of planning followed by refinement. We support this framework by systematically constructing a large-scale reasoning-centric dataset (~300k samples) covering five major knowledge domains (e.g., cultural commonsense, physics, etc.) for planning, alongside an agent-generated corpus for visual self-correction. Extensive experiments demonstrate that UniReason achieves advanced performance on reasoning-intensive benchmarks such as WISE, KrisBench and UniREditBench, while maintaining superior general synthesis capabilities.
Unsupervised Domain Adaptation via Similarity-based Prototypes for Cross-Modality Segmentation
Oct 23, 2025Deep learning models have achieved great success on various vision challenges, but a well-trained model would face drastic performance degradation when applied to unseen data. Since the model is sensitive to domain shift, unsupervised domain adaptation attempts to reduce the domain gap and avoid costly annotation of unseen domains. This paper proposes a novel framework for cross-modality segmentation via similarity-based prototypes. In specific, we learn class-wise prototypes within an embedding space, then introduce a similarity constraint to make these prototypes representative for each semantic class while separable from different classes. Moreover, we use dictionaries to store prototypes extracted from different images, which prevents the class-missing problem and enables the contrastive learning of prototypes, and further improves performance. Extensive experiments show that our method achieves better results than other state-of-the-art methods.
Contrast-Unity for Partially-Supervised Temporal Sentence Grounding
Feb 18, 2025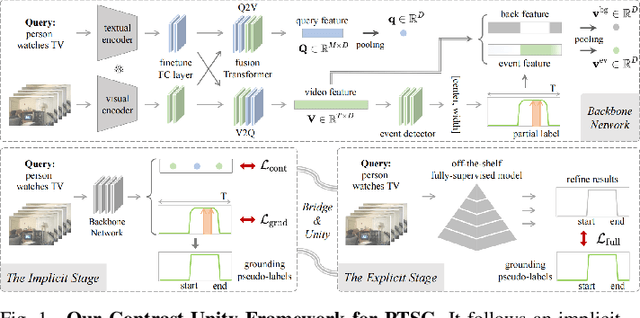
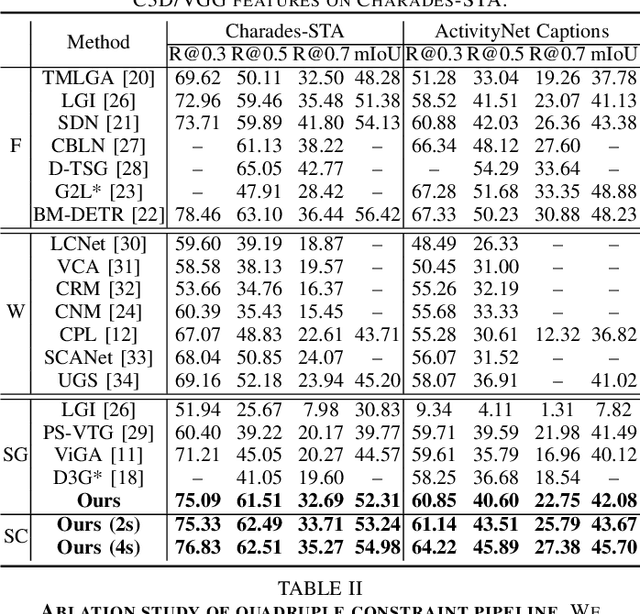
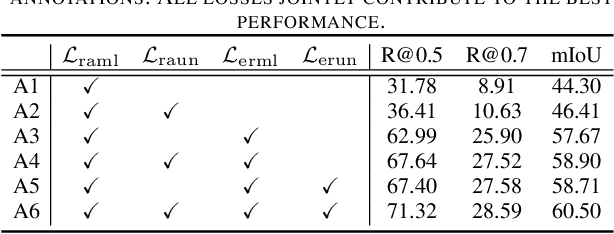
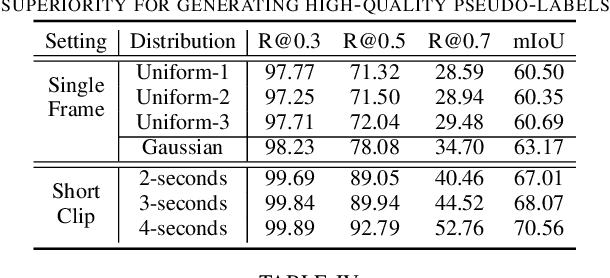
Temporal sentence grounding aims to detect event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great results but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation costs, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip is available during training. To make full use of partial labels, we specially design one contrast-unity framework, with the two-stage goal of implicit-explicit progressive grounding. In the implicit stage, we align event-query representations at fine granularity using comprehensive quadruple contrastive learning: event-query gather, event-background separation, intra-cluster compactness and inter-cluster separability. Then, high-quality representations bring acceptable grounding pseudo-labels. In the explicit stage, to explicitly optimize grounding objectives, we train one fully-supervised model using obtained pseudo-labels for grounding refinement and denoising. Extensive experiments and thoroughly ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision, as well as our superior performance.
ReMamber: Referring Image Segmentation with Mamba Twister
Mar 26, 2024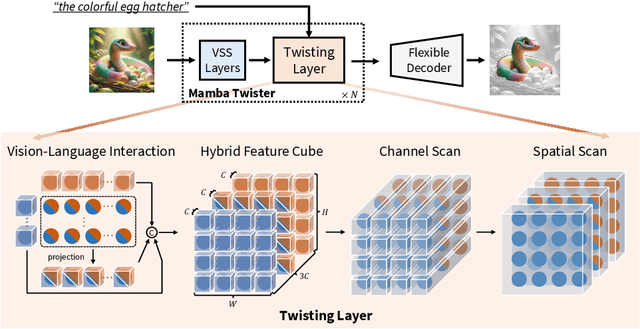
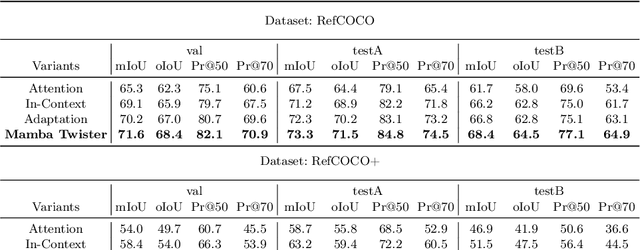
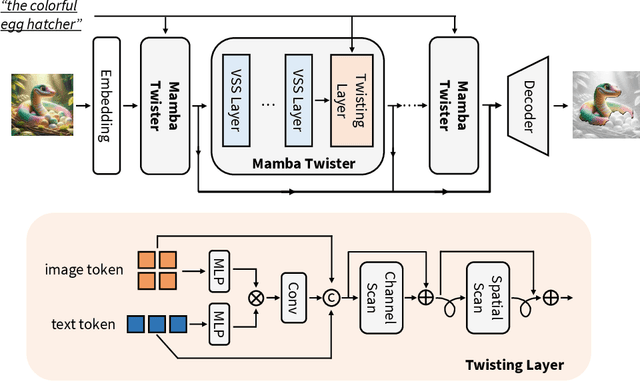
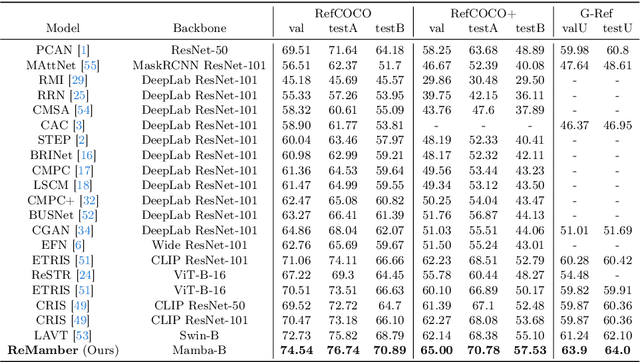
Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it resource-consuming in capturing long-range visual-language dependencies. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose ReMamber, a novel RIS architecture that integrates the power of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve the state-of-the-art on three challenging benchmarks. Moreover, we conduct thorough analyses of ReMamber and discuss other fusion designs using Mamba. These provide valuable perspectives for future research.
Uncovering Prototypical Knowledge for Weakly Open-Vocabulary Semantic Segmentation
Oct 29, 2023



This paper studies the problem of weakly open-vocabulary semantic segmentation (WOVSS), which learns to segment objects of arbitrary classes using mere image-text pairs. Existing works turn to enhance the vanilla vision transformer by introducing explicit grouping recognition, i.e., employing several group tokens/centroids to cluster the image tokens and perform the group-text alignment. Nevertheless, these methods suffer from a granularity inconsistency regarding the usage of group tokens, which are aligned in the all-to-one v.s. one-to-one manners during the training and inference phases, respectively. We argue that this discrepancy arises from the lack of elaborate supervision for each group token. To bridge this granularity gap, this paper explores explicit supervision for the group tokens from the prototypical knowledge. To this end, this paper proposes the non-learnable prototypical regularization (NPR) where non-learnable prototypes are estimated from source features to serve as supervision and enable contrastive matching of the group tokens. This regularization encourages the group tokens to segment objects with less redundancy and capture more comprehensive semantic regions, leading to increased compactness and richness. Based on NPR, we propose the prototypical guidance segmentation network (PGSeg) that incorporates multi-modal regularization by leveraging prototypical sources from both images and texts at different levels, progressively enhancing the segmentation capability with diverse prototypical patterns. Experimental results show that our proposed method achieves state-of-the-art performance on several benchmark datasets. The source code is available at https://github.com/Ferenas/PGSeg.
Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation
Aug 31, 2023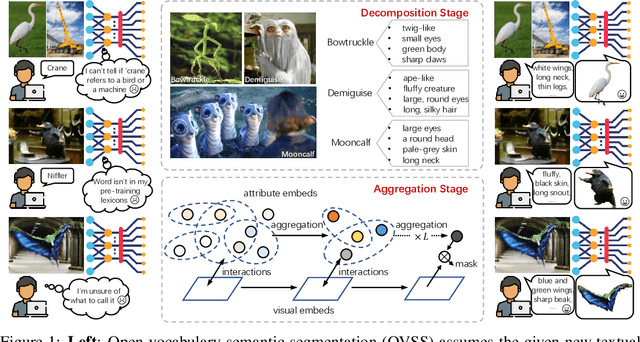


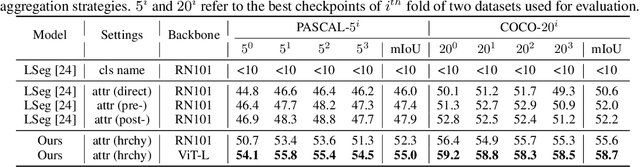
Open-vocabulary semantic segmentation is a challenging task that requires segmenting novel object categories at inference time. Recent works explore vision-language pre-training to handle this task, but suffer from unrealistic assumptions in practical scenarios, i.e., low-quality textual category names. For example, this paradigm assumes that new textual categories will be accurately and completely provided, and exist in lexicons during pre-training. However, exceptions often happen when meet with ambiguity for brief or incomplete names, new words that are not present in the pre-trained lexicons, and difficult-to-describe categories for users. To address these issues, this work proposes a novel decomposition-aggregation framework, inspired by human cognition in understanding new concepts. Specifically, in the decomposition stage, we decouple class names into diverse attribute descriptions to enrich semantic contexts. Two attribute construction strategies are designed: using large language models for common categories, and involving manually labelling for human-invented categories. In the aggregation stage, we group diverse attributes into an integrated global description, to form a discriminative classifier that distinguishes the target object from others. One hierarchical aggregation is further designed to achieve multi-level alignment and deep fusion between vision and text. The final result is obtained by computing the embedding similarity between aggregated attributes and images. To evaluate the effectiveness, we annotate three datasets with attribute descriptions, and conduct extensive experiments and ablation studies. The results show the superior performance of attribute decomposition-aggregation.
Audio-aware Query-enhanced Transformer for Audio-Visual Segmentation
Jul 25, 2023The goal of the audio-visual segmentation (AVS) task is to segment the sounding objects in the video frames using audio cues. However, current fusion-based methods have the performance limitations due to the small receptive field of convolution and inadequate fusion of audio-visual features. To overcome these issues, we propose a novel \textbf{Au}dio-aware query-enhanced \textbf{TR}ansformer (AuTR) to tackle the task. Unlike existing methods, our approach introduces a multimodal transformer architecture that enables deep fusion and aggregation of audio-visual features. Furthermore, we devise an audio-aware query-enhanced transformer decoder that explicitly helps the model focus on the segmentation of the pinpointed sounding objects based on audio signals, while disregarding silent yet salient objects. Experimental results show that our method outperforms previous methods and demonstrates better generalization ability in multi-sound and open-set scenarios.
Multi-Modal Prototypes for Open-Set Semantic Segmentation
Jul 05, 2023In semantic segmentation, adapting a visual system to novel object categories at inference time has always been both valuable and challenging. To enable such generalization, existing methods rely on either providing several support examples as visual cues or class names as textual cues. Through the development is relatively optimistic, these two lines have been studied in isolation, neglecting the complementary intrinsic of low-level visual and high-level language information. In this paper, we define a unified setting termed as open-set semantic segmentation (O3S), which aims to learn seen and unseen semantics from both visual examples and textual names. Our pipeline extracts multi-modal prototypes for segmentation task, by first single modal self-enhancement and aggregation, then multi-modal complementary fusion. To be specific, we aggregate visual features into several tokens as visual prototypes, and enhance the class name with detailed descriptions for textual prototype generation. The two modalities are then fused to generate multi-modal prototypes for final segmentation. On both \pascal and \coco datasets, we conduct extensive experiments to evaluate the framework effectiveness. State-of-the-art results are achieved even on more detailed part-segmentation, Pascal-Animals, by only training on coarse-grained datasets. Thorough ablation studies are performed to dissect each component, both quantitatively and qualitatively.