 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Paper and Code
Mar 17, 2023
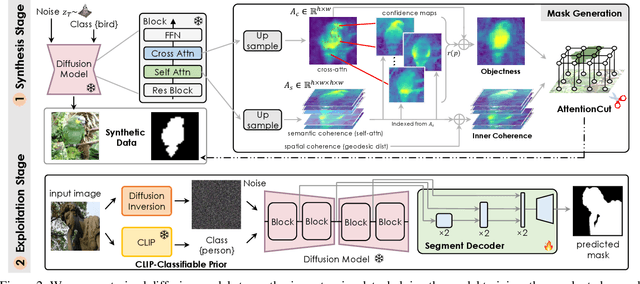


Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.