 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human Image Animation via Semantic Representation Alignment
May 11, 2026The field of image-to-video generation has made remarkable progress. However, challenges such as human limb twisting and facial distortion persist, especially when generating long videos or modeling intensive motions. Existing human image animation works address these issues by incorporating human-specific semantic representations, e.g., dense poses or ID embeddings, as additional conditions. However, conditioning on these representations could decrease the generation flexibility. Moreover, their reliance on RGB pixel supervision also lacks emphasis on learning necessary 3D geometric relationships and temporal coherence. In contrast, we introduce a novel approach named SemanticREPA that leverages these semantic representations as supervision signals through representation alignment. Specifically, we begin by training a structure alignment module that aligns the structure representations obtained from video latents with video depth estimation features. We then fix the pretrained module, and utilize it to provide additional supervision on the structure representations of the diffusion models, achieving structure rectification to generate coherent and stable human structures. Simultaneously, we develop an ID alignment module to align the ID representations of the generated videos to face recognition features. We further propose to use the predicted structure representations to refine identity restoration in relevant regions. With structure and ID alignment, our method demonstrates superior quality on extended character motions and enhanced character consistency.
Pailitao-VL: Unified Embedding and Reranker for Real-Time Multi-Modal Industrial Search
Feb 14, 2026In this work, we presented Pailitao-VL, a comprehensive multi-modal retrieval system engineered for high-precision, real-time industrial search. We here address three critical challenges in the current SOTA solution: insufficient retrieval granularity, vulnerability to environmental noise, and prohibitive efficiency-performance gap. Our primary contribution lies in two fundamental paradigm shifts. First, we transitioned the embedding paradigm from traditional contrastive learning to an absolute ID-recognition task. Through anchoring instances to a globally consistent latent space defined by billions of semantic prototypes, we successfully overcome the stochasticity and granularity bottlenecks inherent in existing embedding solutions. Second, we evolved the generative reranker from isolated pointwise evaluation to the compare-and-calibrate listwise policy. By synergizing chunk-based comparative reasoning with calibrated absolute relevance scoring, the system achieves nuanced discriminative resolution while circumventing the prohibitive latency typically associated with conventional reranking methods. Extensive offline benchmarks and online A/B tests on Alibaba e-commerce platform confirm that Pailitao-VL achieves state-of-the-art performance and delivers substantial business impact. This work demonstrates a robust and scalable path for deploying advanced MLLM-based retrieval architectures in demanding, large-scale production environments.
Unsupervised Domain Adaptation via Similarity-based Prototypes for Cross-Modality Segmentation
Oct 23, 2025Deep learning models have achieved great success on various vision challenges, but a well-trained model would face drastic performance degradation when applied to unseen data. Since the model is sensitive to domain shift, unsupervised domain adaptation attempts to reduce the domain gap and avoid costly annotation of unseen domains. This paper proposes a novel framework for cross-modality segmentation via similarity-based prototypes. In specific, we learn class-wise prototypes within an embedding space, then introduce a similarity constraint to make these prototypes representative for each semantic class while separable from different classes. Moreover, we use dictionaries to store prototypes extracted from different images, which prevents the class-missing problem and enables the contrastive learning of prototypes, and further improves performance. Extensive experiments show that our method achieves better results than other state-of-the-art methods.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Contrast-Unity for Partially-Supervised Temporal Sentence Grounding
Feb 18, 2025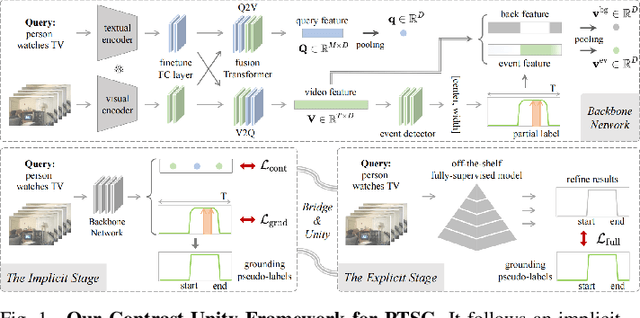
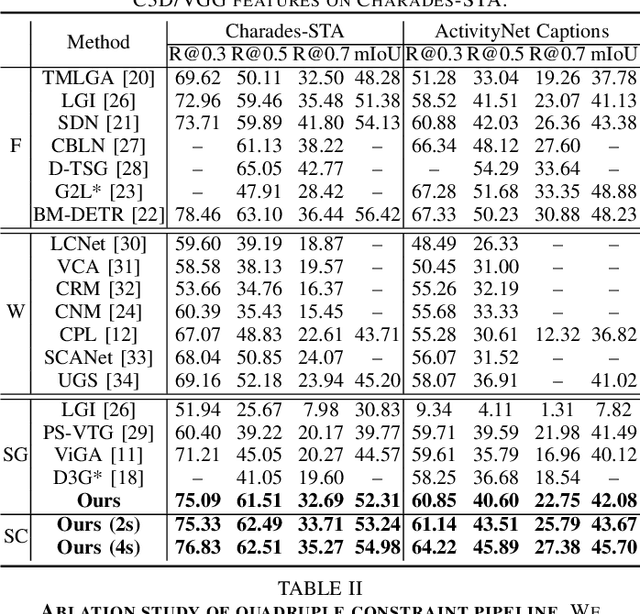
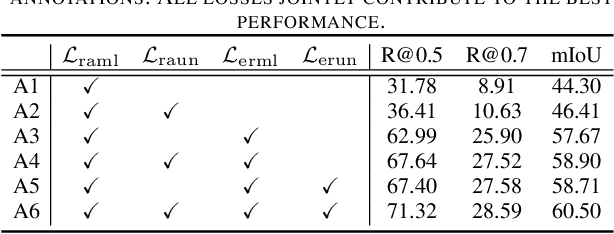
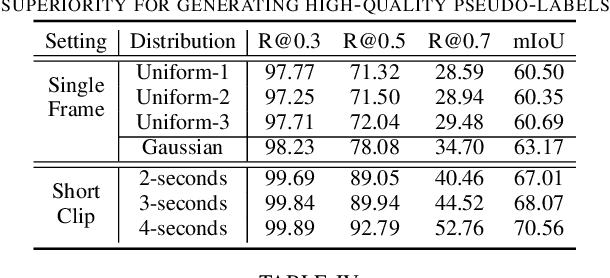
Temporal sentence grounding aims to detect event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great results but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation costs, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip is available during training. To make full use of partial labels, we specially design one contrast-unity framework, with the two-stage goal of implicit-explicit progressive grounding. In the implicit stage, we align event-query representations at fine granularity using comprehensive quadruple contrastive learning: event-query gather, event-background separation, intra-cluster compactness and inter-cluster separability. Then, high-quality representations bring acceptable grounding pseudo-labels. In the explicit stage, to explicitly optimize grounding objectives, we train one fully-supervised model using obtained pseudo-labels for grounding refinement and denoising. Extensive experiments and thoroughly ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision, as well as our superior performance.
FOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
Jan 05, 2025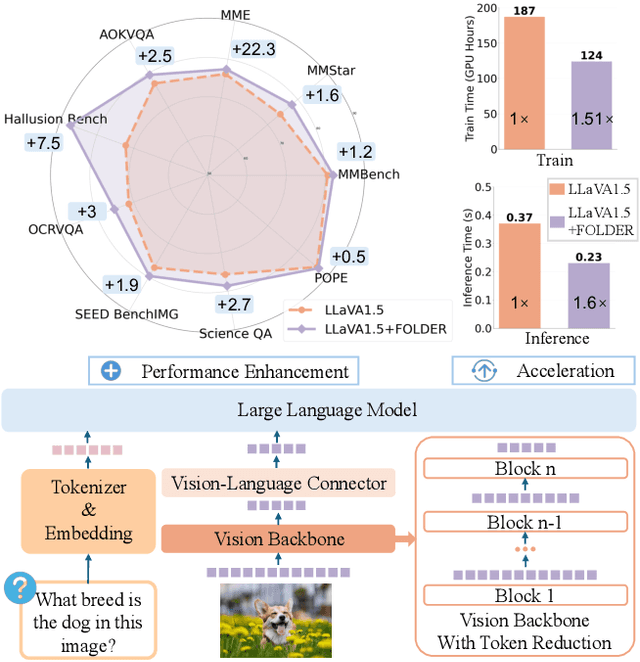
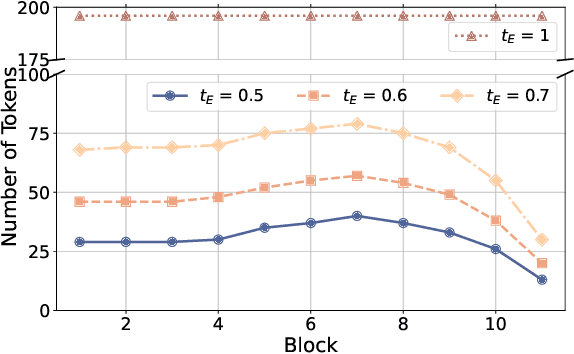
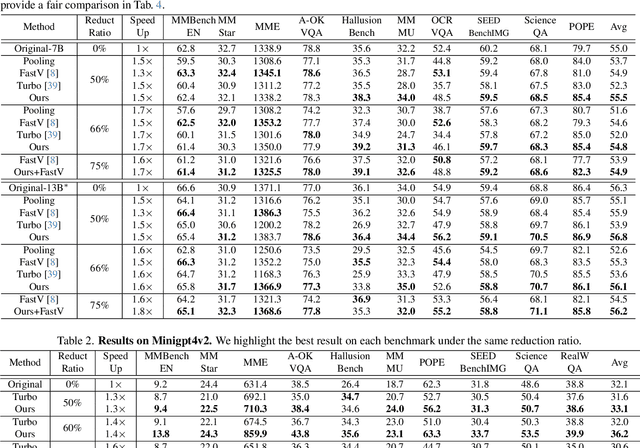
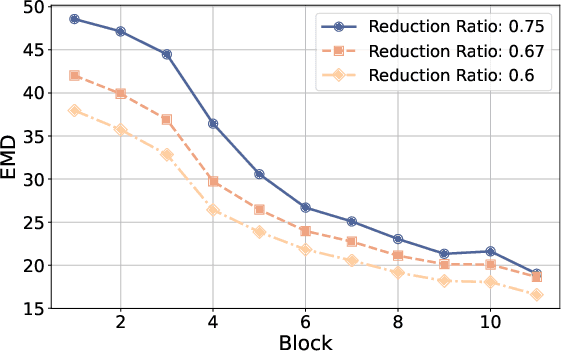
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024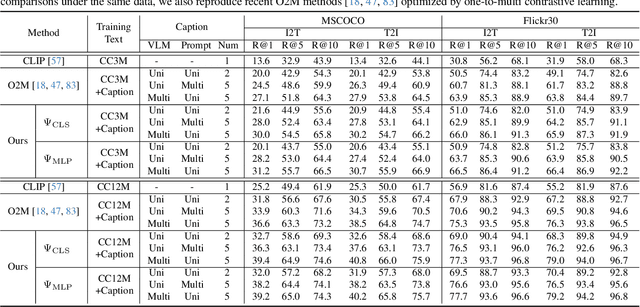
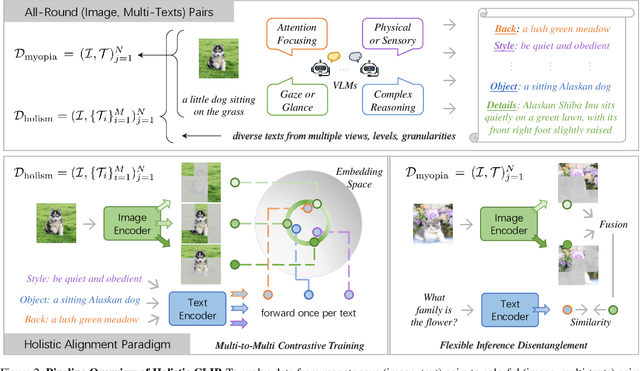
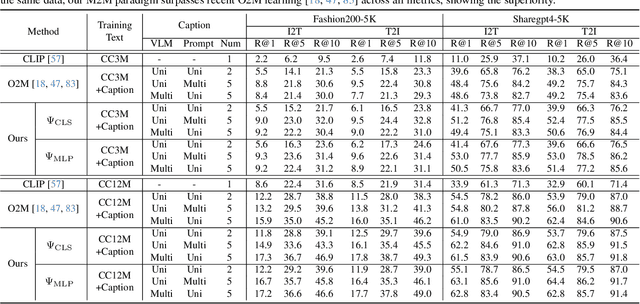
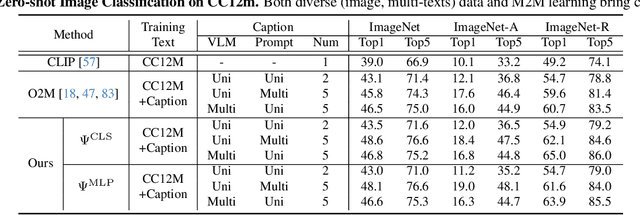
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
Cell Variational Information Bottleneck Network
Mar 29, 2024
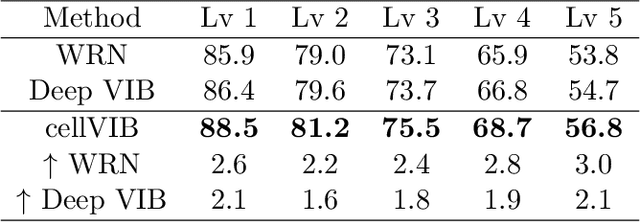

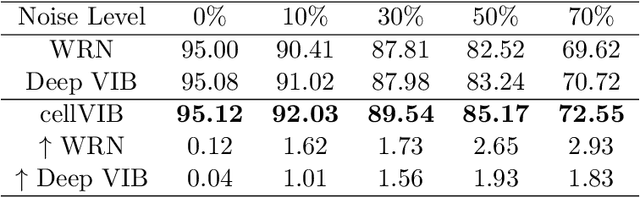
In this work, we propose Cell Variational Information Bottleneck Network (cellVIB), a convolutional neural network using information bottleneck mechanism, which can be combined with the latest feedforward network architecture in an end-to-end training method. Our Cell Variational Information Bottleneck Network is constructed by stacking VIB cells, which generate feature maps with uncertainty. As layers going deeper, the regularization effect will gradually increase, instead of directly adding excessive regular constraints to the output layer of the model as in Deep VIB. Under each VIB cell, the feedforward process learns an independent mean term and an standard deviation term, and predicts the Gaussian distribution based on them. The feedback process is based on reparameterization trick for effective training. This work performs an extensive analysis on MNIST dataset to verify the effectiveness of each VIB cells, and provides an insightful analysis on how the VIB cells affect mutual information. Experiments conducted on CIFAR-10 also prove that our cellVIB is robust against noisy labels during training and against corrupted images during testing. Then, we validate our method on PACS dataset, whose results show that the VIB cells can significantly improve the generalization performance of the basic model. Finally, in a more complex representation learning task, face recognition, our network structure has also achieved very competitive results.
Wear-Any-Way: Manipulable Virtual Try-on via Sparse Correspondence Alignment
Mar 19, 2024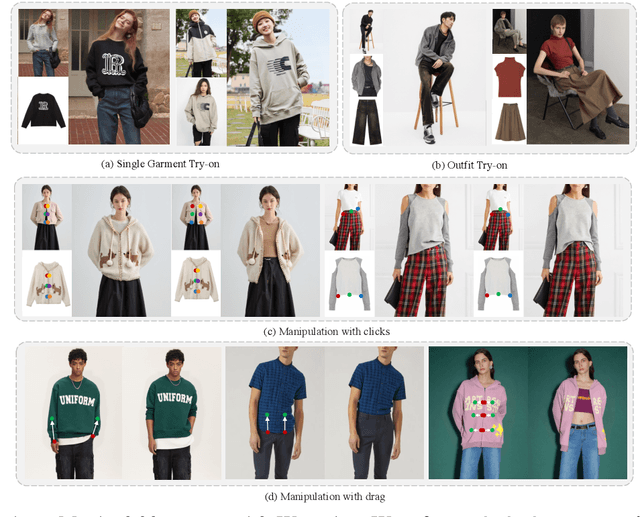

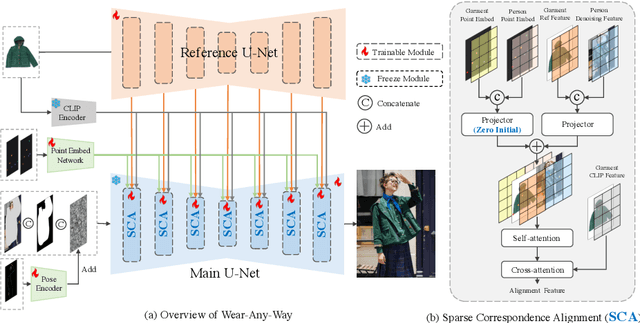
This paper introduces a novel framework for virtual try-on, termed Wear-Any-Way. Different from previous methods, Wear-Any-Way is a customizable solution. Besides generating high-fidelity results, our method supports users to precisely manipulate the wearing style. To achieve this goal, we first construct a strong pipeline for standard virtual try-on, supporting single/multiple garment try-on and model-to-model settings in complicated scenarios. To make it manipulable, we propose sparse correspondence alignment which involves point-based control to guide the generation for specific locations. With this design, Wear-Any-Way gets state-of-the-art performance for the standard setting and provides a novel interaction form for customizing the wearing style. For instance, it supports users to drag the sleeve to make it rolled up, drag the coat to make it open, and utilize clicks to control the style of tuck, etc. Wear-Any-Way enables more liberated and flexible expressions of the attires, holding profound implications in the fashion industry.
Audio-Visual Segmentation via Unlabeled Frame Exploitation
Mar 17, 2024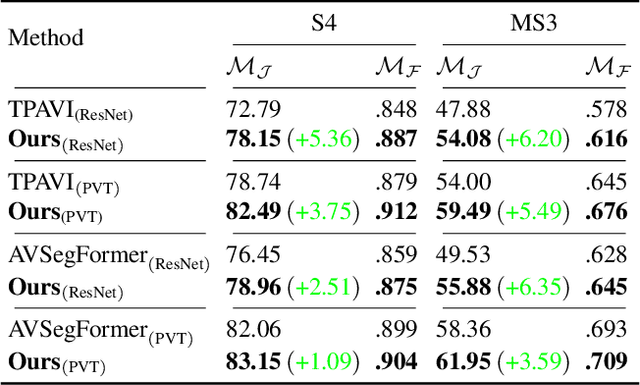
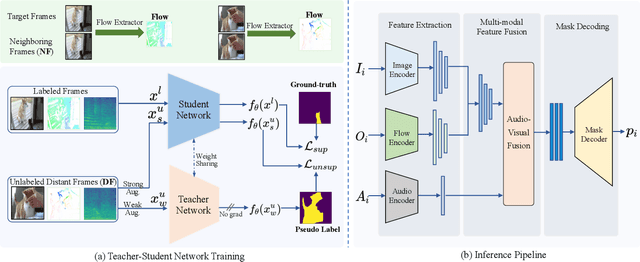
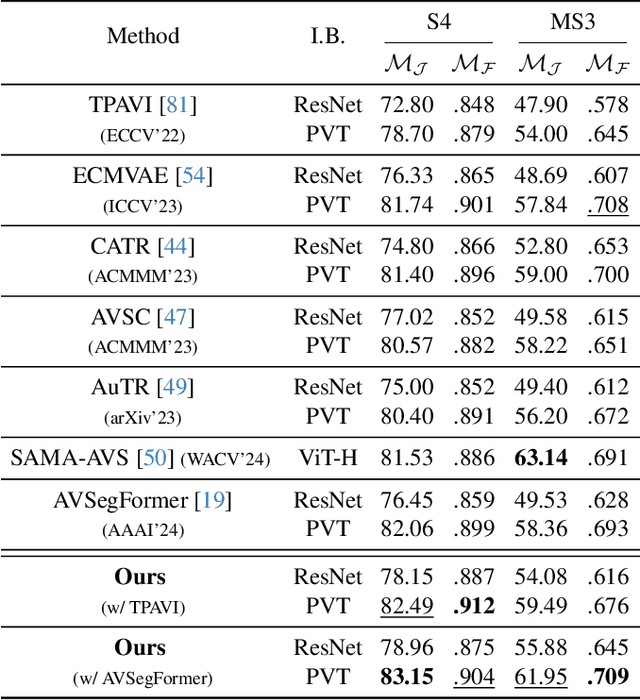
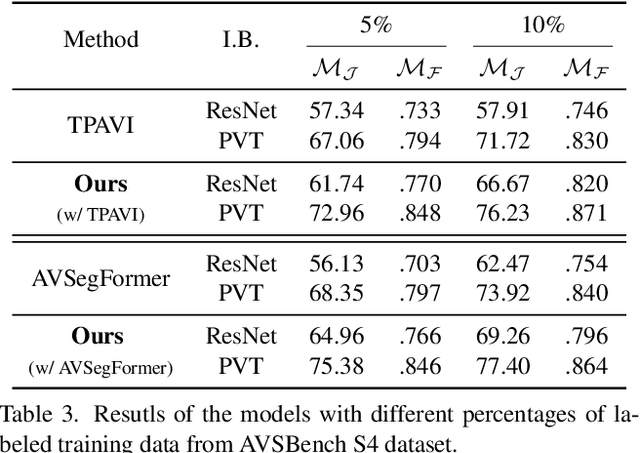
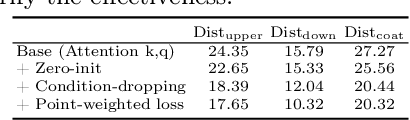
Audio-visual segmentation (AVS) aims to segment the sounding objects in video frames. Although great progress has been witnessed, we experimentally reveal that current methods reach marginal performance gain within the use of the unlabeled frames, leading to the underutilization issue. To fully explore the potential of the unlabeled frames for AVS, we explicitly divide them into two categories based on their temporal characteristics, i.e., neighboring frame (NF) and distant frame (DF). NFs, temporally adjacent to the labeled frame, often contain rich motion information that assists in the accurate localization of sounding objects. Contrary to NFs, DFs have long temporal distances from the labeled frame, which share semantic-similar objects with appearance variations. Considering their unique characteristics, we propose a versatile framework that effectively leverages them to tackle AVS. Specifically, for NFs, we exploit the motion cues as the dynamic guidance to improve the objectness localization. Besides, we exploit the semantic cues in DFs by treating them as valid augmentations to the labeled frames, which are then used to enrich data diversity in a self-training manner. Extensive experimental results demonstrate the versatility and superiority of our method, unleashing the power of the abundant unlabeled frames.