 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranches, Assemble! Multi-Branch Cooperation Network for Large-Scale Click-Through Rate Prediction at Taobao
Nov 20, 2024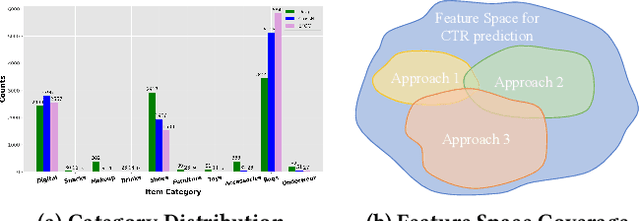
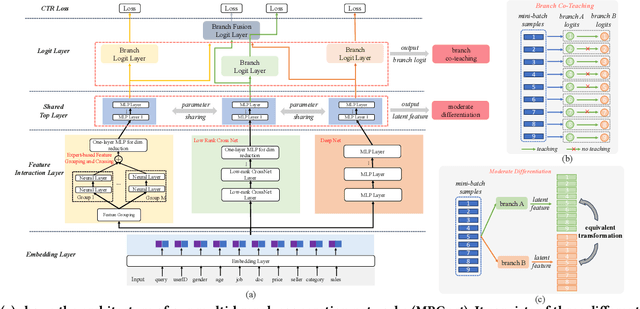

Existing click-through rate (CTR) prediction works have studied the role of feature interaction through a variety of techniques. Each interaction technique exhibits its own strength, and solely using one type could constrain the model's capability to capture the complex feature relationships, especially for industrial large-scale data with enormous users and items. Recent research shows that effective CTR models often combine an MLP network with a dedicated feature interaction network in a two-parallel structure. However, the interplay and cooperative dynamics between different streams or branches remain under-researched. In this work, we introduce a novel Multi-Branch Cooperation Network (MBCnet) which enables multiple branch networks to collaborate with each other for better complex feature interaction modeling. Specifically, MBCnet consists of three branches: the Expert-based Feature Grouping and Crossing (EFGC) branch that promotes the model's memorization ability of specific feature fields, the low rank Cross Net branch and Deep branch to enhance both explicit and implicit feature crossing for improved generalization. Among branches, a novel cooperation scheme is proposed based on two principles: branch co-teaching and moderate differentiation. Branch co-teaching encourages well-learned branches to support poorly-learned ones on specific training samples. Moderate differentiation advocates branches to maintain a reasonable level of difference in their feature representations. The cooperation strategy improves learning through mutual knowledge sharing via co-teaching and boosts the discovery of diverse feature interactions across branches. Extensive experiments on large-scale industrial datasets and online A/B test demonstrate MBCnet's superior performance, delivering a 0.09 point increase in CTR, 1.49% growth in deals, and 1.62% rise in GMV. Core codes will be released soon.
Enhancing Cross-domain Click-Through Rate Prediction via Explicit Feature Augmentation
Nov 30, 2023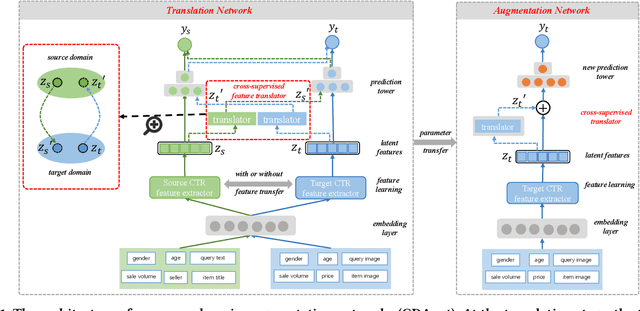
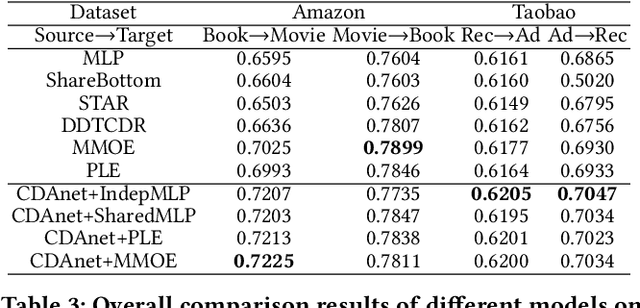
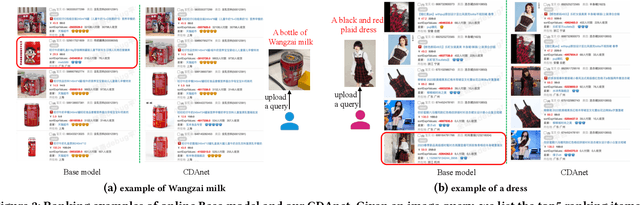

Cross-domain CTR (CDCTR) prediction is an important research topic that studies how to leverage meaningful data from a related domain to help CTR prediction in target domain. Most existing CDCTR works design implicit ways to transfer knowledge across domains such as parameter-sharing that regularizes the model training in target domain. More effectively, recent researchers propose explicit techniques to extract user interest knowledge and transfer this knowledge to target domain. However, the proposed method mainly faces two issues: 1) it usually requires a super domain, i.e. an extremely large source domain, to cover most users or items of target domain, and 2) the extracted user interest knowledge is static no matter what the context is in target domain. These limitations motivate us to develop a more flexible and efficient technique to explicitly transfer knowledge. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform explicit knowledge transfer between two domains. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network computes latent features from two domains and learns meaningful cross-domain knowledge of each input in target domain by using a designed cross-supervised feature translator. Later the augmentation network employs the explicit cross-domain knowledge as augmented information to boost the target domain CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app, bringing an absolute 0.11 point CTR improvement, a relative 0.64% deal growth and a relative 1.26% GMV increase.
Cross-domain Augmentation Networks for Click-Through Rate Prediction
May 09, 2023



Data sparsity is an important issue for click-through rate (CTR) prediction, particularly when user-item interactions is too sparse to learn a reliable model. Recently, many works on cross-domain CTR (CDCTR) prediction have been developed in an effort to leverage meaningful data from a related domain. However, most existing CDCTR works have an impractical limitation that requires homogeneous inputs (\textit{i.e.} shared feature fields) across domains, and CDCTR with heterogeneous inputs (\textit{i.e.} varying feature fields) across domains has not been widely explored but is an urgent and important research problem. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform knowledge transfer between two domains with \textit{heterogeneous inputs}. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network is able to compute features from two domains with heterogeneous inputs separately by designing two independent branches, and then learn meaningful cross-domain knowledge using a designed cross-supervised feature translator. Later the augmentation network encodes the learned cross-domain knowledge via feature translation performed in the latent space and fine-tune the model for final CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app over 20days, bringing an absolute \textbf{0.11 point} CTR improvement and a relative \textbf{1.26\%} GMV increase.
Mixer: Image to Multi-Modal Retrieval Learning for Industrial Application
May 06, 2023



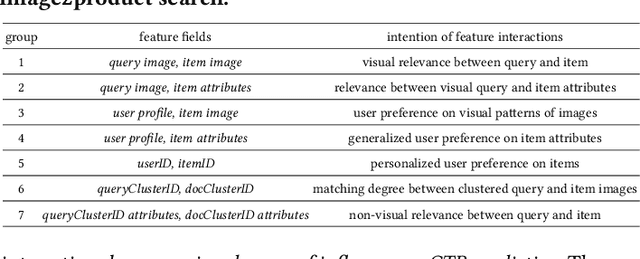
Cross-modal retrieval, where the query is an image and the doc is an item with both image and text description, is ubiquitous in e-commerce platforms and content-sharing social media. However, little research attention has been paid to this important application. This type of retrieval task is challenging due to the facts: 1)~domain gap exists between query and doc. 2)~multi-modality alignment and fusion. 3)~skewed training data and noisy labels collected from user behaviors. 4)~huge number of queries and timely responses while the large-scale candidate docs exist. To this end, we propose a novel scalable and efficient image query to multi-modal retrieval learning paradigm called Mixer, which adaptively integrates multi-modality data, mines skewed and noisy data more efficiently and scalable to high traffic. The Mixer consists of three key ingredients: First, for query and doc image, a shared encoder network followed by separate transformation networks are utilized to account for their domain gap. Second, in the multi-modal doc, images and text are not equally informative. So we design a concept-aware modality fusion module, which extracts high-level concepts from the text by a text-to-image attention mechanism. Lastly, but most importantly, we turn to a new data organization and training paradigm for single-modal to multi-modal retrieval: large-scale classification learning which treats single-modal query and multi-modal doc as equivalent samples of certain classes. Besides, the data organization follows a weakly-supervised manner, which can deal with skewed data and noisy labels inherited in the industrial systems. Learning such a large number of categories for real-world multi-modality data is non-trivial and we design a specific learning strategy for it. The proposed Mixer achieves SOTA performance on public datasets from industrial retrieval systems.
Spatio-Temporal Graph Complementary Scattering Networks
Oct 23, 2021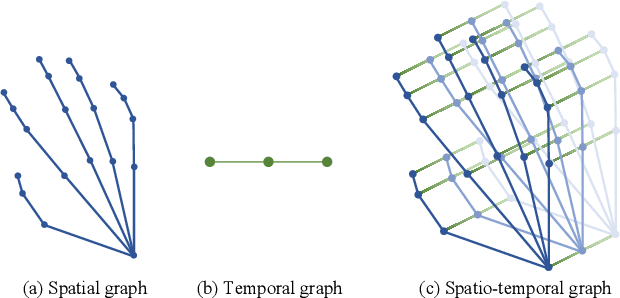

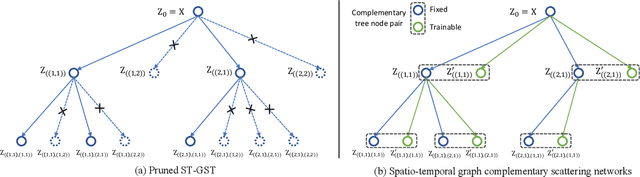

Spatio-temporal graph signal analysis has a significant impact on a wide range of applications, including hand/body pose action recognition. To achieve effective analysis, spatio-temporal graph convolutional networks (ST-GCN) leverage the powerful learning ability to achieve great empirical successes; however, those methods need a huge amount of high-quality training data and lack theoretical interpretation. To address this issue, the spatio-temporal graph scattering transform (ST-GST) was proposed to put forth a theoretically interpretable framework; however, the empirical performance of this approach is constrainted by the fully mathematical design. To benefit from both sides, this work proposes a novel complementary mechanism to organically combine the spatio-temporal graph scattering transform and neural networks, resulting in the proposed spatio-temporal graph complementary scattering networks (ST-GCSN). The essence is to leverage the mathematically designed graph wavelets with pruning techniques to cover major information and use trainable networks to capture complementary information. The empirical experiments on hand pose action recognition show that the proposed ST-GCSN outperforms both ST-GCN and ST-GST.
Semi-supervised 3D Hand-Object Pose Estimation via Pose Dictionary Learning
Jul 16, 2021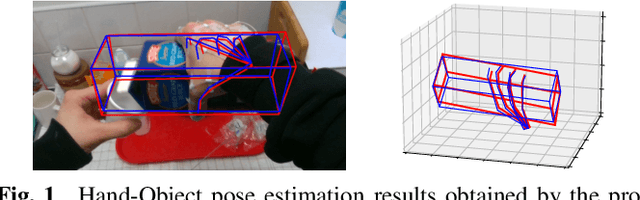
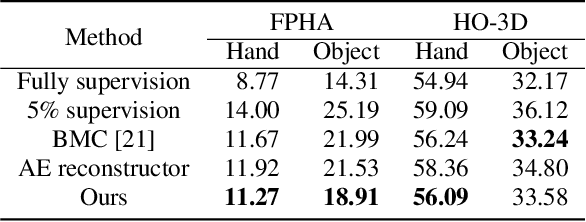
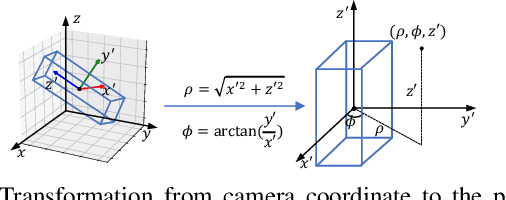
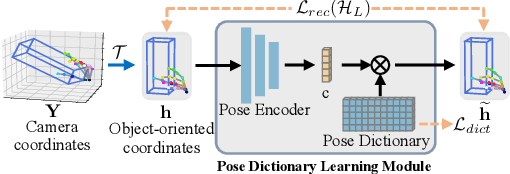
3D hand-object pose estimation is an important issue to understand the interaction between human and environment. Current hand-object pose estimation methods require detailed 3D labels, which are expensive and labor-intensive. To tackle the problem of data collection, we propose a semi-supervised 3D hand-object pose estimation method with two key techniques: pose dictionary learning and an object-oriented coordinate system. The proposed pose dictionary learning module can distinguish infeasible poses by reconstruction error, enabling unlabeled data to provide supervision signals. The proposed object-oriented coordinate system can make 3D estimations equivariant to the camera perspective. Experiments are conducted on FPHA and HO-3D datasets. Our method reduces estimation error by 19.5% / 24.9% for hands/objects compared to straightforward use of labeled data on FPHA and outperforms several baseline methods. Extensive experiments also validate the robustness of the proposed method.