 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance
May 20, 2026Video Virtual Try-On (VVT) aims to seamlessly replace a garment on a person in a video with a new one. While existing methods have made significant strides in maintaining temporal consistency, they are predominantly confined to non-interactive scenarios where models merely showcase garments. This limitation overlooks a crucial aspect of real-world apparel presentation: active human-garment interaction. To bridge this gap, we introduce and formalize a new challenging task: Interactive Video Virtual Try-On (Interactive VVT), where subjects in the video actively engage with their clothing. This task introduces unique challenges beyond simple texture preservation, including: (1) resolving the semantic ambiguity of interactions from standard pose information, and (2) learning complex garment deformations from video where interactive moments are sparse and brief. To address these challenges, we propose iTryOn, a novel framework built upon a large-scale video diffusion Transformer. iTryOn pioneers a multi-level interaction injection mechanism to guide the generation of complex dynamics. At the spatial level, we introduce a garment-agnostic 3D hand prior to provide fine-grained guidance for precise hand-garment contact, effectively resolving spatial ambiguity. At the semantic level, iTryOn leverages global captions for overall context and time-stamped action captions for localized interactions, synchronized via our novel Action-aware Rotational Position Embedding (A-RoPE). Extensive experiments demonstrate that iTryOn not only achieves state-of-the-art performance on traditional VVT benchmarks but also establishes a commanding lead in the new interactive setting, marking a significant step towards more dynamic and controllable virtual try-on experiences.
Improving Human Image Animation via Semantic Representation Alignment
May 11, 2026The field of image-to-video generation has made remarkable progress. However, challenges such as human limb twisting and facial distortion persist, especially when generating long videos or modeling intensive motions. Existing human image animation works address these issues by incorporating human-specific semantic representations, e.g., dense poses or ID embeddings, as additional conditions. However, conditioning on these representations could decrease the generation flexibility. Moreover, their reliance on RGB pixel supervision also lacks emphasis on learning necessary 3D geometric relationships and temporal coherence. In contrast, we introduce a novel approach named SemanticREPA that leverages these semantic representations as supervision signals through representation alignment. Specifically, we begin by training a structure alignment module that aligns the structure representations obtained from video latents with video depth estimation features. We then fix the pretrained module, and utilize it to provide additional supervision on the structure representations of the diffusion models, achieving structure rectification to generate coherent and stable human structures. Simultaneously, we develop an ID alignment module to align the ID representations of the generated videos to face recognition features. We further propose to use the predicted structure representations to refine identity restoration in relevant regions. With structure and ID alignment, our method demonstrates superior quality on extended character motions and enhanced character consistency.
Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
May 07, 2026Step distillation has become a leading technique for accelerating diffusion models, among which Distribution Matching Distillation (DMD) and Consistency Distillation are two representative paradigms. While consistency methods enforce self-consistency along the full PF-ODE trajectory to steer it toward the clean data manifold, vanilla DMD relies on sparse supervision at a few predefined discrete timesteps. This restricted discrete-time formulation and mode-seeking nature of the reverse KL divergence tends to exhibit visual artifacts and over-smoothed outputs, often necessitating complex auxiliary modules -- such as GANs or reward models -- to restore visual fidelity. In this work, we introduce Continuous-Time Distribution Matching (CDM), migrating the DMD framework from discrete anchoring to continuous optimization for the first time. CDM achieves this through two continuous-time designs. First, we replace the fixed discrete schedule with a dynamic continuous schedule of random length, so that distribution matching is enforced at arbitrary points along sampling trajectories rather than only at a few fixed anchors. Second, we propose a continuous-time alignment objective that performs active off-trajectory matching on latents extrapolated via the student's velocity field, improving generalization and preserving fine visual details. Extensive experiments on different architectures, including SD3-Medium and Longcat-Image, demonstrate that CDM provides highly competitive visual fidelity for few-step image generation without relying on complex auxiliary objectives. Code is available at https://github.com/byliutao/cdm.
Tstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning
Mar 02, 2026Large Vision-Language Models (LVLMs) often omit or misrepresent critical visual content in generated image captions. Minimizing such information loss will force LVLMs to focus on image details to generate precise descriptions. However, measuring information loss during modality conversion is inherently challenging due to the modal gap between visual content and text output. In this paper, we argue that the quality of an image caption is positively correlated with the similarity between images retrieved via text search using that caption. Based on this insight, we further propose Cross-modal Identity Mapping (CIM), a reinforcement learning framework that enhances image captioning without requiring additional annotations. Specifically, the method quantitatively evaluates the information loss from two perspectives: Gallery Representation Consistency and Query-gallery Image Relevance. Supervised under these metrics, LVLM minimizes information loss and aims to achieve identity mapping from images to captions. The experimental results demonstrate the superior performance of our method in image captioning, even when compared with Supervised Fine-Tuning. Particularly, on the COCO-LN500 benchmark, CIM achieves a 20% improvement in relation reasoning on Qwen2.5-VL-7B.The code will be released when the paper is accepted.
Pailitao-VL: Unified Embedding and Reranker for Real-Time Multi-Modal Industrial Search
Feb 14, 2026In this work, we presented Pailitao-VL, a comprehensive multi-modal retrieval system engineered for high-precision, real-time industrial search. We here address three critical challenges in the current SOTA solution: insufficient retrieval granularity, vulnerability to environmental noise, and prohibitive efficiency-performance gap. Our primary contribution lies in two fundamental paradigm shifts. First, we transitioned the embedding paradigm from traditional contrastive learning to an absolute ID-recognition task. Through anchoring instances to a globally consistent latent space defined by billions of semantic prototypes, we successfully overcome the stochasticity and granularity bottlenecks inherent in existing embedding solutions. Second, we evolved the generative reranker from isolated pointwise evaluation to the compare-and-calibrate listwise policy. By synergizing chunk-based comparative reasoning with calibrated absolute relevance scoring, the system achieves nuanced discriminative resolution while circumventing the prohibitive latency typically associated with conventional reranking methods. Extensive offline benchmarks and online A/B tests on Alibaba e-commerce platform confirm that Pailitao-VL achieves state-of-the-art performance and delivers substantial business impact. This work demonstrates a robust and scalable path for deploying advanced MLLM-based retrieval architectures in demanding, large-scale production environments.
REVISION:Reflective Intent Mining and Online Reasoning Auxiliary for E-commerce Visual Search System Optimization
Oct 26, 2025In Taobao e-commerce visual search, user behavior analysis reveals a large proportion of no-click requests, suggesting diverse and implicit user intents. These intents are expressed in various forms and are difficult to mine and discover, thereby leading to the limited adaptability and lag in platform strategies. This greatly restricts users' ability to express diverse intents and hinders the scalability of the visual search system. This mismatch between user implicit intent expression and system response defines the User-SearchSys Intent Discrepancy. To alleviate the issue, we propose a novel framework REVISION. This framework integrates offline reasoning mining with online decision-making and execution, enabling adaptive strategies to solve implicit user demands. In the offline stage, we construct a periodic pipeline to mine discrepancies from historical no-click requests. Leveraging large models, we analyze implicit intent factors and infer optimal suggestions by jointly reasoning over query and product metadata. These inferred suggestions serve as actionable insights for refining platform strategies. In the online stage, REVISION-R1-3B, trained on the curated offline data, performs holistic analysis over query images and associated historical products to generate optimization plans and adaptively schedule strategies across the search pipeline. Our framework offers a streamlined paradigm for integrating large models with traditional search systems, enabling end-to-end intelligent optimization across information aggregation and user interaction. Experimental results demonstrate that our approach improves the efficiency of implicit intent mining from large-scale search logs and significantly reduces the no-click rate.
MMKB-RAG: A Multi-Modal Knowledge-Based Retrieval-Augmented Generation Framework
Apr 15, 2025Recent advancements in large language models (LLMs) and multi-modal LLMs have been remarkable. However, these models still rely solely on their parametric knowledge, which limits their ability to generate up-to-date information and increases the risk of producing erroneous content. Retrieval-Augmented Generation (RAG) partially mitigates these challenges by incorporating external data sources, yet the reliance on databases and retrieval systems can introduce irrelevant or inaccurate documents, ultimately undermining both performance and reasoning quality. In this paper, we propose Multi-Modal Knowledge-Based Retrieval-Augmented Generation (MMKB-RAG), a novel multi-modal RAG framework that leverages the inherent knowledge boundaries of models to dynamically generate semantic tags for the retrieval process. This strategy enables the joint filtering of retrieved documents, retaining only the most relevant and accurate references. Extensive experiments on knowledge-based visual question-answering tasks demonstrate the efficacy of our approach: on the E-VQA dataset, our method improves performance by +4.2% on the Single-Hop subset and +0.4% on the full dataset, while on the InfoSeek dataset, it achieves gains of +7.8% on the Unseen-Q subset, +8.2% on the Unseen-E subset, and +8.1% on the full dataset. These results highlight significant enhancements in both accuracy and robustness over the current state-of-the-art MLLM and RAG frameworks.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024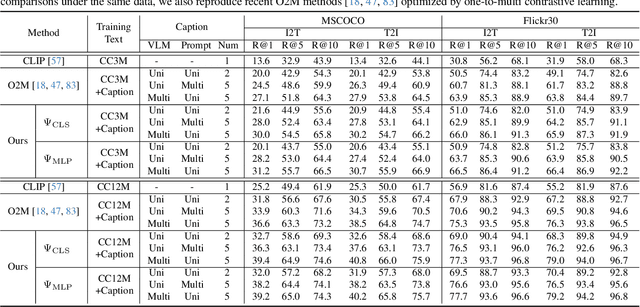
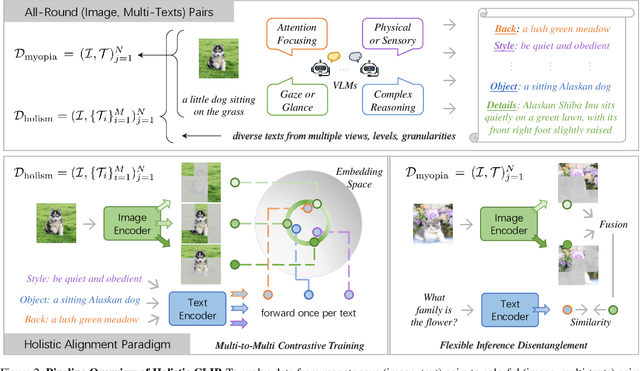
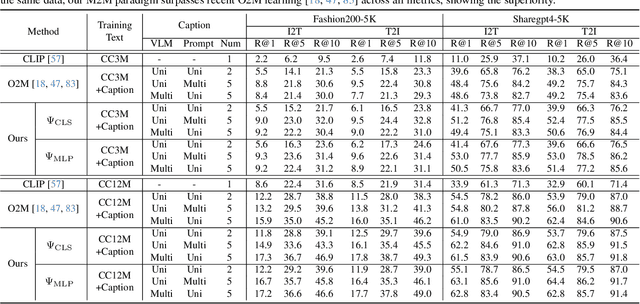
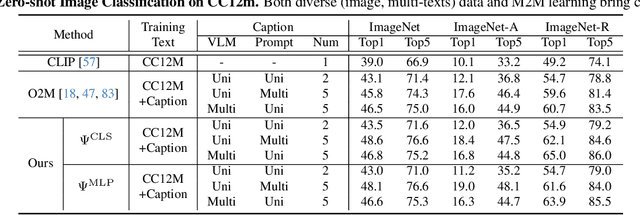
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.