 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Paper and Code
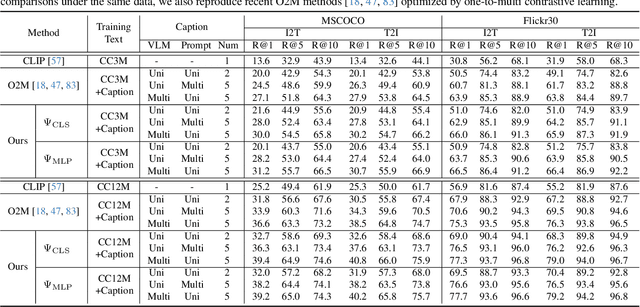
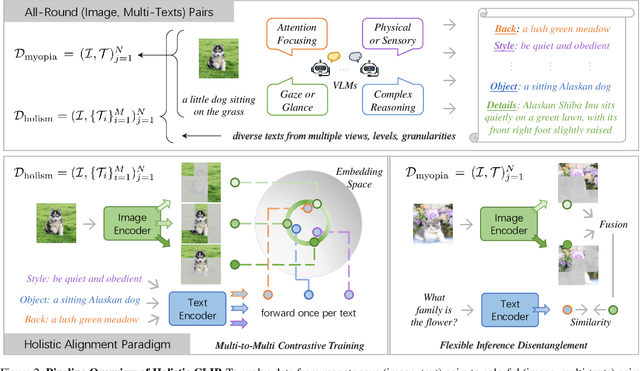
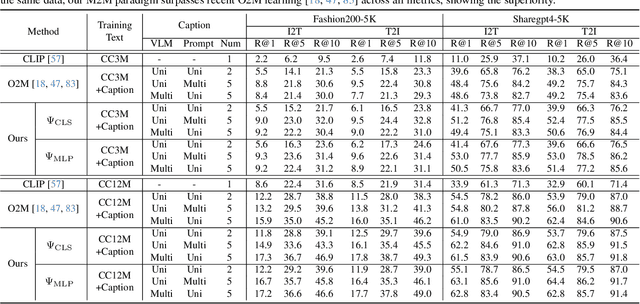
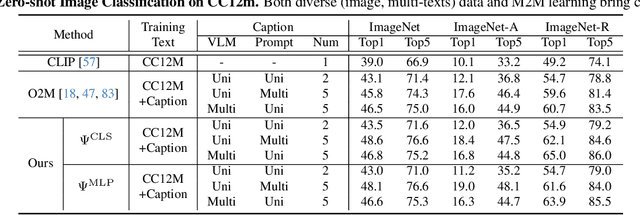
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.