 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimateAnywhere: Rouse the Background in Human Image Animation
Apr 28, 2025Human image animation aims to generate human videos of given characters and backgrounds that adhere to the desired pose sequence. However, existing methods focus more on human actions while neglecting the generation of background, which typically leads to static results or inharmonious movements. The community has explored camera pose-guided animation tasks, yet preparing the camera trajectory is impractical for most entertainment applications and ordinary users. As a remedy, we present an AnimateAnywhere framework, rousing the background in human image animation without requirements on camera trajectories. In particular, based on our key insight that the movement of the human body often reflects the motion of the background, we introduce a background motion learner (BML) to learn background motions from human pose sequences. To encourage the model to learn more accurate cross-frame correspondences, we further deploy an epipolar constraint on the 3D attention map. Specifically, the mask used to suppress geometrically unreasonable attention is carefully constructed by combining an epipolar mask and the current 3D attention map. Extensive experiments demonstrate that our AnimateAnywhere effectively learns the background motion from human pose sequences, achieving state-of-the-art performance in generating human animation results with vivid and realistic backgrounds. The source code and model will be available at https://github.com/liuxiaoyu1104/AnimateAnywhere.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024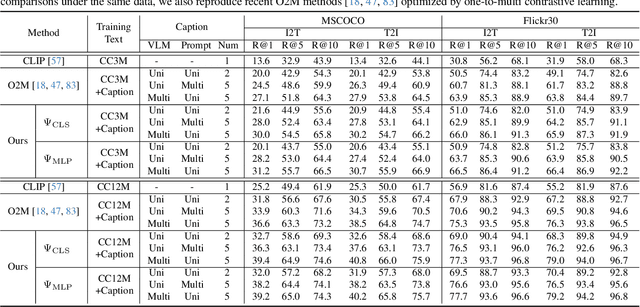
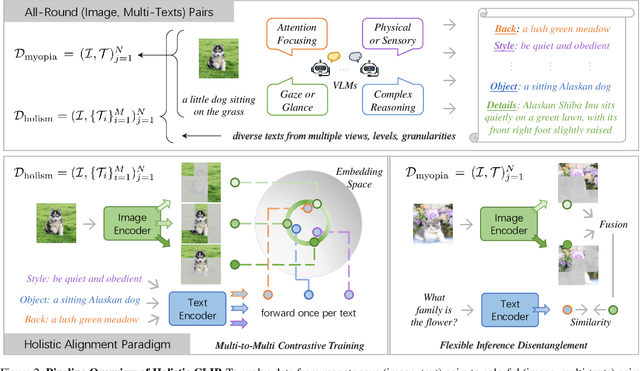
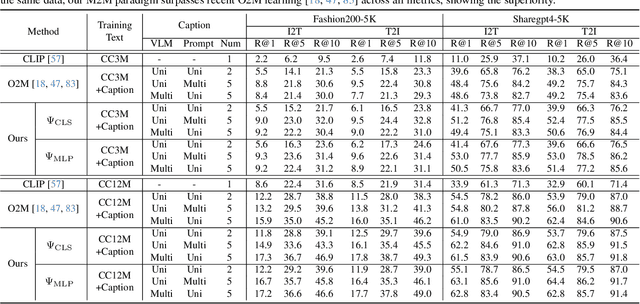
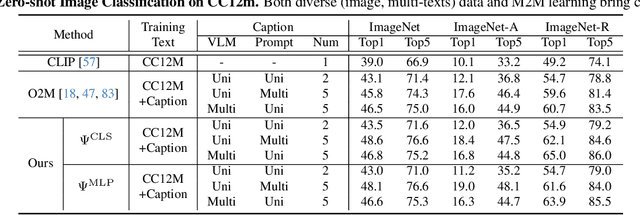
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
VQ-Font: Few-Shot Font Generation with Structure-Aware Enhancement and Quantization
Aug 27, 2023



Few-shot font generation is challenging, as it needs to capture the fine-grained stroke styles from a limited set of reference glyphs, and then transfer to other characters, which are expected to have similar styles. However, due to the diversity and complexity of Chinese font styles, the synthesized glyphs of existing methods usually exhibit visible artifacts, such as missing details and distorted strokes. In this paper, we propose a VQGAN-based framework (i.e., VQ-Font) to enhance glyph fidelity through token prior refinement and structure-aware enhancement. Specifically, we pre-train a VQGAN to encapsulate font token prior within a codebook. Subsequently, VQ-Font refines the synthesized glyphs with the codebook to eliminate the domain gap between synthesized and real-world strokes. Furthermore, our VQ-Font leverages the inherent design of Chinese characters, where structure components such as radicals and character components are combined in specific arrangements, to recalibrate fine-grained styles based on references. This process improves the matching and fusion of styles at the structure level. Both modules collaborate to enhance the fidelity of the generated fonts. Experiments on a collected font dataset show that our VQ-Font outperforms the competing methods both quantitatively and qualitatively, especially in generating challenging styles.
Towards Diverse and Faithful One-shot Adaption of Generative Adversarial Networks
Jul 18, 2022



One-shot generative domain adaption aims to transfer a pre-trained generator on one domain to a new domain using one reference image only. However, it remains very challenging for the adapted generator (i) to generate diverse images inherited from the pre-trained generator while (ii) faithfully acquiring the domain-specific attributes and styles of the reference image. In this paper, we present a novel one-shot generative domain adaption method, i.e., DiFa, for diverse generation and faithful adaptation. For global-level adaptation, we leverage the difference between the CLIP embedding of reference image and the mean embedding of source images to constrain the target generator. For local-level adaptation, we introduce an attentive style loss which aligns each intermediate token of adapted image with its corresponding token of the reference image. To facilitate diverse generation, selective cross-domain consistency is introduced to select and retain the domain-sharing attributes in the editing latent $\mathcal{W}+$ space to inherit the diversity of pre-trained generator. Extensive experiments show that our method outperforms the state-of-the-arts both quantitatively and qualitatively, especially for the cases of large domain gaps. Moreover, our DiFa can easily be extended to zero-shot generative domain adaption with appealing results. Code is available at https://github.com/1170300521/DiFa.