 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multimodal Challenges in Toxic Chinese Detection: Taxonomy, Benchmark, and Findings
May 30, 2025Detecting toxic content using language models is important but challenging. While large language models (LLMs) have demonstrated strong performance in understanding Chinese, recent studies show that simple character substitutions in toxic Chinese text can easily confuse the state-of-the-art (SOTA) LLMs. In this paper, we highlight the multimodal nature of Chinese language as a key challenge for deploying LLMs in toxic Chinese detection. First, we propose a taxonomy of 3 perturbation strategies and 8 specific approaches in toxic Chinese content. Then, we curate a dataset based on this taxonomy, and benchmark 9 SOTA LLMs (from both the US and China) to assess if they can detect perturbed toxic Chinese text. Additionally, we explore cost-effective enhancement solutions like in-context learning (ICL) and supervised fine-tuning (SFT). Our results reveal two important findings. (1) LLMs are less capable of detecting perturbed multimodal Chinese toxic contents. (2) ICL or SFT with a small number of perturbed examples may cause the LLMs "overcorrect'': misidentify many normal Chinese contents as toxic.
Squeeze Out Tokens from Sample for Finer-Grained Data Governance
Mar 18, 2025Widely observed data scaling laws, in which error falls off as a power of the training size, demonstrate the diminishing returns of unselective data expansion. Hence, data governance is proposed to downsize datasets through pruning non-informative samples. Yet, isolating the impact of a specific sample on overall model performance is challenging, due to the vast computation required for tryout all sample combinations. Current data governors circumvent this complexity by estimating sample contributions through heuristic-derived scalar scores, thereby discarding low-value ones. Despite thorough sample sieving, retained samples contain substantial undesired tokens intrinsically, underscoring the potential for further compression and purification. In this work, we upgrade data governance from a 'sieving' approach to a 'juicing' one. Instead of scanning for least-flawed samples, our dual-branch DataJuicer applies finer-grained intra-sample governance. It squeezes out informative tokens and boosts image-text alignments. Specifically, the vision branch retains salient image patches and extracts relevant object classes, while the text branch incorporates these classes to enhance captions. Consequently, DataJuicer yields more refined datasets through finer-grained governance. Extensive experiments across datasets demonstrate that DataJuicer significantly outperforms existing DataSieve in image-text retrieval, classification, and dense visual reasoning.
Contrast-Unity for Partially-Supervised Temporal Sentence Grounding
Feb 18, 2025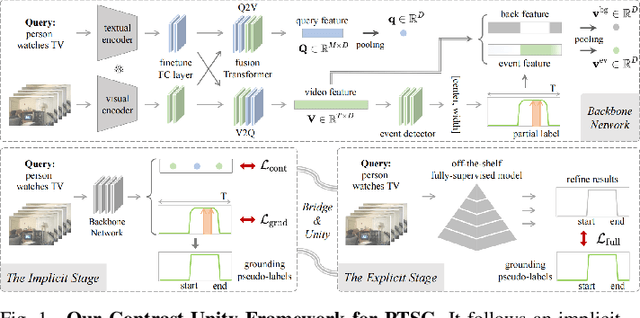
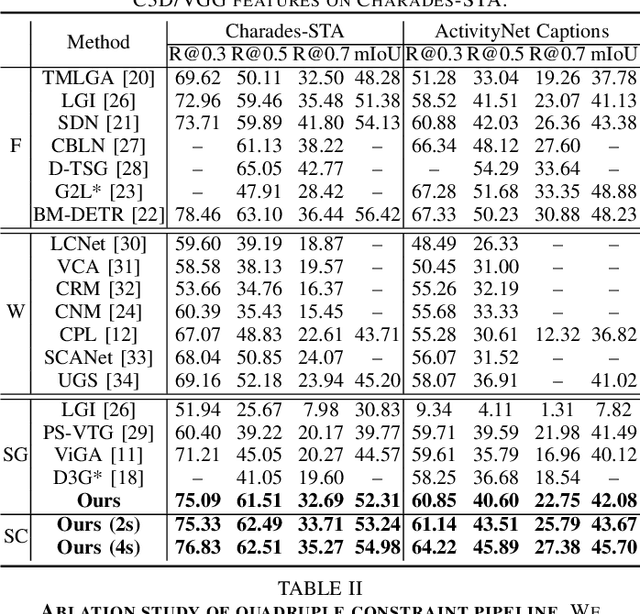
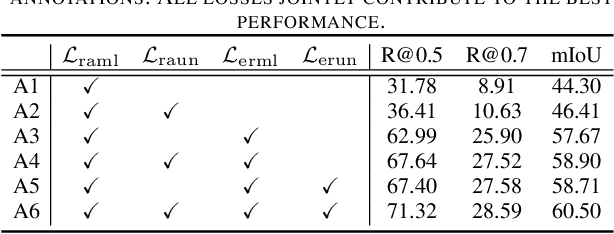
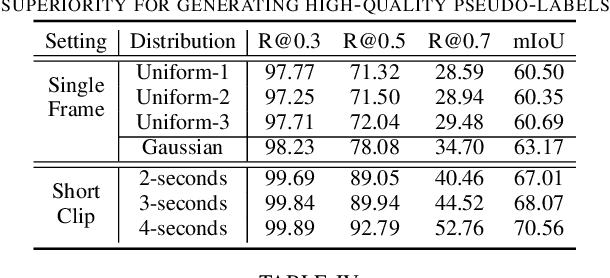
Temporal sentence grounding aims to detect event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great results but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation costs, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip is available during training. To make full use of partial labels, we specially design one contrast-unity framework, with the two-stage goal of implicit-explicit progressive grounding. In the implicit stage, we align event-query representations at fine granularity using comprehensive quadruple contrastive learning: event-query gather, event-background separation, intra-cluster compactness and inter-cluster separability. Then, high-quality representations bring acceptable grounding pseudo-labels. In the explicit stage, to explicitly optimize grounding objectives, we train one fully-supervised model using obtained pseudo-labels for grounding refinement and denoising. Extensive experiments and thoroughly ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision, as well as our superior performance.
FOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
Jan 05, 2025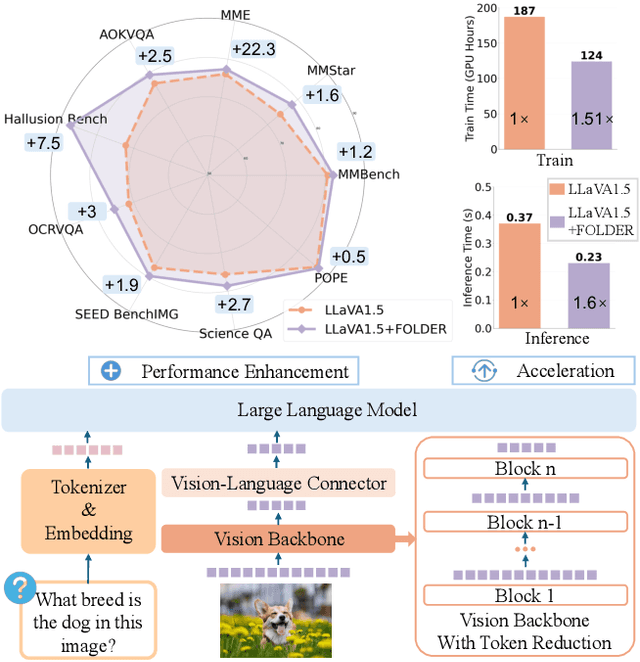
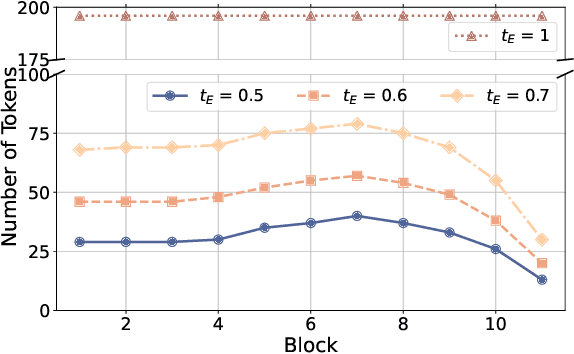
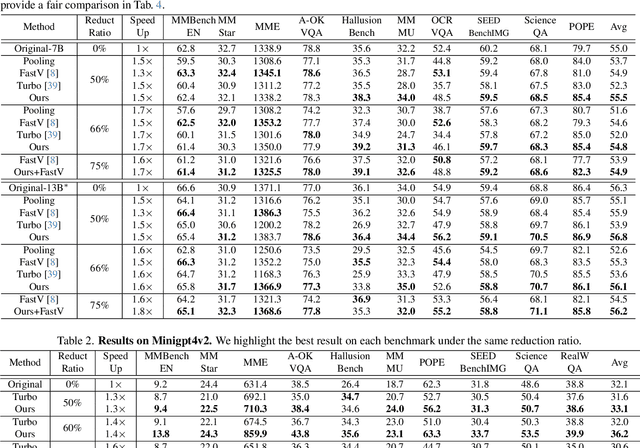
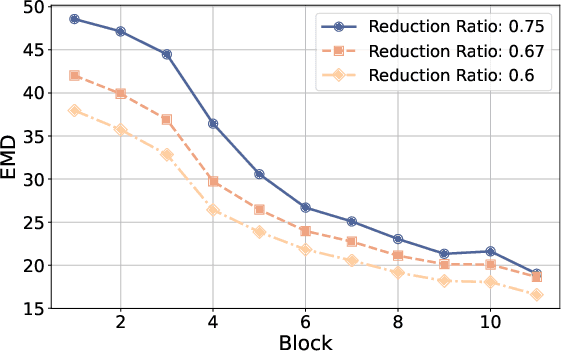
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024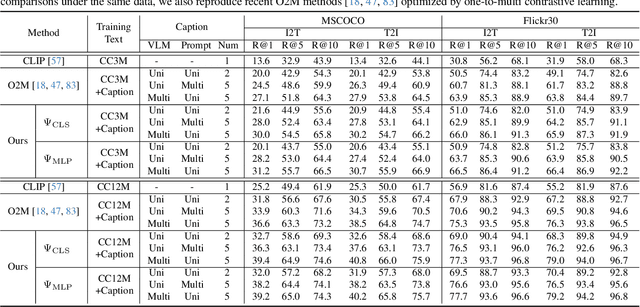
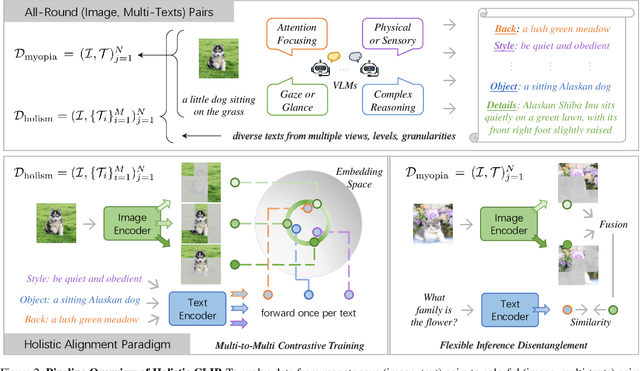
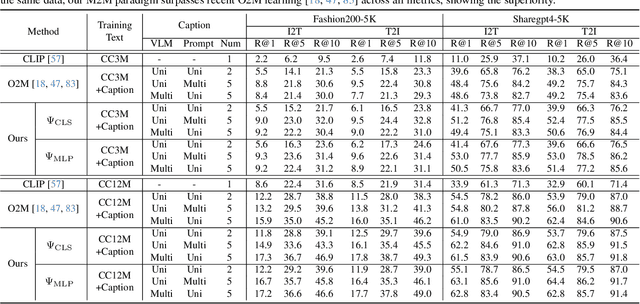
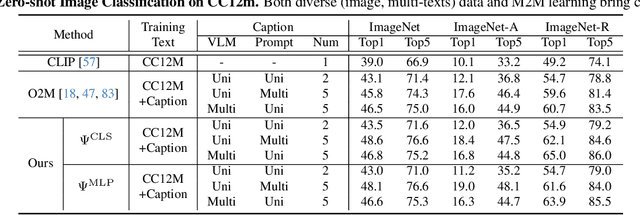
In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
DENOISER: Rethinking the Robustness for Open-Vocabulary Action Recognition
Apr 23, 2024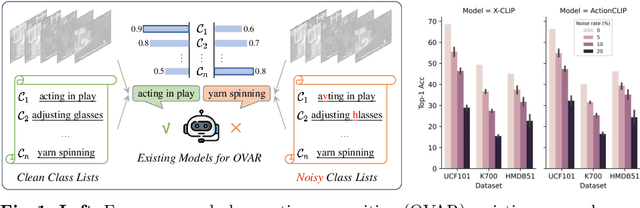
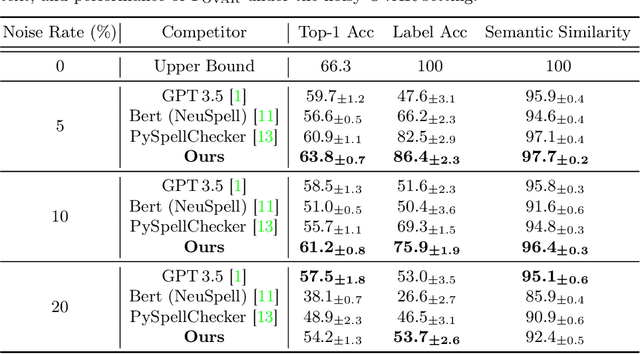
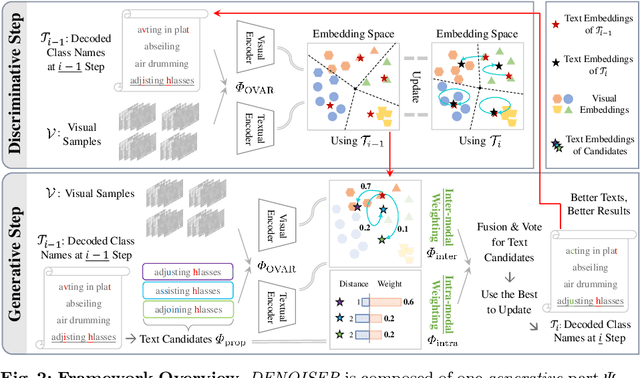
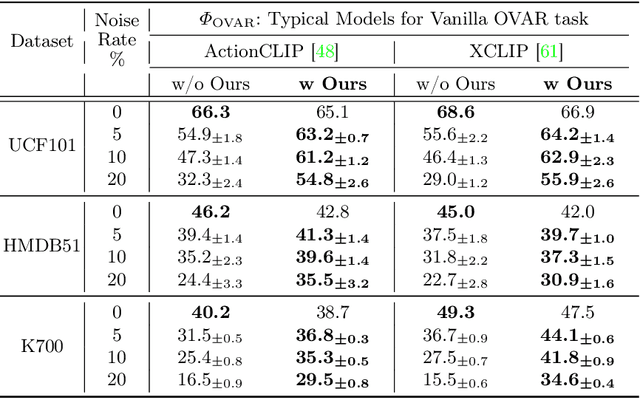
As one of the fundamental video tasks in computer vision, Open-Vocabulary Action Recognition (OVAR) recently gains increasing attention, with the development of vision-language pre-trainings. To enable generalization of arbitrary classes, existing methods treat class labels as text descriptions, then formulate OVAR as evaluating embedding similarity between visual samples and textual classes. However, one crucial issue is completely ignored: the class descriptions given by users may be noisy, e.g., misspellings and typos, limiting the real-world practicality of vanilla OVAR. To fill the research gap, this paper pioneers to evaluate existing methods by simulating multi-level noises of various types, and reveals their poor robustness. To tackle the noisy OVAR task, we further propose one novel DENOISER framework, covering two parts: generation and discrimination. Concretely, the generative part denoises noisy class-text names via one decoding process, i.e., propose text candidates, then utilize inter-modal and intra-modal information to vote for the best. At the discriminative part, we use vanilla OVAR models to assign visual samples to class-text names, thus obtaining more semantics. For optimization, we alternately iterate between generative and discriminative parts for progressive refinements. The denoised text classes help OVAR models classify visual samples more accurately; in return, classified visual samples help better denoising. On three datasets, we carry out extensive experiments to show our superior robustness, and thorough ablations to dissect the effectiveness of each component.
Towards Building Multilingual Language Model for Medicine
Feb 26, 2024



In this paper, we aim to develop an open-source, multilingual language model for medicine, that the benefits a wider, linguistically diverse audience from different regions. In general, we present the contribution from the following aspects: first, for multilingual medical-specific adaptation, we construct a new multilingual medical corpus, that contains approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, that enables auto-regressive training for existing general LLMs. second, to monitor the development of multilingual LLMs in medicine, we propose a new multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; third, we have assessed a number of popular, opensource large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC, as a result, our final model, termed as MMedLM 2, with only 7B parameters, achieves superior performance compared to all other open-source models, even rivaling GPT-4 on MMedBench. We will make the resources publicly available, including code, model weights, and datasets.
Turbo: Informativity-Driven Acceleration Plug-In for Vision-Language Models
Dec 12, 2023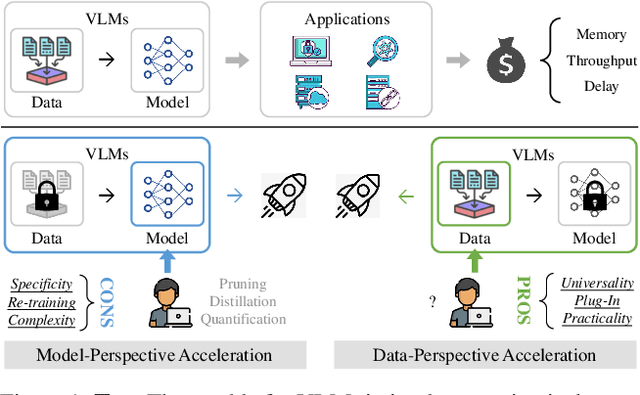
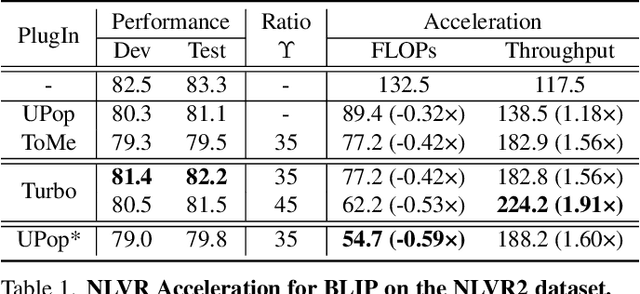
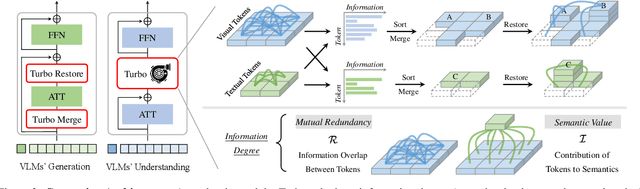
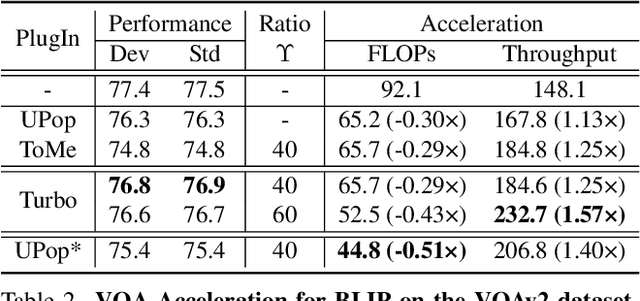
Vision-Language Large Models (VLMs) have become primary backbone of AI, due to the impressive performance. However, their expensive computation costs, i.e., throughput and delay, impede potentials in real-world scenarios. To achieve acceleration for VLMs, most existing methods focus on the model perspective: pruning, distillation, quantification, but completely overlook the data-perspective redundancy. To fill the overlook, this paper pioneers the severity of data redundancy, and designs one plug-and-play Turbo module guided by information degree to prune inefficient tokens from visual or textual data. In pursuit of efficiency-performance trade-offs, information degree takes two key factors into consideration: mutual redundancy and semantic value. Concretely, the former evaluates the data duplication between sequential tokens; while the latter evaluates each token by its contribution to the overall semantics. As a result, tokens with high information degree carry less redundancy and stronger semantics. For VLMs' calculation, Turbo works as a user-friendly plug-in that sorts data referring to information degree, utilizing only top-level ones to save costs. Its advantages are multifaceted, e.g., being generally compatible to various VLMs across understanding and generation, simple use without retraining and trivial engineering efforts. On multiple public VLMs benchmarks, we conduct extensive experiments to reveal the gratifying acceleration of Turbo, under negligible performance drop.
Constraint and Union for Partially-Supervised Temporal Sentence Grounding
Feb 20, 2023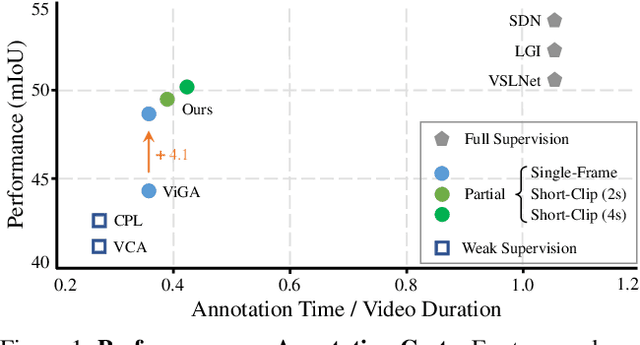

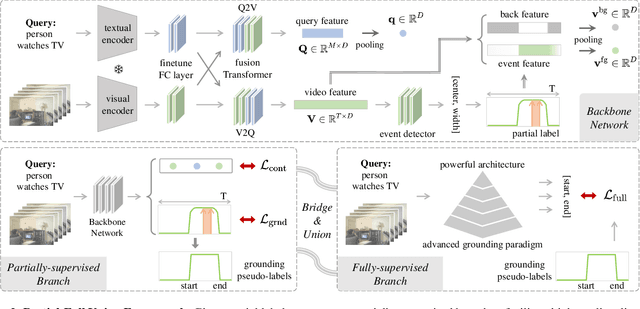

Temporal sentence grounding aims to detect the event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great performance but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation cost, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip or even single-frame labels are available during training. To take full advantage of partial labels, we propose a novel quadruple constraint pipeline to comprehensively shape event-query aligned representations, covering intra- and inter-samples, uni- and multi-modalities. The former raises intra-cluster compactness and inter-cluster separability; while the latter enables event-background separation and event-query gather. To achieve more powerful performance with explicit grounding optimization, we further introduce a partial-full union framework, i.e., bridging with an additional fully-supervised branch, to enjoy its impressive grounding bonus, and be robust to partial annotations. Extensive experiments and ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision and our superior performance.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020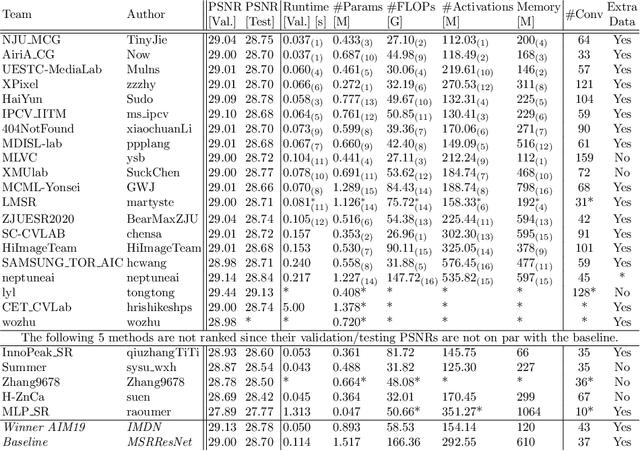
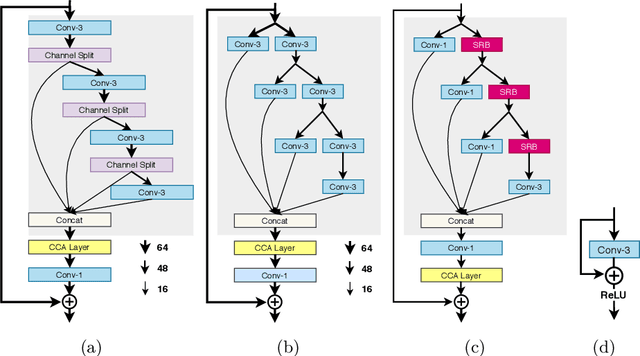
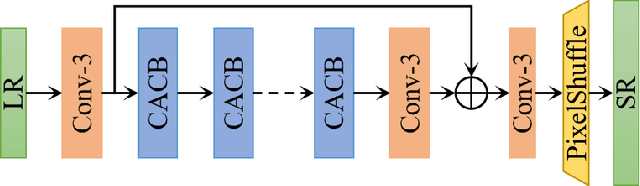
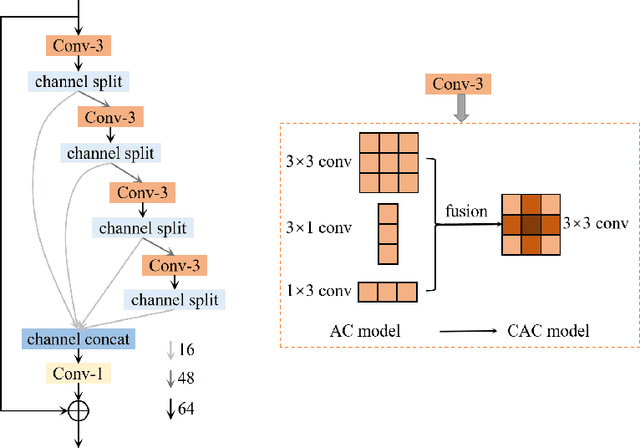
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.