 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint and Union for Partially-Supervised Temporal Sentence Grounding
Paper and Code
Feb 20, 2023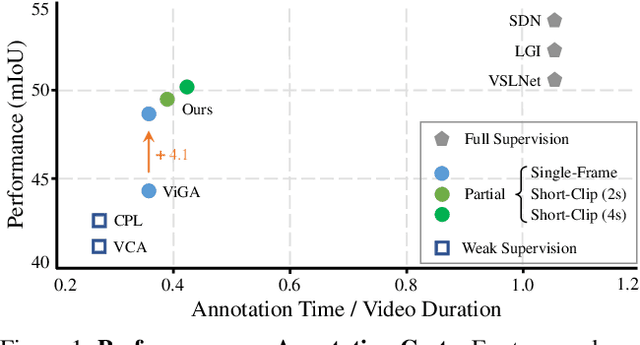

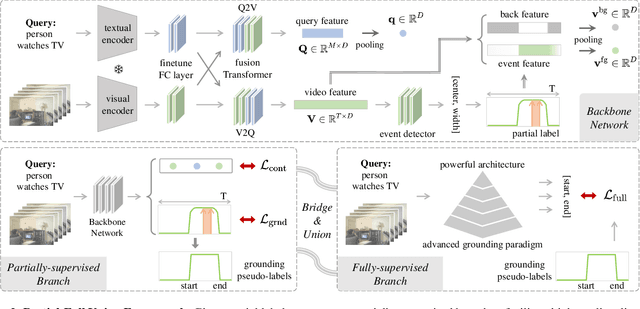

Temporal sentence grounding aims to detect the event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great performance but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation cost, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip or even single-frame labels are available during training. To take full advantage of partial labels, we propose a novel quadruple constraint pipeline to comprehensively shape event-query aligned representations, covering intra- and inter-samples, uni- and multi-modalities. The former raises intra-cluster compactness and inter-cluster separability; while the latter enables event-background separation and event-query gather. To achieve more powerful performance with explicit grounding optimization, we further introduce a partial-full union framework, i.e., bridging with an additional fully-supervised branch, to enjoy its impressive grounding bonus, and be robust to partial annotations. Extensive experiments and ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision and our superior performance.