 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
Jan 05, 2025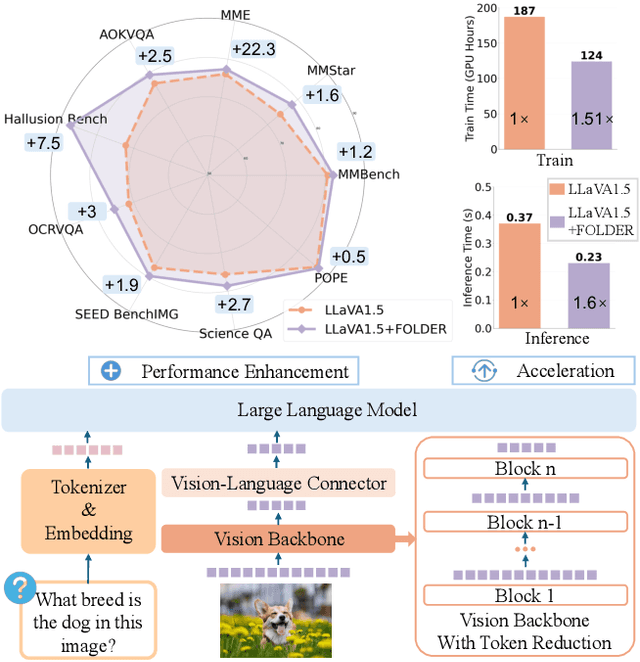
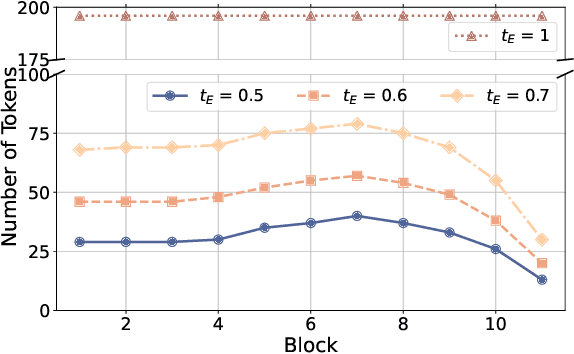
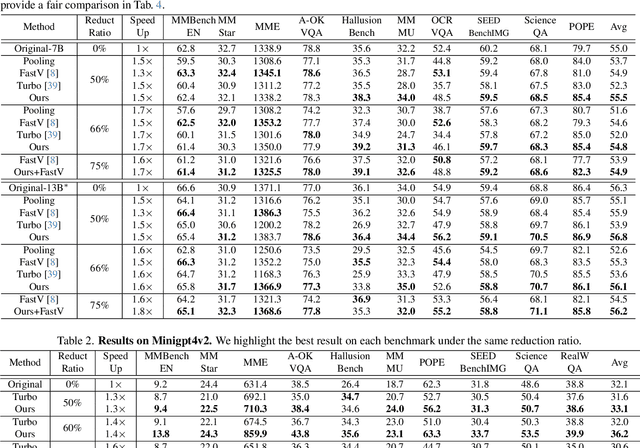
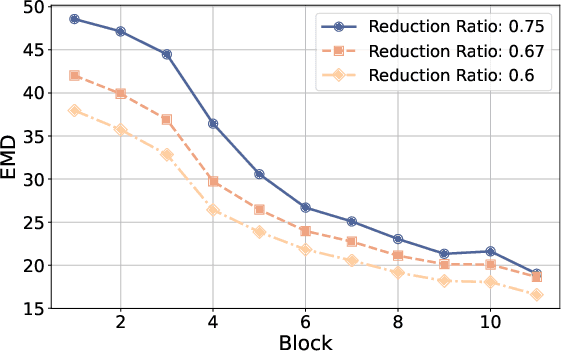
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.
Till the Layers Collapse: Compressing a Deep Neural Network through the Lenses of Batch Normalization Layers
Dec 19, 2024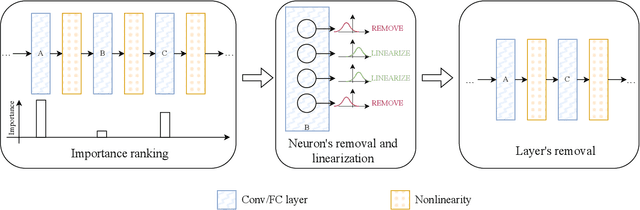
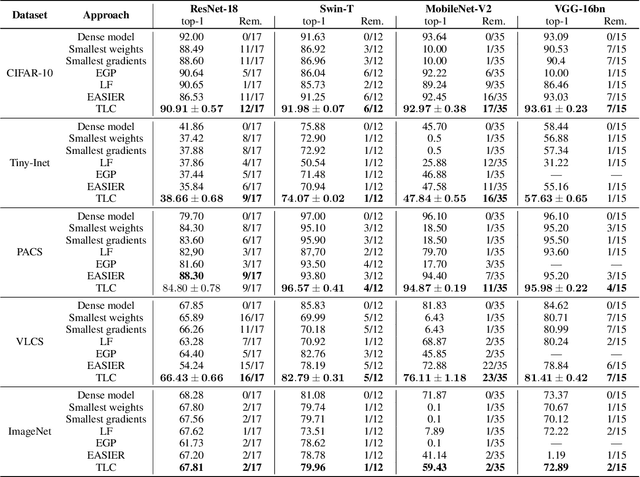
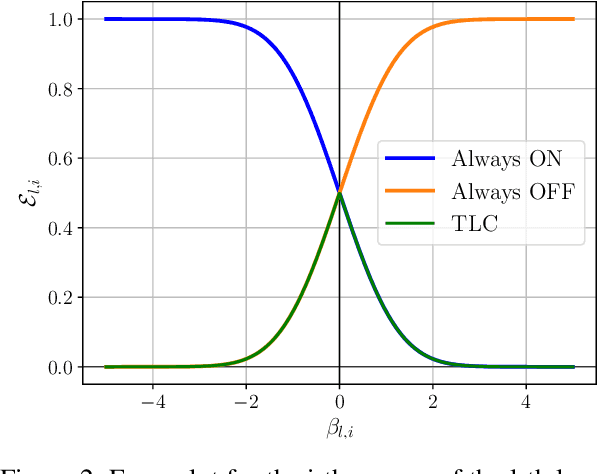
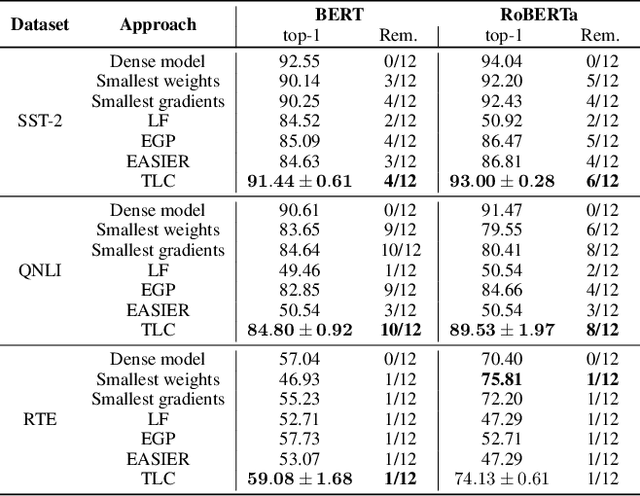
Today, deep neural networks are widely used since they can handle a variety of complex tasks. Their generality makes them very powerful tools in modern technology. However, deep neural networks are often overparameterized. The usage of these large models consumes a lot of computation resources. In this paper, we introduce a method called \textbf{T}ill the \textbf{L}ayers \textbf{C}ollapse (TLC), which compresses deep neural networks through the lenses of batch normalization layers. By reducing the depth of these networks, our method decreases deep neural networks' computational requirements and overall latency. We validate our method on popular models such as Swin-T, MobileNet-V2, and RoBERTa, across both image classification and natural language processing (NLP) tasks.
Memory-Optimized Once-For-All Network
Sep 05, 2024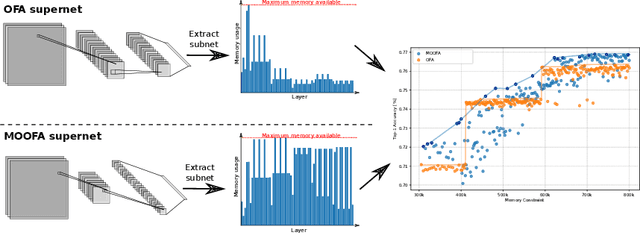



Deploying Deep Neural Networks (DNNs) on different hardware platforms is challenging due to varying resource constraints. Besides handcrafted approaches aiming at making deep models hardware-friendly, Neural Architectures Search is rising as a toolbox to craft more efficient DNNs without sacrificing performance. Among these, the Once-For-All (OFA) approach offers a solution by allowing the sampling of well-performing sub-networks from a single supernet -- this leads to evident advantages in terms of computation. However, OFA does not fully utilize the potential memory capacity of the target device, focusing instead on limiting maximum memory usage per layer. This leaves room for an unexploited potential in terms of model generalizability. In this paper, we introduce a Memory-Optimized OFA (MOOFA) supernet, designed to enhance DNN deployment on resource-limited devices by maximizing memory usage (and for instance, features diversity) across different configurations. Tested on ImageNet, our MOOFA supernet demonstrates improvements in memory exploitation and model accuracy compared to the original OFA supernet. Our code is available at https://github.com/MaximeGirard/memory-optimized-once-for-all.
LaCoOT: Layer Collapse through Optimal Transport
Jun 13, 2024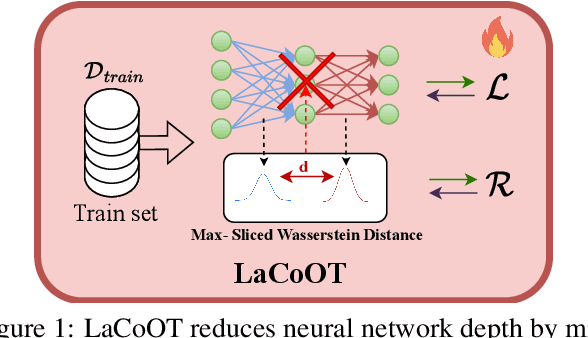
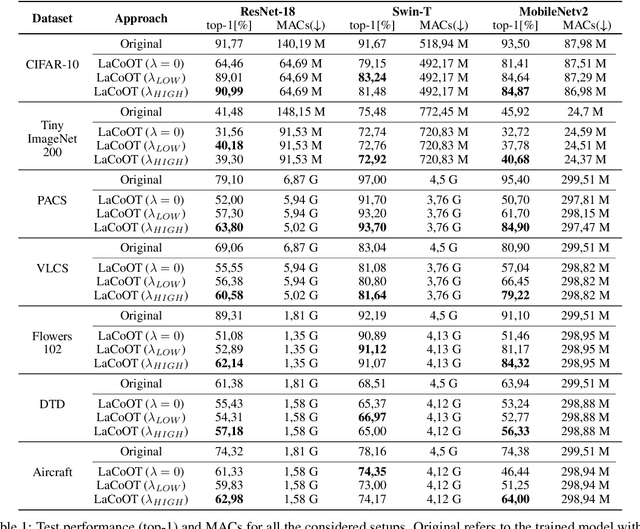
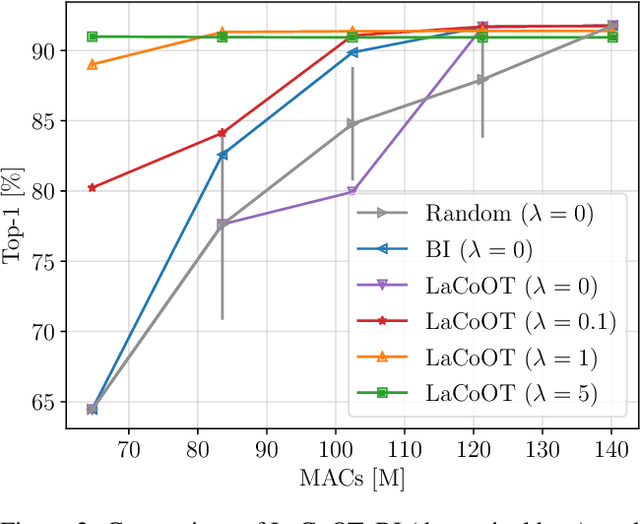
Although deep neural networks are well-known for their remarkable performance in tackling complex tasks, their hunger for computational resources remains a significant hurdle, posing energy-consumption issues and restricting their deployment on resource-constrained devices, which stalls their widespread adoption. In this paper, we present an optimal transport method to reduce the depth of over-parametrized deep neural networks, alleviating their computational burden. More specifically, we propose a new regularization strategy based on the Max-Sliced Wasserstein distance to minimize the distance between the intermediate feature distributions in the neural network. We show that minimizing this distance enables the complete removal of intermediate layers in the network, with almost no performance loss and without requiring any finetuning. We assess the effectiveness of our method on traditional image classification setups. We commit to releasing the source code upon acceptance of the article.
The Simpler The Better: An Entropy-Based Importance Metric To Reduce Neural Networks' Depth
Apr 27, 2024While deep neural networks are highly effective at solving complex tasks, large pre-trained models are commonly employed even to solve consistently simpler downstream tasks, which do not necessarily require a large model's complexity. Motivated by the awareness of the ever-growing AI environmental impact, we propose an efficiency strategy that leverages prior knowledge transferred by large models. Simple but effective, we propose a method relying on an Entropy-bASed Importance mEtRic (EASIER) to reduce the depth of over-parametrized deep neural networks, which alleviates their computational burden. We assess the effectiveness of our method on traditional image classification setups. The source code will be publicly released upon acceptance of the article.
NEPENTHE: Entropy-Based Pruning as a Neural Network Depth's Reducer
Apr 24, 2024



While deep neural networks are highly effective at solving complex tasks, their computational demands can hinder their usefulness in real-time applications and with limited-resources systems. Besides, for many tasks it is known that these models are over-parametrized: neoteric works have broadly focused on reducing the width of these networks, rather than their depth. In this paper, we aim to reduce the depth of over-parametrized deep neural networks: we propose an eNtropy-basEd Pruning as a nEural Network depTH's rEducer (NEPENTHE) to alleviate deep neural networks' computational burden. Based on our theoretical finding, NEPENTHE focuses on un-structurally pruning connections in layers with low entropy to remove them entirely. We validate our approach on popular architectures such as MobileNet and Swin-T, showing that when encountering an over-parametrization regime, it can effectively linearize some layers (hence reducing the model's depth) with little to no performance loss. The code will be publicly available upon acceptance of the article.
The Quest of Finding the Antidote to Sparse Double Descent
Aug 31, 2023In energy-efficient schemes, finding the optimal size of deep learning models is very important and has a broad impact. Meanwhile, recent studies have reported an unexpected phenomenon, the sparse double descent: as the model's sparsity increases, the performance first worsens, then improves, and finally deteriorates. Such a non-monotonic behavior raises serious questions about the optimal model's size to maintain high performance: the model needs to be sufficiently over-parametrized, but having too many parameters wastes training resources. In this paper, we aim to find the best trade-off efficiently. More precisely, we tackle the occurrence of the sparse double descent and present some solutions to avoid it. Firstly, we show that a simple $\ell_2$ regularization method can help to mitigate this phenomenon but sacrifices the performance/sparsity compromise. To overcome this problem, we then introduce a learning scheme in which distilling knowledge regularizes the student model. Supported by experimental results achieved using typical image classification setups, we show that this approach leads to the avoidance of such a phenomenon.
Can Unstructured Pruning Reduce the Depth in Deep Neural Networks?
Aug 18, 2023
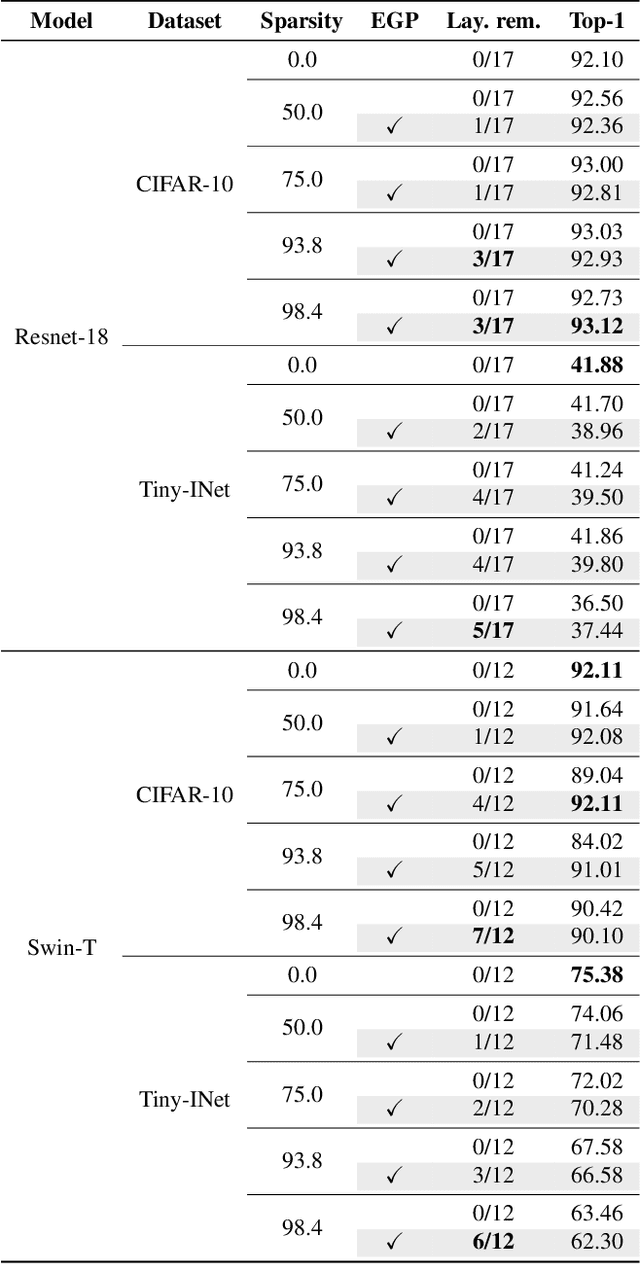
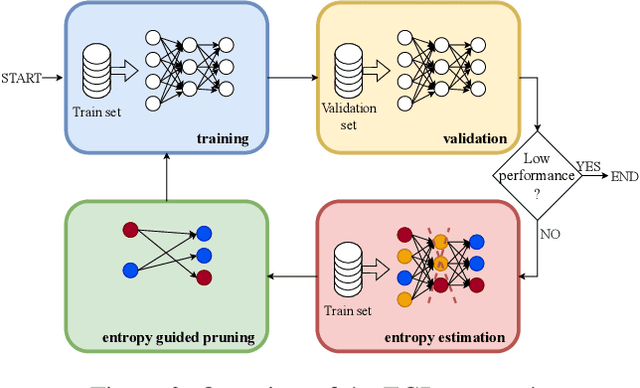

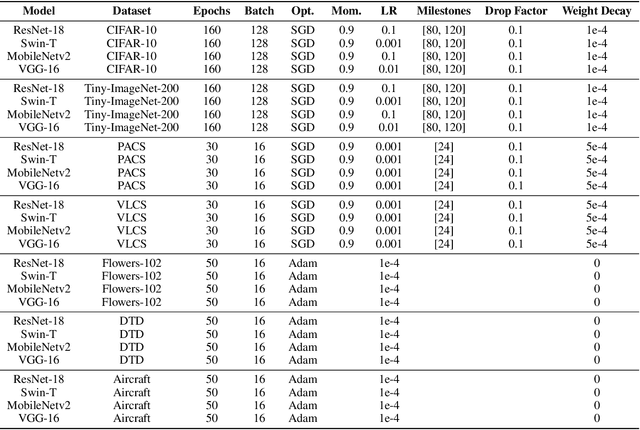
Pruning is a widely used technique for reducing the size of deep neural networks while maintaining their performance. However, such a technique, despite being able to massively compress deep models, is hardly able to remove entire layers from a model (even when structured): is this an addressable task? In this study, we introduce EGP, an innovative Entropy Guided Pruning algorithm aimed at reducing the size of deep neural networks while preserving their performance. The key focus of EGP is to prioritize pruning connections in layers with low entropy, ultimately leading to their complete removal. Through extensive experiments conducted on popular models like ResNet-18 and Swin-T, our findings demonstrate that EGP effectively compresses deep neural networks while maintaining competitive performance levels. Our results not only shed light on the underlying mechanism behind the advantages of unstructured pruning, but also pave the way for further investigations into the intricate relationship between entropy, pruning techniques, and deep learning performance. The EGP algorithm and its insights hold great promise for advancing the field of network compression and optimization. The source code for EGP is released open-source.
Sparse Double Descent in Vision Transformers: real or phantom threat?
Jul 26, 2023Vision transformers (ViT) have been of broad interest in recent theoretical and empirical works. They are state-of-the-art thanks to their attention-based approach, which boosts the identification of key features and patterns within images thanks to the capability of avoiding inductive bias, resulting in highly accurate image analysis. Meanwhile, neoteric studies have reported a ``sparse double descent'' phenomenon that can occur in modern deep-learning models, where extremely over-parametrized models can generalize well. This raises practical questions about the optimal size of the model and the quest over finding the best trade-off between sparsity and performance is launched: are Vision Transformers also prone to sparse double descent? Can we find a way to avoid such a phenomenon? Our work tackles the occurrence of sparse double descent on ViTs. Despite some works that have shown that traditional architectures, like Resnet, are condemned to the sparse double descent phenomenon, for ViTs we observe that an optimally-tuned $\ell_2$ regularization relieves such a phenomenon. However, everything comes at a cost: optimal lambda will sacrifice the potential compression of the ViT.
Dodging the Sparse Double Descent
Mar 02, 2023This paper presents an approach to addressing the issue of over-parametrization in deep neural networks, more specifically by avoiding the ``sparse double descent'' phenomenon. The authors propose a learning framework that allows avoidance of this phenomenon and improves generalization, an entropy measure to provide more insights on its insurgence, and provide a comprehensive quantitative analysis of various factors such as re-initialization methods, model width and depth, and dataset noise. The proposed approach is supported by experimental results achieved using typical adversarial learning setups. The source code to reproduce the experiments is provided in the supplementary materials and will be publicly released upon acceptance of the paper.