 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
Jan 05, 2025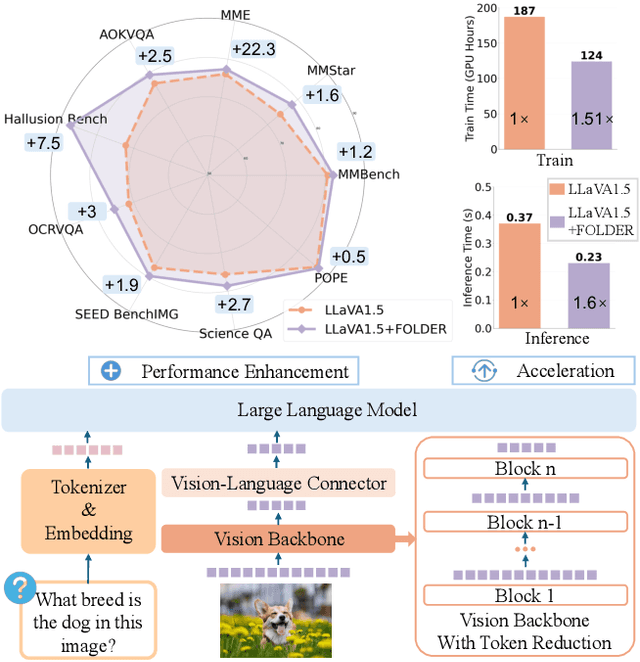
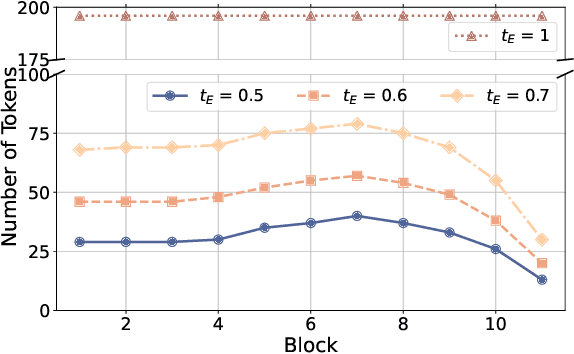
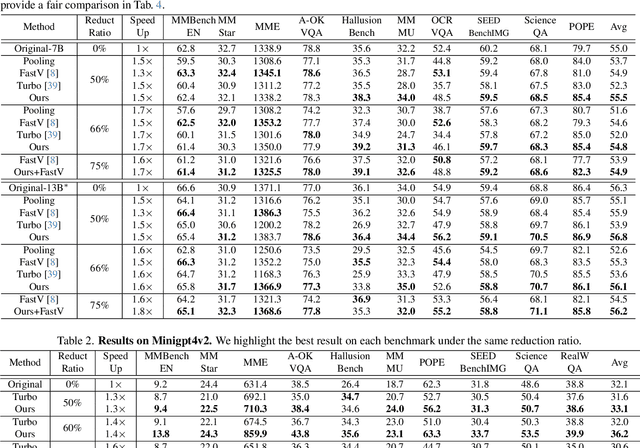
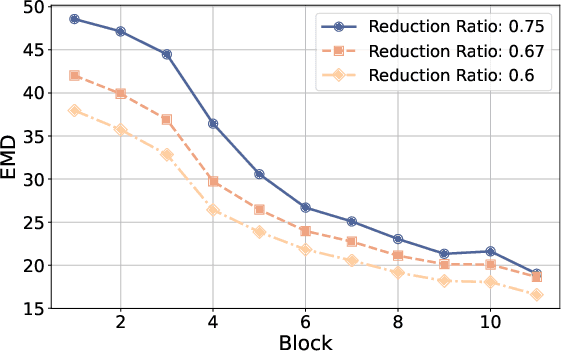
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.
GABIC: Graph-based Attention Block for Image Compression
Oct 03, 2024



While standardized codecs like JPEG and HEVC-intra represent the industry standard in image compression, neural Learned Image Compression (LIC) codecs represent a promising alternative. In detail, integrating attention mechanisms from Vision Transformers into LIC models has shown improved compression efficiency. However, extra efficiency often comes at the cost of aggregating redundant features. This work proposes a Graph-based Attention Block for Image Compression (GABIC), a method to reduce feature redundancy based on a k-Nearest Neighbors enhanced attention mechanism. Our experiments show that GABIC outperforms comparable methods, particularly at high bit rates, enhancing compression performance.
WiGNet: Windowed Vision Graph Neural Network
Oct 01, 2024



In recent years, Graph Neural Networks (GNNs) have demonstrated strong adaptability to various real-world challenges, with architectures such as Vision GNN (ViG) achieving state-of-the-art performance in several computer vision tasks. However, their practical applicability is hindered by the computational complexity of constructing the graph, which scales quadratically with the image size. In this paper, we introduce a novel Windowed vision Graph neural Network (WiGNet) model for efficient image processing. WiGNet explores a different strategy from previous works by partitioning the image into windows and constructing a graph within each window. Therefore, our model uses graph convolutions instead of the typical 2D convolution or self-attention mechanism. WiGNet effectively manages computational and memory complexity for large image sizes. We evaluate our method in the ImageNet-1k benchmark dataset and test the adaptability of WiGNet using the CelebA-HQ dataset as a downstream task with higher-resolution images. In both of these scenarios, our method achieves competitive results compared to previous vision GNNs while keeping memory and computational complexity at bay. WiGNet offers a promising solution toward the deployment of vision GNNs in real-world applications. We publicly released the code at https://github.com/EIDOSLAB/WiGNet.
Domain Adaptation for Learned Image Compression with Supervised Adapters
Apr 24, 2024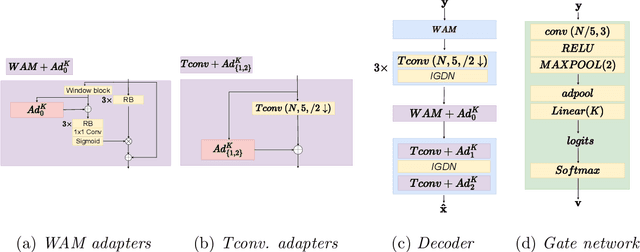
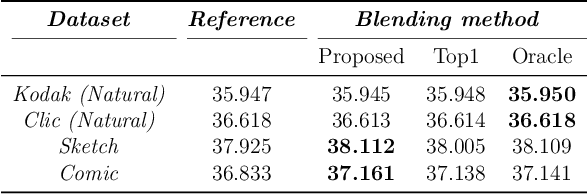
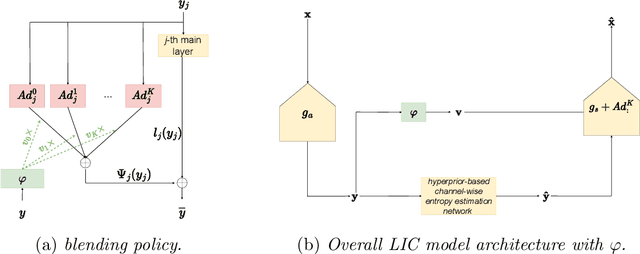

In Learned Image Compression (LIC), a model is trained at encoding and decoding images sampled from a source domain, often outperforming traditional codecs on natural images; yet its performance may be far from optimal on images sampled from different domains. In this work, we tackle the problem of adapting a pre-trained model to multiple target domains by plugging into the decoder an adapter module for each of them, including the source one. Each adapter improves the decoder performance on a specific domain, without the model forgetting about the images seen at training time. A gate network computes the weights to optimally blend the contributions from the adapters when the bitstream is decoded. We experimentally validate our method over two state-of-the-art pre-trained models, observing improved rate-distortion efficiency on the target domains without penalties on the source domain. Furthermore, the gate's ability to find similarities with the learned target domains enables better encoding efficiency also for images outside them.