 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRD Efficient FPGA Deployment of Learned Image Compression: Knowledge Distillation and Hybrid Quantization
Mar 05, 2025



Learnable Image Compression (LIC) has shown the potential to outperform standardized video codecs in RD efficiency, prompting the research for hardware-friendly implementations. Most existing LIC hardware implementations prioritize latency to RD-efficiency and through an extensive exploration of the hardware design space. We present a novel design paradigm where the burden of tuning the design for a specific hardware platform is shifted towards model dimensioning and without compromising on RD-efficiency. First, we design a framework for distilling a leaner student LIC model from a reference teacher: by tuning a single model hyperparameters, we can meet the constraints of different hardware platforms without a complex hardware design exploration. Second, we propose a hardware-friendly implementation of the Generalized Divisive Normalization (GDN) activation that preserves RD efficiency even post parameter quantization. Third, we design a pipelined FPGA configuration which takes full advantage of available FPGA resources by leveraging parallel processing and optimizing resource allocation. Our experiments with a state of the art LIC model show that we outperform all existing FPGA implementations while performing very close to the original model in terms of RD efficiency.
AA-SGAN: Adversarially Augmented Social GAN with Synthetic Data
Dec 23, 2024



Accurately predicting pedestrian trajectories is crucial in applications such as autonomous driving or service robotics, to name a few. Deep generative models achieve top performance in this task, assuming enough labelled trajectories are available for training. To this end, large amounts of synthetically generated, labelled trajectories exist (e.g., generated by video games). However, such trajectories are not meant to represent pedestrian motion realistically and are ineffective at training a predictive model. We propose a method and an architecture to augment synthetic trajectories at training time and with an adversarial approach. We show that trajectory augmentation at training time unleashes significant gains when a state-of-the-art generative model is evaluated over real-world trajectories.
Efficient Progressive Image Compression with Variance-aware Masking
Nov 15, 2024



Learned progressive image compression is gaining momentum as it allows improved image reconstruction as more bits are decoded at the receiver. We propose a progressive image compression method in which an image is first represented as a pair of base-quality and top-quality latent representations. Next, a residual latent representation is encoded as the element-wise difference between the top and base representations. Our scheme enables progressive image compression with element-wise granularity by introducing a masking system that ranks each element of the residual latent representation from most to least important, dividing it into complementary components, which can be transmitted separately to the decoder in order to obtain different reconstruction quality. The masking system does not add further parameters nor complexity. At the receiver, any elements of the top latent representation excluded from the transmitted components can be independently replaced with the mean predicted by the hyperprior architecture, ensuring reliable reconstructions at any intermediate quality level. We also introduced Rate Enhancement Modules (REMs), which refine the estimation of entropy parameters using already decoded components. We obtain results competitive with state-of-the-art competitors, while significantly reducing computational complexity, decoding time, and number of parameters.
GABIC: Graph-based Attention Block for Image Compression
Oct 03, 2024



While standardized codecs like JPEG and HEVC-intra represent the industry standard in image compression, neural Learned Image Compression (LIC) codecs represent a promising alternative. In detail, integrating attention mechanisms from Vision Transformers into LIC models has shown improved compression efficiency. However, extra efficiency often comes at the cost of aggregating redundant features. This work proposes a Graph-based Attention Block for Image Compression (GABIC), a method to reduce feature redundancy based on a k-Nearest Neighbors enhanced attention mechanism. Our experiments show that GABIC outperforms comparable methods, particularly at high bit rates, enhancing compression performance.
WiGNet: Windowed Vision Graph Neural Network
Oct 01, 2024



In recent years, Graph Neural Networks (GNNs) have demonstrated strong adaptability to various real-world challenges, with architectures such as Vision GNN (ViG) achieving state-of-the-art performance in several computer vision tasks. However, their practical applicability is hindered by the computational complexity of constructing the graph, which scales quadratically with the image size. In this paper, we introduce a novel Windowed vision Graph neural Network (WiGNet) model for efficient image processing. WiGNet explores a different strategy from previous works by partitioning the image into windows and constructing a graph within each window. Therefore, our model uses graph convolutions instead of the typical 2D convolution or self-attention mechanism. WiGNet effectively manages computational and memory complexity for large image sizes. We evaluate our method in the ImageNet-1k benchmark dataset and test the adaptability of WiGNet using the CelebA-HQ dataset as a downstream task with higher-resolution images. In both of these scenarios, our method achieves competitive results compared to previous vision GNNs while keeping memory and computational complexity at bay. WiGNet offers a promising solution toward the deployment of vision GNNs in real-world applications. We publicly released the code at https://github.com/EIDOSLAB/WiGNet.
STanH : Parametric Quantization for Variable Rate Learned Image Compression
Oct 01, 2024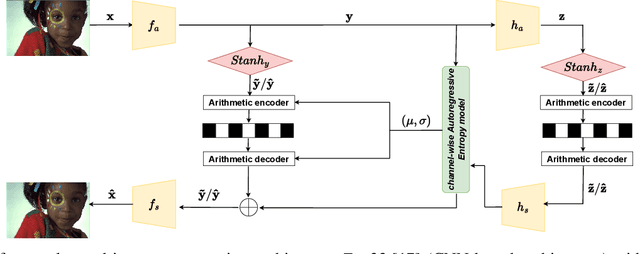
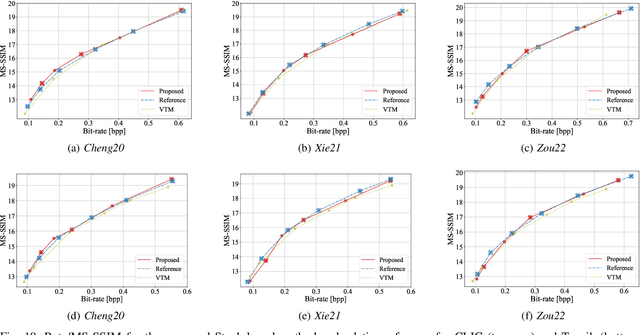


In end-to-end learned image compression, encoder and decoder are jointly trained to minimize a $R + {\lambda}D$ cost function, where ${\lambda}$ controls the trade-off between rate of the quantized latent representation and image quality. Unfortunately, a distinct encoder-decoder pair with millions of parameters must be trained for each ${\lambda}$, hence the need to switch encoders and to store multiple encoders and decoders on the user device for every target rate. This paper proposes to exploit a differentiable quantizer designed around a parametric sum of hyperbolic tangents, called STanH , that relaxes the step-wise quantization function. STanH is implemented as a differentiable activation layer with learnable quantization parameters that can be plugged into a pre-trained fixed rate model and refined to achieve different target bitrates. Experimental results show that our method enables variable rate coding with comparable efficiency to the state-of-the-art, yet with significant savings in terms of ease of deployment, training time, and storage costs
WaterMAS: Sharpness-Aware Maximization for Neural Network Watermarking
Sep 05, 2024
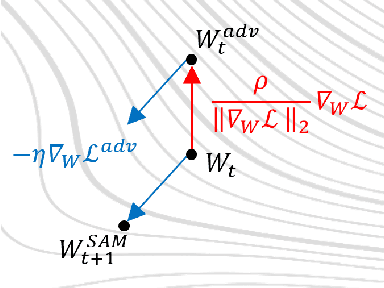


Nowadays, deep neural networks are used for solving complex tasks in several critical applications and protecting both their integrity and intellectual property rights (IPR) has become of utmost importance. To this end, we advance WaterMAS, a substitutive, white-box neural network watermarking method that improves the trade-off among robustness, imperceptibility, and computational complexity, while making provisions for increased data payload and security. WasterMAS insertion keeps unchanged the watermarked weights while sharpening their underlying gradient space. The robustness is thus ensured by limiting the attack's strength: even small alterations of the watermarked weights would impact the model's performance. The imperceptibility is ensured by inserting the watermark during the training process. The relationship among the WaterMAS data payload, imperceptibility, and robustness properties is discussed. The secret key is represented by the positions of the weights conveying the watermark, randomly chosen through multiple layers of the model. The security is evaluated by investigating the case in which an attacker would intercept the key. The experimental validations consider 5 models and 2 tasks (VGG16, ResNet18, MobileNetV3, SwinT for CIFAR10 image classification, and DeepLabV3 for Cityscapes image segmentation) as well as 4 types of attacks (Gaussian noise addition, pruning, fine-tuning, and quantization). The code will be released open-source upon acceptance of the article.
Say My Name: a Model's Bias Discovery Framework
Aug 18, 2024In the last few years, due to the broad applicability of deep learning to downstream tasks and end-to-end training capabilities, increasingly more concerns about potential biases to specific, non-representative patterns have been raised. Many works focusing on unsupervised debiasing usually leverage the tendency of deep models to learn ``easier'' samples, for example by clustering the latent space to obtain bias pseudo-labels. However, the interpretation of such pseudo-labels is not trivial, especially for a non-expert end user, as it does not provide semantic information about the bias features. To address this issue, we introduce ``Say My Name'' (SaMyNa), the first tool to identify biases within deep models semantically. Unlike existing methods, our approach focuses on biases learned by the model. Our text-based pipeline enhances explainability and supports debiasing efforts: applicable during either training or post-hoc validation, our method can disentangle task-related information and proposes itself as a tool to analyze biases. Evaluation on traditional benchmarks demonstrates its effectiveness in detecting biases and even disclaiming them, showcasing its broad applicability for model diagnosis.
Unsupervised Contrastive Analysis for Salient Pattern Detection using Conditional Diffusion Models
Jun 04, 2024



Contrastive Analysis (CA) regards the problem of identifying patterns in images that allow distinguishing between a background (BG) dataset (i.e. healthy subjects) and a target (TG) dataset (i.e. unhealthy subjects). Recent works on this topic rely on variational autoencoders (VAE) or contrastive learning strategies to learn the patterns that separate TG samples from BG samples in a supervised manner. However, the dependency on target (unhealthy) samples can be challenging in medical scenarios due to their limited availability. Also, the blurred reconstructions of VAEs lack utility and interpretability. In this work, we redefine the CA task by employing a self-supervised contrastive encoder to learn a latent representation encoding only common patterns from input images, using samples exclusively from the BG dataset during training, and approximating the distribution of the target patterns by leveraging data augmentation techniques. Subsequently, we exploit state-of-the-art generative methods, i.e. diffusion models, conditioned on the learned latent representation to produce a realistic (healthy) version of the input image encoding solely the common patterns. Thorough validation on a facial image dataset and experiments across three brain MRI datasets demonstrate that conditioning the generative process of state-of-the-art generative methods with the latent representation from our self-supervised contrastive encoder yields improvements in the generated image quality and in the accuracy of image classification. The code is available at https://github.com/CristianoPatricio/unsupervised-contrastive-cond-diff.
Domain Adaptation for Learned Image Compression with Supervised Adapters
Apr 24, 2024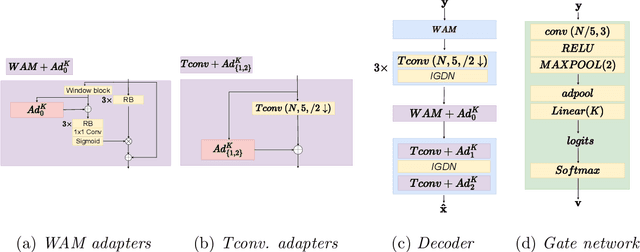
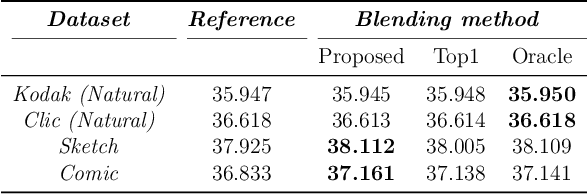
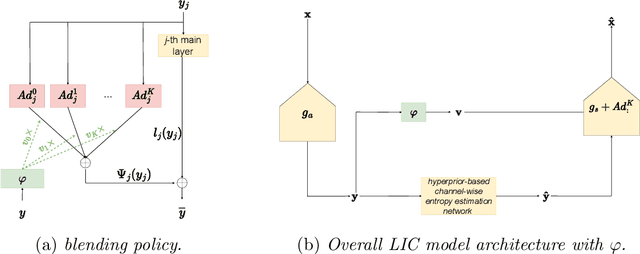

In Learned Image Compression (LIC), a model is trained at encoding and decoding images sampled from a source domain, often outperforming traditional codecs on natural images; yet its performance may be far from optimal on images sampled from different domains. In this work, we tackle the problem of adapting a pre-trained model to multiple target domains by plugging into the decoder an adapter module for each of them, including the source one. Each adapter improves the decoder performance on a specific domain, without the model forgetting about the images seen at training time. A gate network computes the weights to optimally blend the contributions from the adapters when the bitstream is decoded. We experimentally validate our method over two state-of-the-art pre-trained models, observing improved rate-distortion efficiency on the target domains without penalties on the source domain. Furthermore, the gate's ability to find similarities with the learned target domains enables better encoding efficiency also for images outside them.