 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting the Lottery: Adaptive Subnetworks for Heterogeneous Data
Jan 29, 2026In pruning, the Lottery Ticket Hypothesis posits that large networks contain sparse subnetworks, or winning tickets, that can be trained in isolation to match the performance of their dense counterparts. However, most existing approaches assume a single universal winning ticket shared across all inputs, ignoring the inherent heterogeneity of real-world data. In this work, we propose Routing the Lottery (RTL), an adaptive pruning framework that discovers multiple specialized subnetworks, called adaptive tickets, each tailored to a class, semantic cluster, or environmental condition. Across diverse datasets and tasks, RTL consistently outperforms single- and multi-model baselines in balanced accuracy and recall, while using up to 10 times fewer parameters than independent models and exhibiting semantically aligned. Furthermore, we identify subnetwork collapse, a performance drop under aggressive pruning, and introduce a subnetwork similarity score that enables label-free diagnosis of oversparsification. Overall, our results recast pruning as a mechanism for aligning model structure with data heterogeneity, paving the way toward more modular and context-aware deep learning.
Efficient Progressive Image Compression with Variance-aware Masking
Nov 15, 2024



Learned progressive image compression is gaining momentum as it allows improved image reconstruction as more bits are decoded at the receiver. We propose a progressive image compression method in which an image is first represented as a pair of base-quality and top-quality latent representations. Next, a residual latent representation is encoded as the element-wise difference between the top and base representations. Our scheme enables progressive image compression with element-wise granularity by introducing a masking system that ranks each element of the residual latent representation from most to least important, dividing it into complementary components, which can be transmitted separately to the decoder in order to obtain different reconstruction quality. The masking system does not add further parameters nor complexity. At the receiver, any elements of the top latent representation excluded from the transmitted components can be independently replaced with the mean predicted by the hyperprior architecture, ensuring reliable reconstructions at any intermediate quality level. We also introduced Rate Enhancement Modules (REMs), which refine the estimation of entropy parameters using already decoded components. We obtain results competitive with state-of-the-art competitors, while significantly reducing computational complexity, decoding time, and number of parameters.
GABIC: Graph-based Attention Block for Image Compression
Oct 03, 2024



While standardized codecs like JPEG and HEVC-intra represent the industry standard in image compression, neural Learned Image Compression (LIC) codecs represent a promising alternative. In detail, integrating attention mechanisms from Vision Transformers into LIC models has shown improved compression efficiency. However, extra efficiency often comes at the cost of aggregating redundant features. This work proposes a Graph-based Attention Block for Image Compression (GABIC), a method to reduce feature redundancy based on a k-Nearest Neighbors enhanced attention mechanism. Our experiments show that GABIC outperforms comparable methods, particularly at high bit rates, enhancing compression performance.
Can We Remove the Ground? Obstacle-aware Point Cloud Compression for Remote Object Detection
Oct 01, 2024
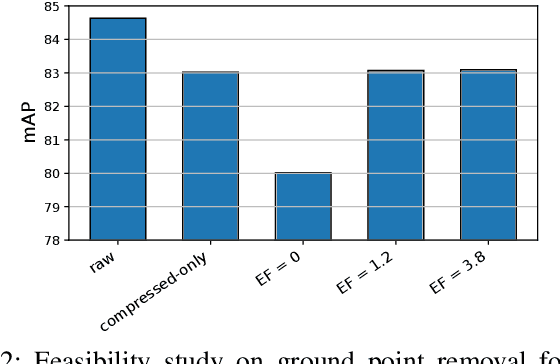
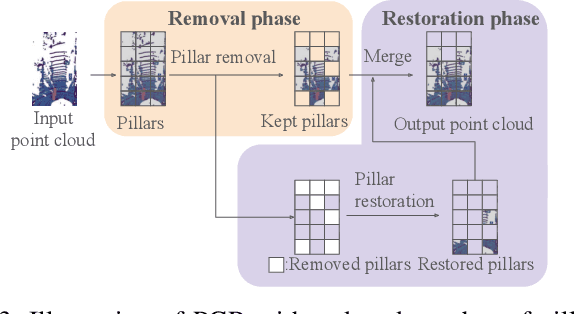
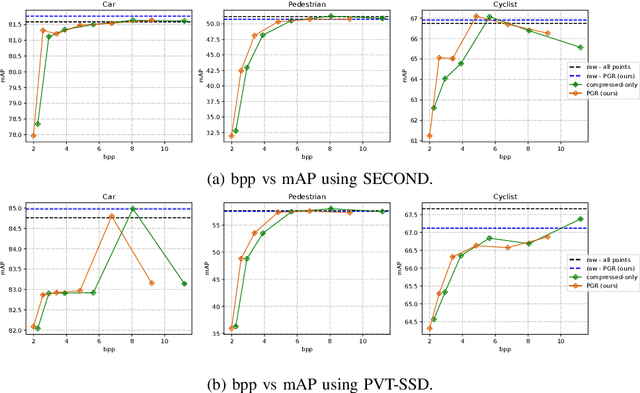
Efficient point cloud (PC) compression is crucial for streaming applications, such as augmented reality and cooperative perception. Classic PC compression techniques encode all the points in a frame. Tailoring compression towards perception tasks at the receiver side, we ask the question, "Can we remove the ground points during transmission without sacrificing the detection performance?" Our study reveals a strong dependency on the ground from state-of-the-art (SOTA) 3D object detection models, especially on those points below and around the object. In this work, we propose a lightweight obstacle-aware Pillar-based Ground Removal (PGR) algorithm. PGR filters out ground points that do not provide context to object recognition, significantly improving compression ratio without sacrificing the receiver side perception performance. Not using heavy object detection or semantic segmentation models, PGR is light-weight, highly parallelizable, and effective. Our evaluations on KITTI and Waymo Open Dataset show that SOTA detection models work equally well with PGR removing 20-30% of the points, with a speeding of 86 FPS.
STanH : Parametric Quantization for Variable Rate Learned Image Compression
Oct 01, 2024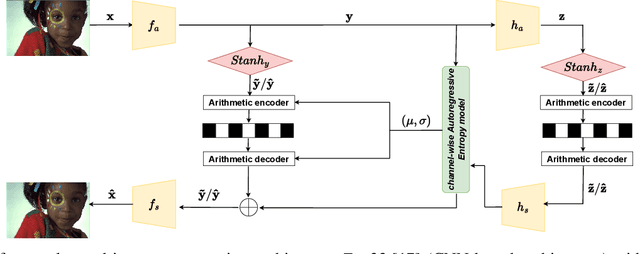


In end-to-end learned image compression, encoder and decoder are jointly trained to minimize a $R + {\lambda}D$ cost function, where ${\lambda}$ controls the trade-off between rate of the quantized latent representation and image quality. Unfortunately, a distinct encoder-decoder pair with millions of parameters must be trained for each ${\lambda}$, hence the need to switch encoders and to store multiple encoders and decoders on the user device for every target rate. This paper proposes to exploit a differentiable quantizer designed around a parametric sum of hyperbolic tangents, called STanH , that relaxes the step-wise quantization function. STanH is implemented as a differentiable activation layer with learnable quantization parameters that can be plugged into a pre-trained fixed rate model and refined to achieve different target bitrates. Experimental results show that our method enables variable rate coding with comparable efficiency to the state-of-the-art, yet with significant savings in terms of ease of deployment, training time, and storage costs
Domain Adaptation for Learned Image Compression with Supervised Adapters
Apr 24, 2024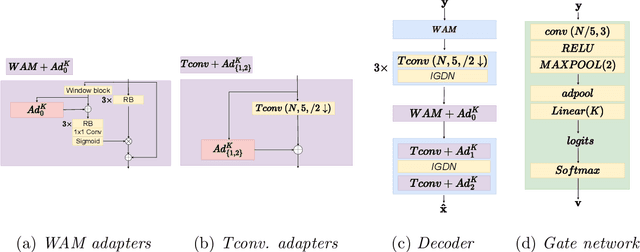
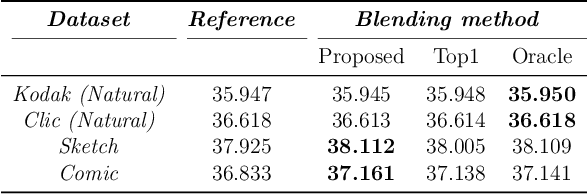
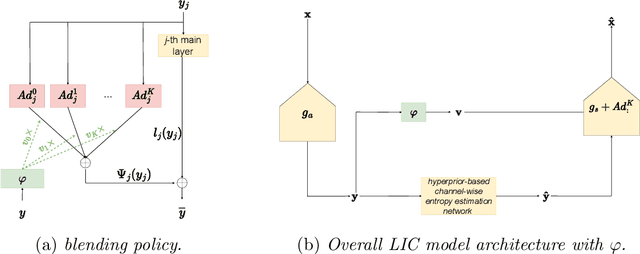

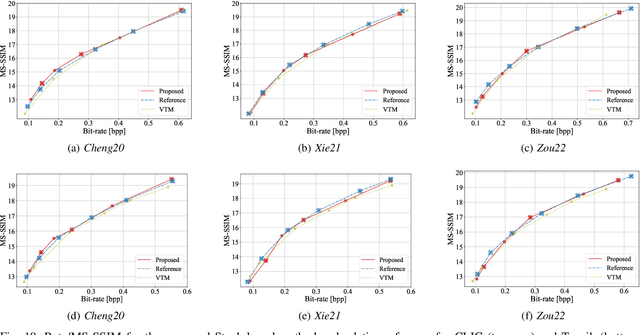
In Learned Image Compression (LIC), a model is trained at encoding and decoding images sampled from a source domain, often outperforming traditional codecs on natural images; yet its performance may be far from optimal on images sampled from different domains. In this work, we tackle the problem of adapting a pre-trained model to multiple target domains by plugging into the decoder an adapter module for each of them, including the source one. Each adapter improves the decoder performance on a specific domain, without the model forgetting about the images seen at training time. A gate network computes the weights to optimally blend the contributions from the adapters when the bitstream is decoded. We experimentally validate our method over two state-of-the-art pre-trained models, observing improved rate-distortion efficiency on the target domains without penalties on the source domain. Furthermore, the gate's ability to find similarities with the learned target domains enables better encoding efficiency also for images outside them.
Detection of subclinical atherosclerosis by image-based deep learning on chest x-ray
Mar 27, 2024



Aims. To develop a deep-learning based system for recognition of subclinical atherosclerosis on a plain frontal chest x-ray. Methods and Results. A deep-learning algorithm to predict coronary artery calcium (CAC) score (the AI-CAC model) was developed on 460 chest x-ray (80% training cohort, 20% internal validation cohort) of primary prevention patients (58.4% male, median age 63 [51-74] years) with available paired chest x-ray and chest computed tomography (CT) indicated for any clinical reason and performed within 3 months. The CAC score calculated on chest CT was used as ground truth. The model was validated on an temporally-independent cohort of 90 patients from the same institution (external validation). The diagnostic accuracy of the AI-CAC model assessed by the area under the curve (AUC) was the primary outcome. Overall, median AI-CAC score was 35 (0-388) and 28.9% patients had no AI-CAC. AUC of the AI-CAC model to identify a CAC>0 was 0.90 in the internal validation cohort and 0.77 in the external validation cohort. Sensitivity was consistently above 92% in both cohorts. In the overall cohort (n=540), among patients with AI-CAC=0, a single ASCVD event occurred, after 4.3 years. Patients with AI-CAC>0 had significantly higher Kaplan Meier estimates for ASCVD events (13.5% vs. 3.4%, log-rank=0.013). Conclusion. The AI-CAC model seems to accurately detect subclinical atherosclerosis on chest x-ray with elevated sensitivity, and to predict ASCVD events with elevated negative predictive value. Adoption of the AI-CAC model to refine CV risk stratification or as an opportunistic screening tool requires prospective evaluation.