 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Dataset Generation and Validation for Robotic Surgery Instrument Segmentation
Feb 14, 2026This paper presents a comprehensive workflow for generating and validating a synthetic dataset designed for robotic surgery instrument segmentation. A 3D reconstruction of the Da Vinci robotic arms was refined and animated in Autodesk Maya through a fully automated Python-based pipeline capable of producing photorealistic, labeled video sequences. Each scene integrates randomized motion patterns, lighting variations, and synthetic blood textures to mimic intraoperative variability while preserving pixel-accurate ground truth masks. To validate the realism and effectiveness of the generated data, several segmentation models were trained under controlled ratios of real and synthetic data. Results demonstrate that a balanced composition of real and synthetic samples significantly improves model generalization compared to training on real data only, while excessive reliance on synthetic data introduces a measurable domain shift. The proposed framework provides a reproducible and scalable tool for surgical computer vision, supporting future research in data augmentation, domain adaptation, and simulation-based pretraining for robotic-assisted surgery. Data and code are available at https://github.com/EIDOSLAB/Sintetic-dataset-DaVinci.
Automated Prediction of Paravalvular Regurgitation before Transcatheter Aortic Valve Implantation
Feb 14, 2026Severe aortic stenosis is a common and life-threatening condition in elderly patients, often treated with Transcatheter Aortic Valve Implantation (TAVI). Despite procedural advances, paravalvular aortic regurgitation (PVR) remains one of the most frequent post-TAVI complications, with a proven impact on long-term prognosis. In this work, we investigate the potential of deep learning to predict the occurrence of PVR from preoperative cardiac CT. To this end, a dataset of preoperative TAVI patients was collected, and 3D convolutional neural networks were trained on isotropic CT volumes. The results achieved suggest that volumetric deep learning can capture subtle anatomical features from pre-TAVI imaging, opening new perspectives for personalized risk assessment and procedural optimization. Source code is available at https://github.com/EIDOSLAB/tavi.
Cardiac Output Prediction from Echocardiograms: Self-Supervised Learning with Limited Data
Feb 14, 2026Cardiac Output (CO) is a key parameter in the diagnosis and management of cardiovascular diseases. However, its accurate measurement requires right-heart catheterization, an invasive and time-consuming procedure, motivating the development of reliable non-invasive alternatives using echocardiography. In this work, we propose a self-supervised learning (SSL) pretraining strategy based on SimCLR to improve CO prediction from apical four-chamber echocardiographic videos. The pretraining is performed using the same limited dataset available for the downstream task, demonstrating the potential of SSL even under data scarcity. Our results show that SSL mitigates overfitting and improves representation learning, achieving an average Pearson correlation of 0.41 on the test set and outperforming PanEcho, a model trained on over one million echocardiographic exams. Source code is available at https://github.com/EIDOSLAB/cardiac-output.
Spherical Voronoi: Directional Appearance as a Differentiable Partition of the Sphere
Dec 16, 2025
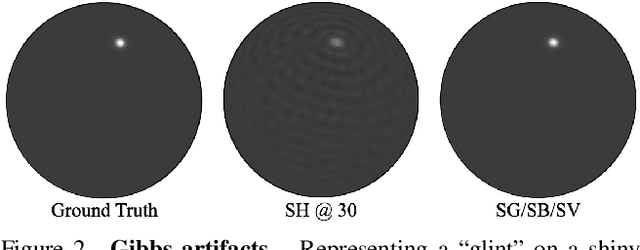
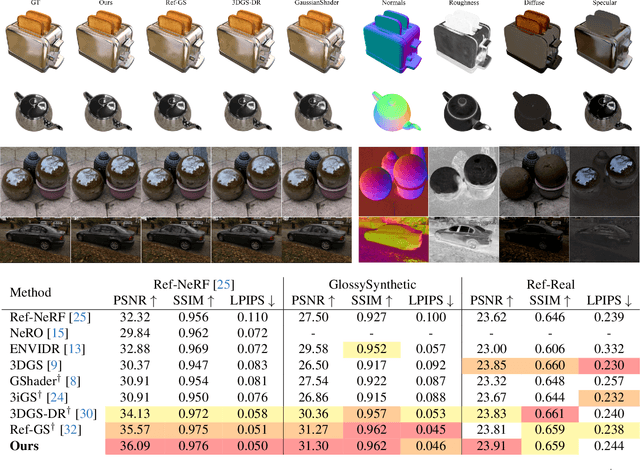
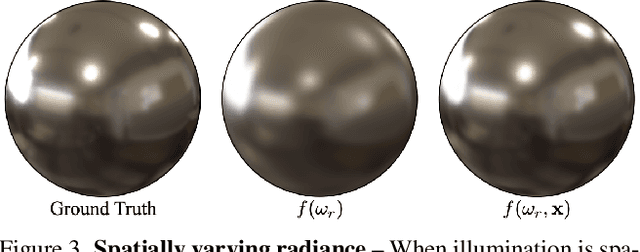
Radiance field methods (e.g. 3D Gaussian Splatting) have emerged as a powerful paradigm for novel view synthesis, yet their appearance modeling often relies on Spherical Harmonics (SH), which impose fundamental limitations. SH struggle with high-frequency signals, exhibit Gibbs ringing artifacts, and fail to capture specular reflections - a key component of realistic rendering. Although alternatives like spherical Gaussians offer improvements, they add significant optimization complexity. We propose Spherical Voronoi (SV) as a unified framework for appearance representation in 3D Gaussian Splatting. SV partitions the directional domain into learnable regions with smooth boundaries, providing an intuitive and stable parameterization for view-dependent effects. For diffuse appearance, SV achieves competitive results while keeping optimization simpler than existing alternatives. For reflections - where SH fail - we leverage SV as learnable reflection probes, taking reflected directions as input following principles from classical graphics. This formulation attains state-of-the-art results on synthetic and real-world datasets, demonstrating that SV offers a principled, efficient, and general solution for appearance modeling in explicit 3D representations.
MedSAE: Dissecting MedCLIP Representations with Sparse Autoencoders
Oct 30, 2025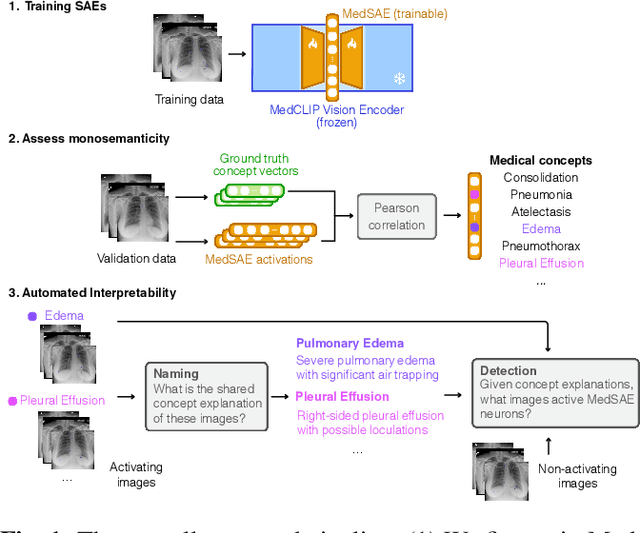
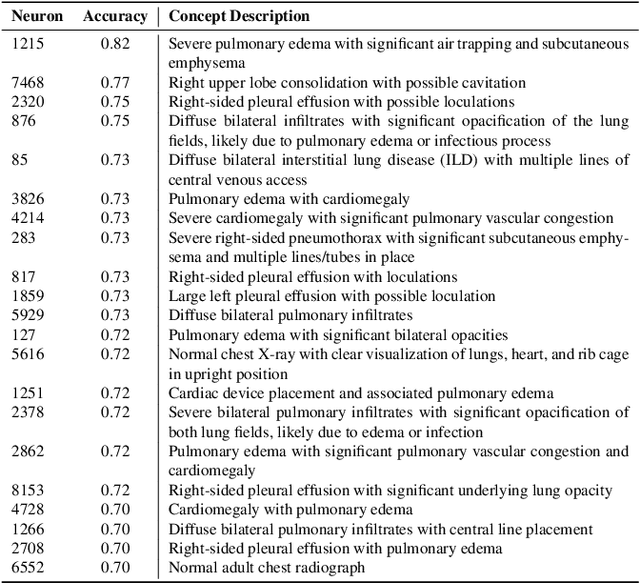
Artificial intelligence in healthcare requires models that are accurate and interpretable. We advance mechanistic interpretability in medical vision by applying Medical Sparse Autoencoders (MedSAEs) to the latent space of MedCLIP, a vision-language model trained on chest radiographs and reports. To quantify interpretability, we propose an evaluation framework that combines correlation metrics, entropy analyzes, and automated neuron naming via the MedGEMMA foundation model. Experiments on the CheXpert dataset show that MedSAE neurons achieve higher monosemanticity and interpretability than raw MedCLIP features. Our findings bridge high-performing medical AI and transparency, offering a scalable step toward clinically reliable representations.
When Does Pruning Benefit Vision Representations?
Jul 02, 2025



Pruning is widely used to reduce the complexity of deep learning models, but its effects on interpretability and representation learning remain poorly understood. This paper investigates how pruning influences vision models across three key dimensions: (i) interpretability, (ii) unsupervised object discovery, and (iii) alignment with human perception. We first analyze different vision network architectures to examine how varying sparsity levels affect feature attribution interpretability methods. Additionally, we explore whether pruning promotes more succinct and structured representations, potentially improving unsupervised object discovery by discarding redundant information while preserving essential features. Finally, we assess whether pruning enhances the alignment between model representations and human perception, investigating whether sparser models focus on more discriminative features similarly to humans. Our findings also reveal the presence of sweet spots, where sparse models exhibit higher interpretability, downstream generalization and human alignment. However, these spots highly depend on the network architectures and their size in terms of trainable parameters. Our results suggest a complex interplay between these three dimensions, highlighting the importance of investigating when and how pruning benefits vision representations.
Robust brain age estimation from structural MRI with contrastive learning
Jul 02, 2025Estimating brain age from structural MRI has emerged as a powerful tool for characterizing normative and pathological aging. In this work, we explore contrastive learning as a scalable and robust alternative to supervised approaches for brain age estimation. We introduce a novel contrastive loss function, $\mathcal{L}^{exp}$, and evaluate it across multiple public neuroimaging datasets comprising over 20,000 scans. Our experiments reveal four key findings. First, scaling pre-training on diverse, multi-site data consistently improves generalization performance, cutting external mean absolute error (MAE) nearly in half. Second, $\mathcal{L}^{exp}$ is robust to site-related confounds, maintaining low scanner-predictability as training size increases. Third, contrastive models reliably capture accelerated aging in patients with cognitive impairment and Alzheimer's disease, as shown through brain age gap analysis, ROC curves, and longitudinal trends. Lastly, unlike supervised baselines, $\mathcal{L}^{exp}$ maintains a strong correlation between brain age accuracy and downstream diagnostic performance, supporting its potential as a foundation model for neuroimaging. These results position contrastive learning as a promising direction for building generalizable and clinically meaningful brain representations.
AA-SGAN: Adversarially Augmented Social GAN with Synthetic Data
Dec 23, 2024



Accurately predicting pedestrian trajectories is crucial in applications such as autonomous driving or service robotics, to name a few. Deep generative models achieve top performance in this task, assuming enough labelled trajectories are available for training. To this end, large amounts of synthetically generated, labelled trajectories exist (e.g., generated by video games). However, such trajectories are not meant to represent pedestrian motion realistically and are ineffective at training a predictive model. We propose a method and an architecture to augment synthetic trajectories at training time and with an adversarial approach. We show that trajectory augmentation at training time unleashes significant gains when a state-of-the-art generative model is evaluated over real-world trajectories.
Knowledge Transfer Across Modalities with Natural Language Supervision
Nov 23, 2024
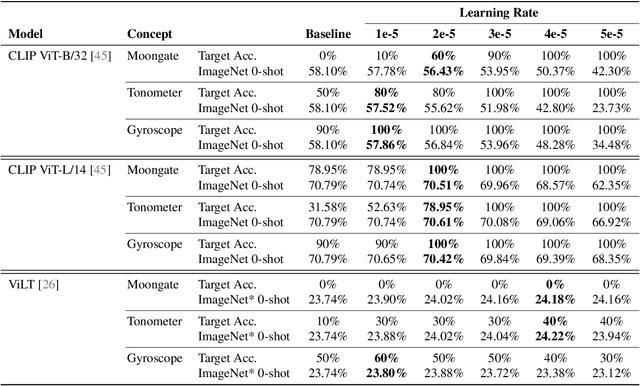
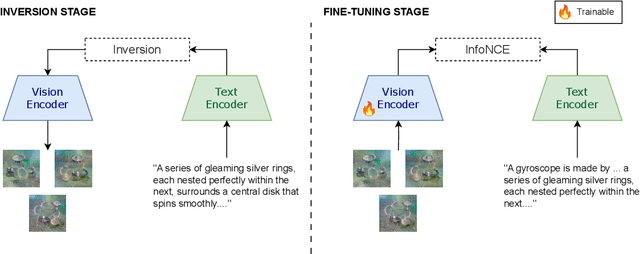
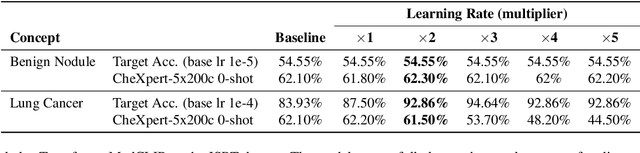
We present a way to learn novel concepts by only using their textual description. We call this method Knowledge Transfer. Similarly to human perception, we leverage cross-modal interaction to introduce new concepts. We hypothesize that in a pre-trained visual encoder there are enough low-level features already learned (e.g. shape, appearance, color) that can be used to describe previously unknown high-level concepts. Provided with a textual description of the novel concept, our method works by aligning the known low-level features of the visual encoder to its high-level textual description. We show that Knowledge Transfer can successfully introduce novel concepts in multimodal models, in a very efficient manner, by only requiring a single description of the target concept. Our approach is compatible with both separate textual and visual encoders (e.g. CLIP) and shared parameters across modalities. We also show that, following the same principle, Knowledge Transfer can improve concepts already known by the model. Leveraging Knowledge Transfer we improve zero-shot performance across different tasks such as classification, segmentation, image-text retrieval, and captioning.
Efficient Progressive Image Compression with Variance-aware Masking
Nov 15, 2024



Learned progressive image compression is gaining momentum as it allows improved image reconstruction as more bits are decoded at the receiver. We propose a progressive image compression method in which an image is first represented as a pair of base-quality and top-quality latent representations. Next, a residual latent representation is encoded as the element-wise difference between the top and base representations. Our scheme enables progressive image compression with element-wise granularity by introducing a masking system that ranks each element of the residual latent representation from most to least important, dividing it into complementary components, which can be transmitted separately to the decoder in order to obtain different reconstruction quality. The masking system does not add further parameters nor complexity. At the receiver, any elements of the top latent representation excluded from the transmitted components can be independently replaced with the mean predicted by the hyperprior architecture, ensuring reliable reconstructions at any intermediate quality level. We also introduced Rate Enhancement Modules (REMs), which refine the estimation of entropy parameters using already decoded components. We obtain results competitive with state-of-the-art competitors, while significantly reducing computational complexity, decoding time, and number of parameters.