 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer Across Modalities with Natural Language Supervision
Paper and Code

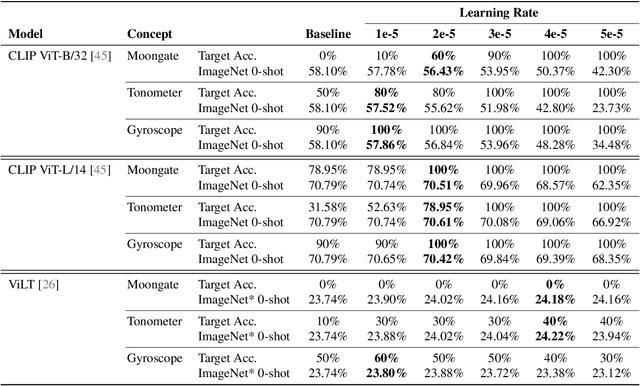
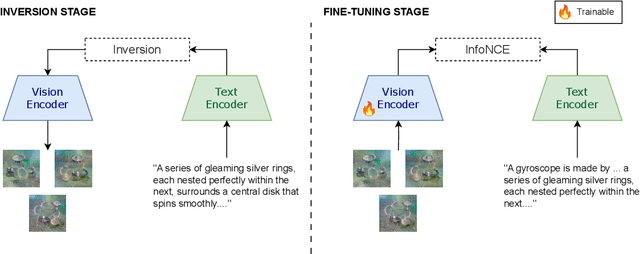
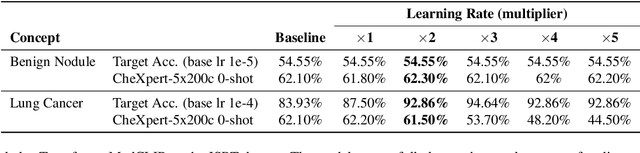
We present a way to learn novel concepts by only using their textual description. We call this method Knowledge Transfer. Similarly to human perception, we leverage cross-modal interaction to introduce new concepts. We hypothesize that in a pre-trained visual encoder there are enough low-level features already learned (e.g. shape, appearance, color) that can be used to describe previously unknown high-level concepts. Provided with a textual description of the novel concept, our method works by aligning the known low-level features of the visual encoder to its high-level textual description. We show that Knowledge Transfer can successfully introduce novel concepts in multimodal models, in a very efficient manner, by only requiring a single description of the target concept. Our approach is compatible with both separate textual and visual encoders (e.g. CLIP) and shared parameters across modalities. We also show that, following the same principle, Knowledge Transfer can improve concepts already known by the model. Leveraging Knowledge Transfer we improve zero-shot performance across different tasks such as classification, segmentation, image-text retrieval, and captioning.