 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer Across Modalities with Natural Language Supervision
Nov 23, 2024
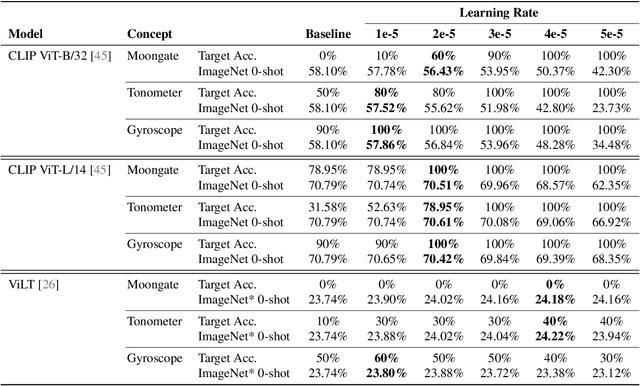
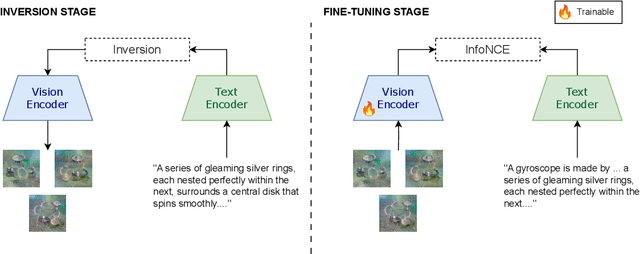
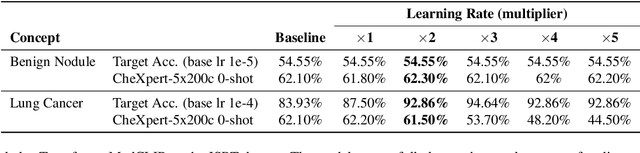
We present a way to learn novel concepts by only using their textual description. We call this method Knowledge Transfer. Similarly to human perception, we leverage cross-modal interaction to introduce new concepts. We hypothesize that in a pre-trained visual encoder there are enough low-level features already learned (e.g. shape, appearance, color) that can be used to describe previously unknown high-level concepts. Provided with a textual description of the novel concept, our method works by aligning the known low-level features of the visual encoder to its high-level textual description. We show that Knowledge Transfer can successfully introduce novel concepts in multimodal models, in a very efficient manner, by only requiring a single description of the target concept. Our approach is compatible with both separate textual and visual encoders (e.g. CLIP) and shared parameters across modalities. We also show that, following the same principle, Knowledge Transfer can improve concepts already known by the model. Leveraging Knowledge Transfer we improve zero-shot performance across different tasks such as classification, segmentation, image-text retrieval, and captioning.
Say My Name: a Model's Bias Discovery Framework
Aug 18, 2024In the last few years, due to the broad applicability of deep learning to downstream tasks and end-to-end training capabilities, increasingly more concerns about potential biases to specific, non-representative patterns have been raised. Many works focusing on unsupervised debiasing usually leverage the tendency of deep models to learn ``easier'' samples, for example by clustering the latent space to obtain bias pseudo-labels. However, the interpretation of such pseudo-labels is not trivial, especially for a non-expert end user, as it does not provide semantic information about the bias features. To address this issue, we introduce ``Say My Name'' (SaMyNa), the first tool to identify biases within deep models semantically. Unlike existing methods, our approach focuses on biases learned by the model. Our text-based pipeline enhances explainability and supports debiasing efforts: applicable during either training or post-hoc validation, our method can disentangle task-related information and proposes itself as a tool to analyze biases. Evaluation on traditional benchmarks demonstrates its effectiveness in detecting biases and even disclaiming them, showcasing its broad applicability for model diagnosis.