 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSAE: Dissecting MedCLIP Representations with Sparse Autoencoders
Oct 30, 2025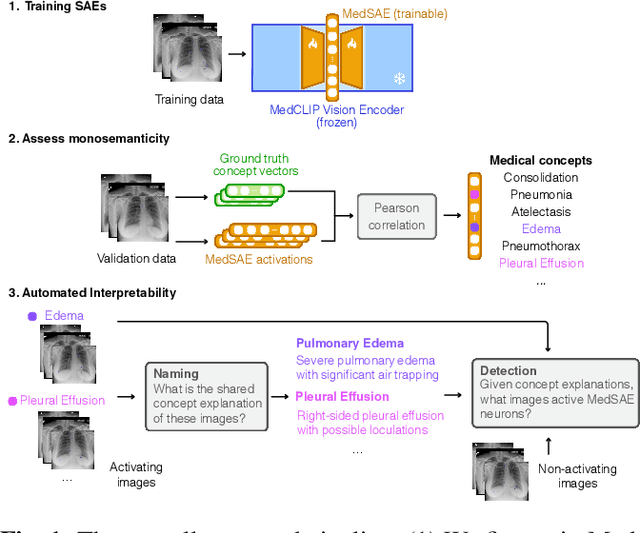
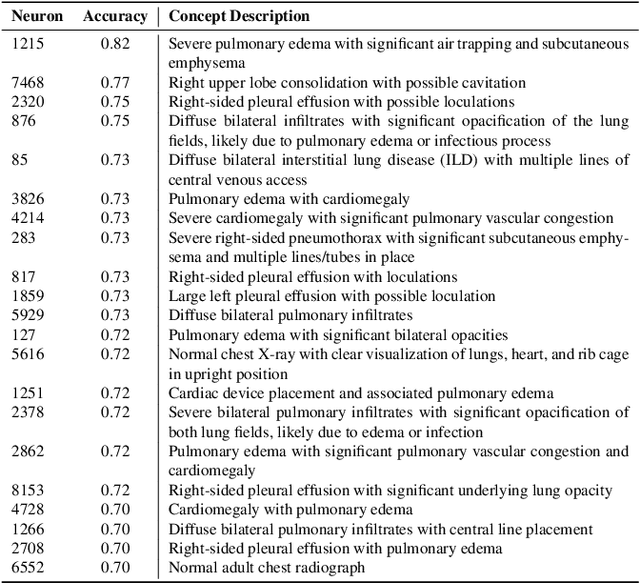
Artificial intelligence in healthcare requires models that are accurate and interpretable. We advance mechanistic interpretability in medical vision by applying Medical Sparse Autoencoders (MedSAEs) to the latent space of MedCLIP, a vision-language model trained on chest radiographs and reports. To quantify interpretability, we propose an evaluation framework that combines correlation metrics, entropy analyzes, and automated neuron naming via the MedGEMMA foundation model. Experiments on the CheXpert dataset show that MedSAE neurons achieve higher monosemanticity and interpretability than raw MedCLIP features. Our findings bridge high-performing medical AI and transparency, offering a scalable step toward clinically reliable representations.
When Does Pruning Benefit Vision Representations?
Jul 02, 2025Pruning is widely used to reduce the complexity of deep learning models, but its effects on interpretability and representation learning remain poorly understood. This paper investigates how pruning influences vision models across three key dimensions: (i) interpretability, (ii) unsupervised object discovery, and (iii) alignment with human perception. We first analyze different vision network architectures to examine how varying sparsity levels affect feature attribution interpretability methods. Additionally, we explore whether pruning promotes more succinct and structured representations, potentially improving unsupervised object discovery by discarding redundant information while preserving essential features. Finally, we assess whether pruning enhances the alignment between model representations and human perception, investigating whether sparser models focus on more discriminative features similarly to humans. Our findings also reveal the presence of sweet spots, where sparse models exhibit higher interpretability, downstream generalization and human alignment. However, these spots highly depend on the network architectures and their size in terms of trainable parameters. Our results suggest a complex interplay between these three dimensions, highlighting the importance of investigating when and how pruning benefits vision representations.
Boost Your NeRF: A Model-Agnostic Mixture of Experts Framework for High Quality and Efficient Rendering
Jul 15, 2024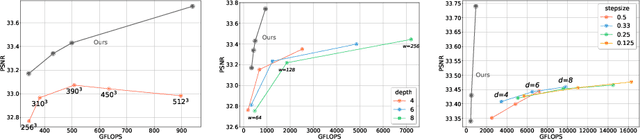


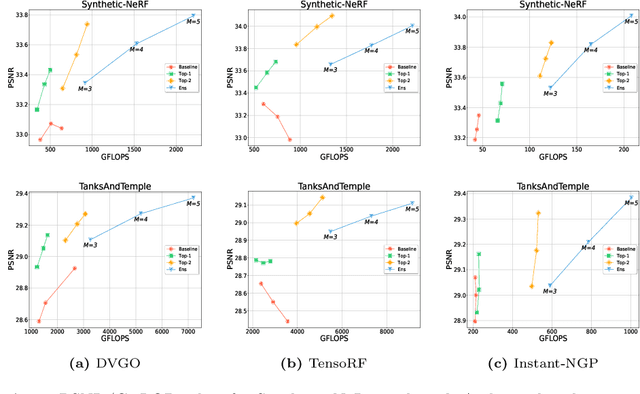
Since the introduction of NeRFs, considerable attention has been focused on improving their training and inference times, leading to the development of Fast-NeRFs models. Despite demonstrating impressive rendering speed and quality, the rapid convergence of such models poses challenges for further improving reconstruction quality. Common strategies to improve rendering quality involves augmenting model parameters or increasing the number of sampled points. However, these computationally intensive approaches encounter limitations in achieving significant quality enhancements. This study introduces a model-agnostic framework inspired by Sparsely-Gated Mixture of Experts to enhance rendering quality without escalating computational complexity. Our approach enables specialization in rendering different scene components by employing a mixture of experts with varying resolutions. We present a novel gate formulation designed to maximize expert capabilities and propose a resolution-based routing technique to effectively induce sparsity and decompose scenes. Our work significantly improves reconstruction quality while maintaining competitive performance.
Unsupervised Contrastive Analysis for Salient Pattern Detection using Conditional Diffusion Models
Jun 04, 2024



Contrastive Analysis (CA) regards the problem of identifying patterns in images that allow distinguishing between a background (BG) dataset (i.e. healthy subjects) and a target (TG) dataset (i.e. unhealthy subjects). Recent works on this topic rely on variational autoencoders (VAE) or contrastive learning strategies to learn the patterns that separate TG samples from BG samples in a supervised manner. However, the dependency on target (unhealthy) samples can be challenging in medical scenarios due to their limited availability. Also, the blurred reconstructions of VAEs lack utility and interpretability. In this work, we redefine the CA task by employing a self-supervised contrastive encoder to learn a latent representation encoding only common patterns from input images, using samples exclusively from the BG dataset during training, and approximating the distribution of the target patterns by leveraging data augmentation techniques. Subsequently, we exploit state-of-the-art generative methods, i.e. diffusion models, conditioned on the learned latent representation to produce a realistic (healthy) version of the input image encoding solely the common patterns. Thorough validation on a facial image dataset and experiments across three brain MRI datasets demonstrate that conditioning the generative process of state-of-the-art generative methods with the latent representation from our self-supervised contrastive encoder yields improvements in the generated image quality and in the accuracy of image classification. The code is available at https://github.com/CristianoPatricio/unsupervised-contrastive-cond-diff.
Hierarchical Object-Centric Learning with Capsule Networks
May 30, 2024



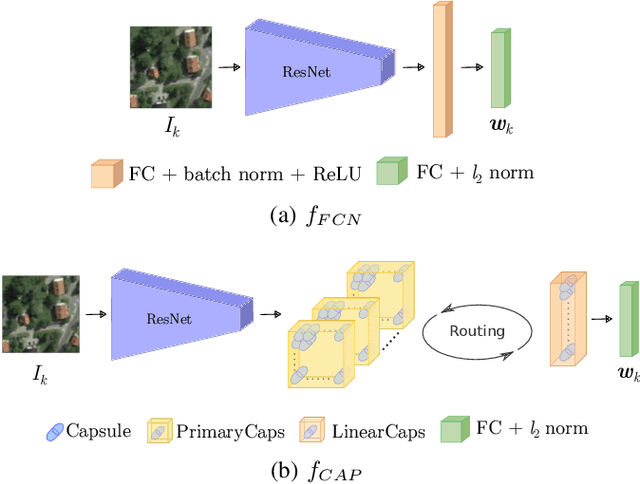
Capsule networks (CapsNets) were introduced to address convolutional neural networks limitations, learning object-centric representations that are more robust, pose-aware, and interpretable. They organize neurons into groups called capsules, where each capsule encodes the instantiation parameters of an object or one of its parts. Moreover, a routing algorithm connects capsules in different layers, thereby capturing hierarchical part-whole relationships in the data. This thesis investigates the intriguing aspects of CapsNets and focuses on three key questions to unlock their full potential. First, we explore the effectiveness of the routing algorithm, particularly in small-sized networks. We propose a novel method that anneals the number of routing iterations during training, enhancing performance in architectures with fewer parameters. Secondly, we investigate methods to extract more effective first-layer capsules, also known as primary capsules. By exploiting pruned backbones, we aim to improve computational efficiency by reducing the number of capsules while achieving high generalization. This approach reduces CapsNets memory requirements and computational effort. Third, we explore part-relationship learning in CapsNets. Through extensive research, we demonstrate that capsules with low entropy can extract more concise and discriminative part-whole relationships compared to traditional capsule networks, even with reasonable network sizes. Lastly, we showcase how CapsNets can be utilized in real-world applications, including autonomous localization of unmanned aerial vehicles, quaternion-based rotations prediction in synthetic datasets, and lung nodule segmentation in biomedical imaging. The findings presented in this thesis contribute to a deeper understanding of CapsNets and highlight their potential to address complex computer vision challenges.
AI-Assisted Diagnosis for Covid-19 CXR Screening: From Data Collection to Clinical Validation
May 19, 2024


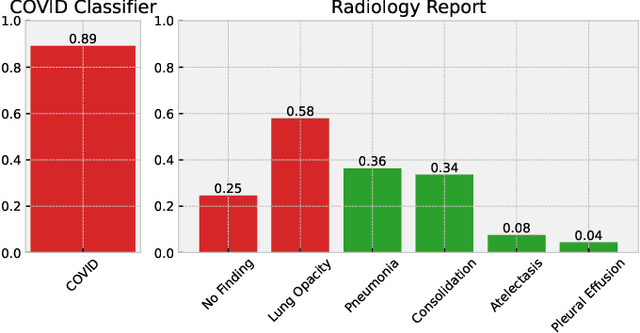
In this paper, we present the major results from the Covid Radiographic imaging System based on AI (Co.R.S.A.) project, which took place in Italy. This project aims to develop a state-of-the-art AI-based system for diagnosing Covid-19 pneumonia from Chest X-ray (CXR) images. The contributions of this work are manyfold: the release of the public CORDA dataset, a deep learning pipeline for Covid-19 detection, and the clinical validation of the developed solution by expert radiologists. The proposed detection model is based on a two-step approach that, paired with state-of-the-art debiasing, provides reliable results. Most importantly, our investigation includes the actual usage of the diagnosis aid tool by radiologists, allowing us to assess the real benefits in terms of accuracy and time efficiency. Project homepage: https://corsa.di.unito.it/
LSVL: Large-scale season-invariant visual localization for UAVs
Dec 07, 2022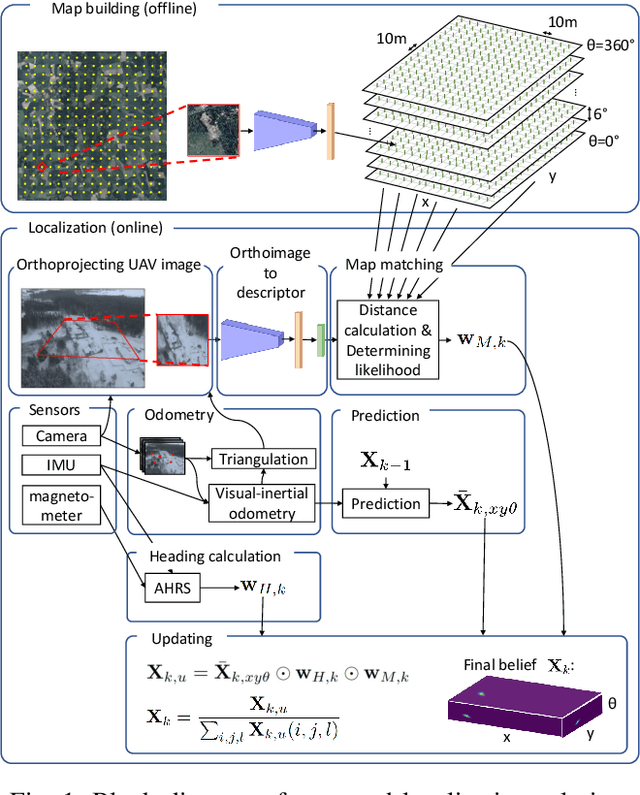
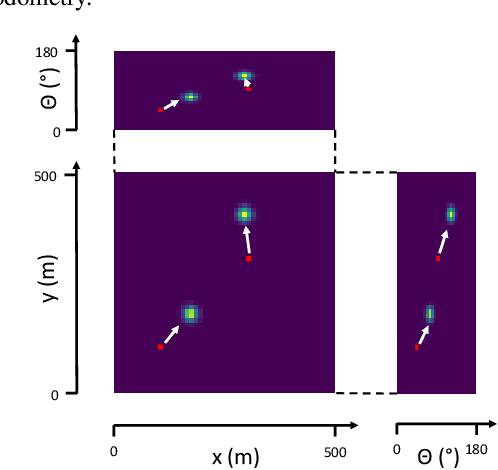
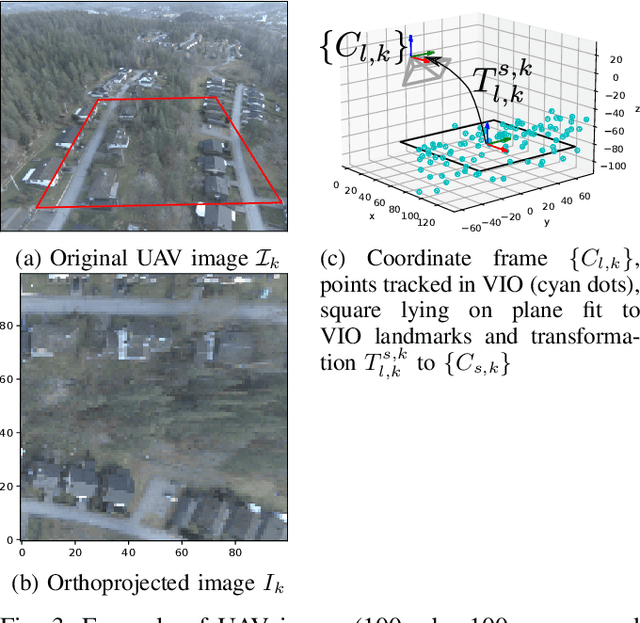
Localization of autonomous unmanned aerial vehicles (UAVs) relies heavily on Global Navigation Satellite Systems (GNSS), which are susceptible to interference. Especially in security applications, robust localization algorithms independent of GNSS are needed to provide dependable operations of autonomous UAVs also in interfered conditions. Typical non-GNSS visual localization approaches rely on known starting pose, work only on a small-sized map, or require known flight paths before a mission starts. We consider the problem of localization with no information on initial pose or planned flight path. We propose a solution for global visual localization on a map at scale up to 100 km2, based on matching orthoprojected UAV images to satellite imagery using learned season-invariant descriptors. We show that the method is able to determine heading, latitude and longitude of the UAV at 12.6-18.7 m lateral translation error in as few as 23.2-44.4 updates from an uninformed initialization, also in situations of significant seasonal appearance difference (winter-summer) between the UAV image and the map. We evaluate the characteristics of multiple neural network architectures for generating the descriptors, and likelihood estimation methods that are able to provide fast convergence and low localization error. We also evaluate the operation of the algorithm using real UAV data and evaluate running time on a real-time embedded platform. We believe this is the first work that is able to recover the pose of an UAV at this scale and rate of convergence, while allowing significant seasonal difference between camera observations and map.
Towards Efficient Capsule Networks
Aug 19, 2022



From the moment Neural Networks dominated the scene for image processing, the computational complexity needed to solve the targeted tasks skyrocketed: against such an unsustainable trend, many strategies have been developed, ambitiously targeting performance's preservation. Promoting sparse topologies, for example, allows the deployment of deep neural networks models on embedded, resource-constrained devices. Recently, Capsule Networks were introduced to enhance explainability of a model, where each capsule is an explicit representation of an object or its parts. These models show promising results on toy datasets, but their low scalability prevents deployment on more complex tasks. In this work, we explore sparsity besides capsule representations to improve their computational efficiency by reducing the number of capsules. We show how pruning with Capsule Network achieves high generalization with less memory requirements, computational effort, and inference and training time.
Lung nodules segmentation from CT with DeepHealth toolkit
Aug 01, 2022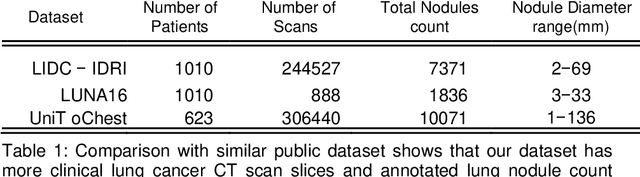
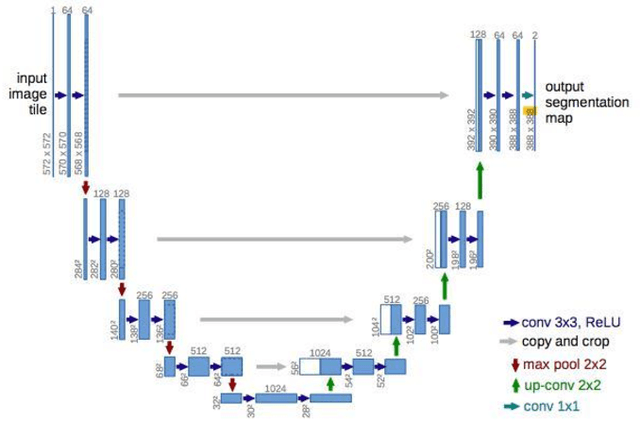

The accurate and consistent border segmentation plays an important role in the tumor volume estimation and its treatment in the field of Medical Image Segmentation. Globally, Lung cancer is one of the leading causes of death and the early detection of lung nodules is essential for the early cancer diagnosis and survival rate of patients. The goal of this study was to demonstrate the feasibility of Deephealth toolkit including PyECVL and PyEDDL libraries to precisely segment lung nodules. Experiments for lung nodules segmentation has been carried out on UniToChest using PyECVL and PyEDDL, for data pre-processing as well as neural network training. The results depict accurate segmentation of lung nodules across a wide diameter range and better accuracy over a traditional detection approach. The datasets and the code used in this paper are publicly available as a baseline reference.
REM: Routing Entropy Minimization for Capsule Networks
Apr 04, 2022

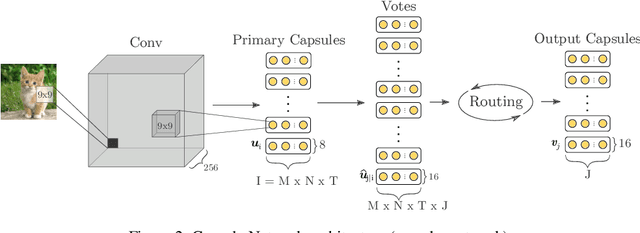

Capsule Networks ambition is to build an explainable and biologically-inspired neural network model. One of their main innovations relies on the routing mechanism which extracts a parse tree: its main purpose is to explicitly build relationships between capsules. However, their true potential in terms of explainability has not surfaced yet: these relationships are extremely heterogeneous and difficult to understand. This paper proposes REM, a technique which minimizes the entropy of the parse tree-like structure, improving its explainability. We accomplish this by driving the model parameters distribution towards low entropy configurations, using a pruning mechanism as a proxy. We also generate static parse trees with no performance loss, showing that, with REM, Capsule Networks build stronger relationships between capsules.