 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFD-MAD: Frequency-Domain Residual Analysis for Face Morphing Attack Detection
Jan 28, 2026Face morphing attacks present a significant threat to face recognition systems used in electronic identity enrolment and border control, particularly in single-image morphing attack detection (S-MAD) scenarios where no trusted reference is available. In spite of the vast amount of research on this problem, morph detection systems struggle in cross-dataset scenarios. To address this problem, we introduce a region-aware frequency-based morph detection strategy that drastically improves over strong baseline methods in challenging cross-dataset and cross-morph settings using a lightweight approach. Having observed the separability of bona fide and morph samples in the frequency domain of different facial parts, our approach 1) introduces the concept of residual frequency domain, where the frequency of the signal is decoupled from the natural spectral decay to easily discriminate between morph and bona fide data; 2) additionally, we reason in a global and local manner by combining the evidence from different facial regions in a Markov Random Field, which infers a globally consistent decision. The proposed method, trained exclusively on the synthetic morphing attack detection development dataset (SMDD), is evaluated in challenging cross-dataset and cross-morph settings on FRLL-Morph and MAD22 sets. Our approach achieves an average equal error rate (EER) of 1.85\% on FRLL-Morph and ranks second on MAD22 with an average EER of 6.12\%, while also obtaining a good bona fide presentation classification error rate (BPCER) at a low attack presentation classification error rate (APCER) using only spectral features. These findings indicate that Fourier-domain residual modeling with structured regional fusion offers a competitive alternative to deep S-MAD architectures.
SortWaste: A Densely Annotated Dataset for Object Detection in Industrial Waste Sorting
Jan 07, 2026The increasing production of waste, driven by population growth, has created challenges in managing and recycling materials effectively. Manual waste sorting is a common practice; however, it remains inefficient for handling large-scale waste streams and presents health risks for workers. On the other hand, existing automated sorting approaches still struggle with the high variability, clutter, and visual complexity of real-world waste streams. The lack of real-world datasets for waste sorting is a major reason automated systems for this problem are underdeveloped. Accordingly, we introduce SortWaste, a densely annotated object detection dataset collected from a Material Recovery Facility. Additionally, we contribute to standardizing waste detection in sorting lines by proposing ClutterScore, an objective metric that gauges the scene's hardness level using a set of proxies that affect visual complexity (e.g., object count, class and size entropy, and spatial overlap). In addition to these contributions, we provide an extensive benchmark of state-of-the-art object detection models, detailing their results with respect to the hardness level assessed by the proposed metric. Despite achieving promising results (mAP of 59.7% in the plastic-only detection task), performance significantly decreases in highly cluttered scenes. This highlights the need for novel and more challenging datasets on the topic.
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Jan 21, 2025



The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
A Two-Step Concept-Based Approach for Enhanced Interpretability and Trust in Skin Lesion Diagnosis
Nov 08, 2024The main challenges hindering the adoption of deep learning-based systems in clinical settings are the scarcity of annotated data and the lack of interpretability and trust in these systems. Concept Bottleneck Models (CBMs) offer inherent interpretability by constraining the final disease prediction on a set of human-understandable concepts. However, this inherent interpretability comes at the cost of greater annotation burden. Additionally, adding new concepts requires retraining the entire system. In this work, we introduce a novel two-step methodology that addresses both of these challenges. By simulating the two stages of a CBM, we utilize a pretrained Vision Language Model (VLM) to automatically predict clinical concepts, and a Large Language Model (LLM) to generate disease diagnoses based on the predicted concepts. We validate our approach on three skin lesion datasets, demonstrating that it outperforms traditional CBMs and state-of-the-art explainable methods, all without requiring any training and utilizing only a few annotated examples. The code is available at https://github.com/CristianoPatricio/2-step-concept-based-skin-diagnosis.
Multi-Feature Aggregation in Diffusion Models for Enhanced Face Super-Resolution
Aug 27, 2024


Super-resolution algorithms often struggle with images from surveillance environments due to adverse conditions such as unknown degradation, variations in pose, irregular illumination, and occlusions. However, acquiring multiple images, even of low quality, is possible with surveillance cameras. In this work, we develop an algorithm based on diffusion models that utilize a low-resolution image combined with features extracted from multiple low-quality images to generate a super-resolved image while minimizing distortions in the individual's identity. Unlike other algorithms, our approach recovers facial features without explicitly providing attribute information or without the need to calculate a gradient of a function during the reconstruction process. To the best of our knowledge, this is the first time multi-features combined with low-resolution images are used as conditioners to generate more reliable super-resolution images using stochastic differential equations. The FFHQ dataset was employed for training, resulting in state-of-the-art performance in facial recognition and verification metrics when evaluated on the CelebA and Quis-Campi datasets. Our code is publicly available at https://github.com/marcelowds/fasr
Unsupervised Contrastive Analysis for Salient Pattern Detection using Conditional Diffusion Models
Jun 04, 2024



Contrastive Analysis (CA) regards the problem of identifying patterns in images that allow distinguishing between a background (BG) dataset (i.e. healthy subjects) and a target (TG) dataset (i.e. unhealthy subjects). Recent works on this topic rely on variational autoencoders (VAE) or contrastive learning strategies to learn the patterns that separate TG samples from BG samples in a supervised manner. However, the dependency on target (unhealthy) samples can be challenging in medical scenarios due to their limited availability. Also, the blurred reconstructions of VAEs lack utility and interpretability. In this work, we redefine the CA task by employing a self-supervised contrastive encoder to learn a latent representation encoding only common patterns from input images, using samples exclusively from the BG dataset during training, and approximating the distribution of the target patterns by leveraging data augmentation techniques. Subsequently, we exploit state-of-the-art generative methods, i.e. diffusion models, conditioned on the learned latent representation to produce a realistic (healthy) version of the input image encoding solely the common patterns. Thorough validation on a facial image dataset and experiments across three brain MRI datasets demonstrate that conditioning the generative process of state-of-the-art generative methods with the latent representation from our self-supervised contrastive encoder yields improvements in the generated image quality and in the accuracy of image classification. The code is available at https://github.com/CristianoPatricio/unsupervised-contrastive-cond-diff.
Towards Concept-based Interpretability of Skin Lesion Diagnosis using Vision-Language Models
Nov 24, 2023Concept-based models naturally lend themselves to the development of inherently interpretable skin lesion diagnosis, as medical experts make decisions based on a set of visual patterns of the lesion. Nevertheless, the development of these models depends on the existence of concept-annotated datasets, whose availability is scarce due to the specialized knowledge and expertise required in the annotation process. In this work, we show that vision-language models can be used to alleviate the dependence on a large number of concept-annotated samples. In particular, we propose an embedding learning strategy to adapt CLIP to the downstream task of skin lesion classification using concept-based descriptions as textual embeddings. Our experiments reveal that vision-language models not only attain better accuracy when using concepts as textual embeddings, but also require a smaller number of concept-annotated samples to attain comparable performance to approaches specifically devised for automatic concept generation.
Coherent Concept-based Explanations in Medical Image and Its Application to Skin Lesion Diagnosis
Apr 17, 2023



Early detection of melanoma is crucial for preventing severe complications and increasing the chances of successful treatment. Existing deep learning approaches for melanoma skin lesion diagnosis are deemed black-box models, as they omit the rationale behind the model prediction, compromising the trustworthiness and acceptability of these diagnostic methods. Attempts to provide concept-based explanations are based on post-hoc approaches, which depend on an additional model to derive interpretations. In this paper, we propose an inherently interpretable framework to improve the interpretability of concept-based models by incorporating a hard attention mechanism and a coherence loss term to assure the visual coherence of concept activations by the concept encoder, without requiring the supervision of additional annotations. The proposed framework explains its decision in terms of human-interpretable concepts and their respective contribution to the final prediction, as well as a visual interpretation of the locations where the concept is present in the image. Experiments on skin image datasets demonstrate that our method outperforms existing black-box and concept-based models for skin lesion classification.
Explainable Deep Learning Methods in Medical Diagnosis: A Survey
May 10, 2022The remarkable success of deep learning has prompted interest in its application to medical diagnosis. Even tough state-of-the-art deep learning models have achieved human-level accuracy on the classification of different types of medical data, these models are hardly adopted in clinical workflows, mainly due to their lack of interpretability. The black-box-ness of deep learning models has raised the need for devising strategies to explain the decision process of these models, leading to the creation of the topic of eXplainable Artificial Intelligence (XAI). In this context, we provide a thorough survey of XAI applied to medical diagnosis, including visual, textual, and example-based explanation methods. Moreover, this work reviews the existing medical imaging datasets and the existing metrics for evaluating the quality of the explanations . Complementary to most existing surveys, we include a performance comparison among a set of report generation-based methods. Finally, the major challenges in applying XAI to medical imaging are also discussed.
Real or Fake? Spoofing State-Of-The-Art Face Synthesis Detection Systems
Nov 15, 2019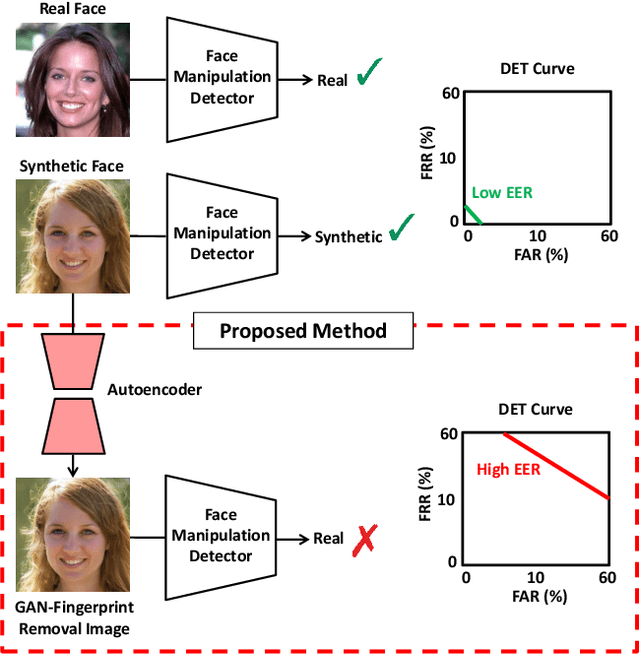
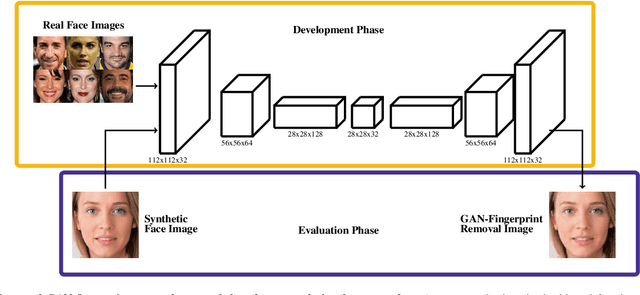


The availability of large-scale facial databases, together with the remarkable progresses of deep learning technologies, in particular Generative Adversarial Networks (GANs), have led to the generation of extremely realistic fake facial content, which raises obvious concerns about the potential for misuse. These concerns have fostered the research of manipulation detection methods that, contrary to humans, have already achieved astonishing results in some scenarios. In this study, we focus on the entire face synthesis, which is one specific type of facial manipulation. The main contributions of this study are: i) a novel strategy to remove GAN "fingerprints" from synthetic fake images in order to spoof facial manipulation detection systems, while keeping the visual quality of the resulting images, ii) an in-depth analysis of state-of-the-art detection approaches for the entire face synthesis manipulation, iii) a complete experimental assessment of this type of facial manipulation considering state-of-the-art detection systems, remarking how challenging is this task in unconstrained scenarios, and finally iv) a novel public database named FSRemovalDB produced after applying our proposed GAN-fingerprint removal approach to original synthetic fake images. The observed results led us to conclude that more efforts are required to develop robust facial manipulation detection systems against unseen conditions and spoof techniques such as the one proposed in this study.