 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeNLEX: Weakly Supervised Natural Language Explanations for Multilabel Chest X-ray Classification
Mar 19, 2026Natural language explanations provide an inherently human-understandable way to explain black-box models, closely reflecting how radiologists convey their diagnoses in textual reports. Most works explicitly supervise the explanation generation process using datasets annotated with explanations. Thus, though plausible, the generated explanations are not faithful to the model's reasoning. In this work, we propose WeNLEX, a weakly supervised model for the generation of natural language explanations for multilabel chest X-ray classification. Faithfulness is ensured by matching images generated from their corresponding natural language explanations with original images, in the black-box model's feature space. Plausibility is maintained via distribution alignment with a small database of clinician-annotated explanations. We empirically demonstrate, through extensive validation on multiple metrics to assess faithfulness, simulatability, diversity, and plausibility, that WeNLEX is able to produce faithful and plausible explanations, using as little as 5 ground-truth explanations per diagnosis. Furthermore, WeNLEX can operate in both post-hoc and in-model settings. In the latter, i.e., when the multilabel classifier is trained together with the rest of the network, WeNLEX improves the classification AUC of the standalone classifier by 2.21%, thus showing that adding interpretability to the training process can actually increase the downstream task performance. Additionally, simply by changing the database, WeNLEX explanations are adaptable to any target audience, and we showcase this flexibility by training a layman version of WeNLEX, where explanations are simplified for non-medical users.
Personalized Cell Segmentation: Benchmark and Framework for Reference-Guided Cell Type Segmentation
Mar 15, 2026Accurate cell segmentation is critical for biological and medical imaging studies. Although recent deep learning models have advanced this task, most methods are limited to generic cell segmentation, lacking the ability to differentiate specific cell types. In this work, we introduce the Personalized Cell Segmentation (PerCS) task, which aims to segment all cells of a specific type given a reference cell. To support this task, we establish a benchmark by reorganizing publicly available datasets, yielding 1,372 images and over 110,000 annotated cells. As a pioneering solution, we propose PerCS-DINO, a framework built on the DINOv2 backbone. By integrating image features and reference embeddings via a cross-attention transformer and contrastive learning, PerCS-DINO effectively segments cells matching the reference. Extensive experiments demonstrate the effectiveness of the proposed PerCS-DINO and highlight the challenges of this new task. We expect PerCS to serve as a useful testbed for advancing research in cell-based applications.
CountPath: Automating Fragment Counting in Digital Pathology
Mar 13, 2025



Quality control of medical images is a critical component of digital pathology, ensuring that diagnostic images meet required standards. A pre-analytical task within this process is the verification of the number of specimen fragments, a process that ensures that the number of fragments on a slide matches the number documented in the macroscopic report. This step is important to ensure that the slides contain the appropriate diagnostic material from the grossing process, thereby guaranteeing the accuracy of subsequent microscopic examination and diagnosis. Traditionally, this assessment is performed manually, requiring significant time and effort while being subject to significant variability due to its subjective nature. To address these challenges, this study explores an automated approach to fragment counting using the YOLOv9 and Vision Transformer models. Our results demonstrate that the automated system achieves a level of performance comparable to expert assessments, offering a reliable and efficient alternative to manual counting. Additionally, we present findings on interobserver variability, showing that the automated approach achieves an accuracy of 86%, which falls within the range of variation observed among experts (82-88%), further supporting its potential for integration into routine pathology workflows.
An inpainting approach to manipulate asymmetry in pre-operative breast images
Feb 08, 2025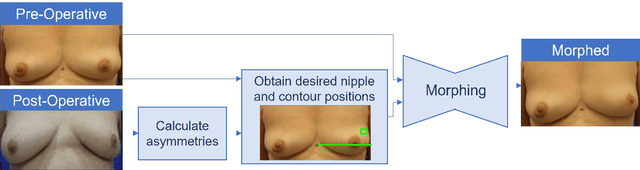
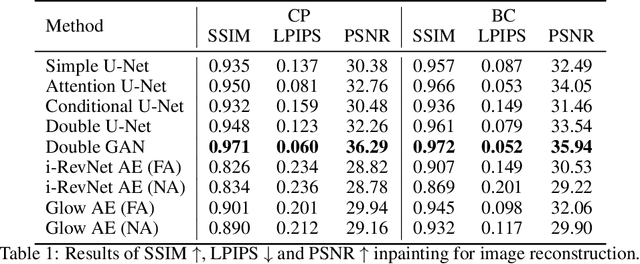
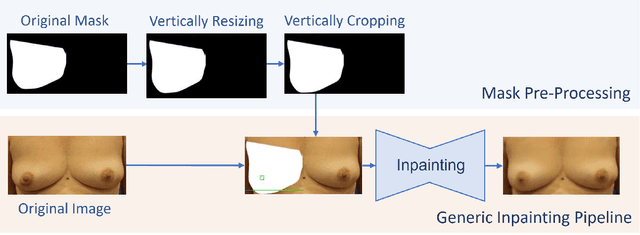

One of the most frequent modalities of breast cancer treatment is surgery. Breast surgery can cause visual alterations to the breasts, due to scars and asymmetries. To enable an informed choice of treatment, the patient must be adequately informed of the aesthetic outcomes of each treatment plan. In this work, we propose an inpainting approach to manipulate breast shape and nipple position in breast images, for the purpose of predicting the aesthetic outcomes of breast cancer treatment. We perform experiments with various model architectures for the inpainting task, including invertible networks capable of manipulating breasts in the absence of ground-truth breast contour and nipple annotations. Experiments on two breast datasets show the proposed models' ability to realistically alter a patient's breasts, enabling a faithful reproduction of breast asymmetries of post-operative patients in pre-operative images.
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Jan 21, 2025



The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Classification of Keratitis from Eye Corneal Photographs using Deep Learning
Nov 13, 2024



Keratitis is an inflammatory corneal condition responsible for 10% of visual impairment in low- and middle-income countries (LMICs), with bacteria, fungi, or amoeba as the most common infection etiologies. While an accurate and timely diagnosis is crucial for the selected treatment and the patients' sight outcomes, due to the high cost and limited availability of laboratory diagnostics in LMICs, diagnosis is often made by clinical observation alone, despite its lower accuracy. In this study, we investigate and compare different deep learning approaches to diagnose the source of infection: 1) three separate binary models for infection type predictions; 2) a multitask model with a shared backbone and three parallel classification layers (Multitask V1); and, 3) a multitask model with a shared backbone and a multi-head classification layer (Multitask V2). We used a private Brazilian cornea dataset to conduct the empirical evaluation. We achieved the best results with Multitask V2, with an area under the receiver operating characteristic curve (AUROC) confidence intervals of 0.7413-0.7740 (bacteria), 0.8395-0.8725 (fungi), and 0.9448-0.9616 (amoeba). A statistical analysis of the impact of patient features on models' performance revealed that sex significantly affects amoeba infection prediction, and age seems to affect fungi and bacteria predictions.
MST-KD: Multiple Specialized Teachers Knowledge Distillation for Fair Face Recognition
Aug 29, 2024



As in school, one teacher to cover all subjects is insufficient to distill equally robust information to a student. Hence, each subject is taught by a highly specialised teacher. Following a similar philosophy, we propose a multiple specialized teacher framework to distill knowledge to a student network. In our approach, directed at face recognition use cases, we train four teachers on one specific ethnicity, leading to four highly specialized and biased teachers. Our strategy learns a project of these four teachers into a common space and distill that information to a student network. Our results highlighted increased performance and reduced bias for all our experiments. In addition, we further show that having biased/specialized teachers is crucial by showing that our approach achieves better results than when knowledge is distilled from four teachers trained on balanced datasets. Our approach represents a step forward to the understanding of the importance of ethnicity-specific features.
Evaluating the Impact of Pulse Oximetry Bias in Machine Learning under Counterfactual Thinking
Aug 08, 2024
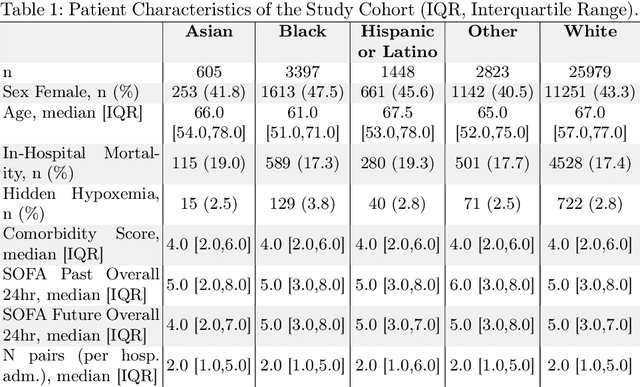
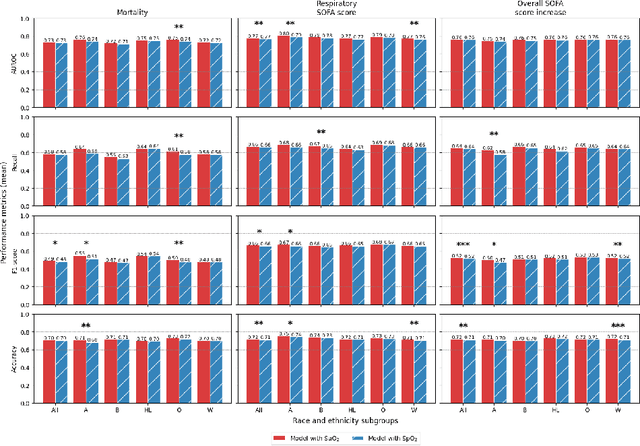

Algorithmic bias in healthcare mirrors existing data biases. However, the factors driving unfairness are not always known. Medical devices capture significant amounts of data but are prone to errors; for instance, pulse oximeters overestimate the arterial oxygen saturation of darker-skinned individuals, leading to worse outcomes. The impact of this bias in machine learning (ML) models remains unclear. This study addresses the technical challenges of quantifying the impact of medical device bias in downstream ML. Our experiments compare a "perfect world", without pulse oximetry bias, using SaO2 (blood-gas), to the "actual world", with biased measurements, using SpO2 (pulse oximetry). Under this counterfactual design, two models are trained with identical data, features, and settings, except for the method of measuring oxygen saturation: models using SaO2 are a "control" and models using SpO2 a "treatment". The blood-gas oximetry linked dataset was a suitable test-bed, containing 163,396 nearly-simultaneous SpO2 - SaO2 paired measurements, aligned with a wide array of clinical features and outcomes. We studied three classification tasks: in-hospital mortality, respiratory SOFA score in the next 24 hours, and SOFA score increase by two points. Models using SaO2 instead of SpO2 generally showed better performance. Patients with overestimation of O2 by pulse oximetry of > 3% had significant decreases in mortality prediction recall, from 0.63 to 0.59, P < 0.001. This mirrors clinical processes where biased pulse oximetry readings provide clinicians with false reassurance of patients' oxygen levels. A similar degradation happened in ML models, with pulse oximetry biases leading to more false negatives in predicting adverse outcomes.
Learning Ordinality in Semantic Segmentation
Jul 30, 2024



Semantic segmentation consists of predicting a semantic label for each image pixel. Conventional deep learning models do not take advantage of ordinal relations that might exist in the domain at hand. For example, it is known that the pupil is inside the iris, and the lane markings are inside the road. Such domain knowledge can be employed as constraints to make the model more robust. The current literature on this topic has explored pixel-wise ordinal segmentation methods, which treat each pixel as an independent observation and promote ordinality in its representation. This paper proposes novel spatial ordinal segmentation methods, which take advantage of the structured image space by considering each pixel as an observation dependent on its neighborhood context to also promote ordinal spatial consistency. When evaluated with five biomedical datasets and multiple configurations of autonomous driving datasets, ordinal methods resulted in more ordinally-consistent models, with substantial improvements in ordinal metrics and some increase in the Dice coefficient. It was also shown that the incorporation of ordinal consistency results in models with better generalization abilities.