 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Impact of Pulse Oximetry Bias in Machine Learning under Counterfactual Thinking
Aug 08, 2024
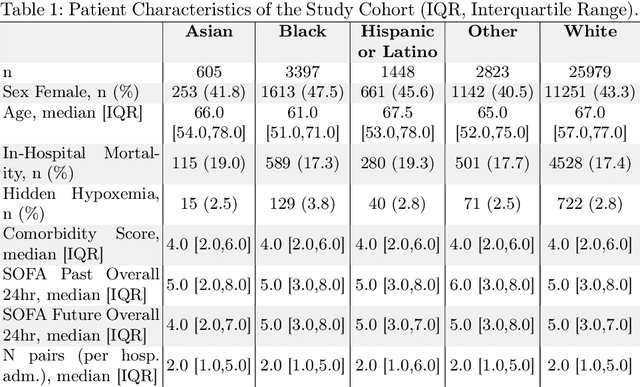
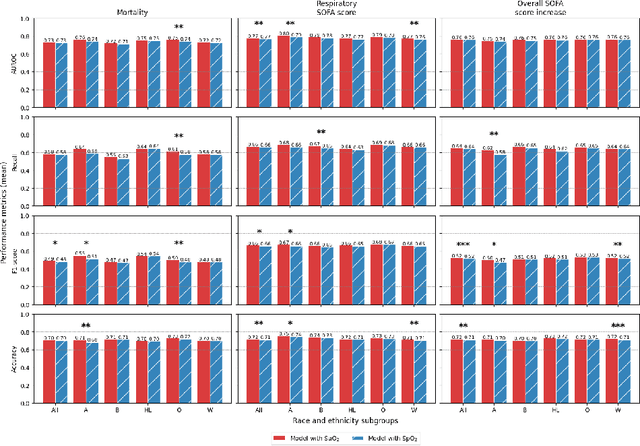

Algorithmic bias in healthcare mirrors existing data biases. However, the factors driving unfairness are not always known. Medical devices capture significant amounts of data but are prone to errors; for instance, pulse oximeters overestimate the arterial oxygen saturation of darker-skinned individuals, leading to worse outcomes. The impact of this bias in machine learning (ML) models remains unclear. This study addresses the technical challenges of quantifying the impact of medical device bias in downstream ML. Our experiments compare a "perfect world", without pulse oximetry bias, using SaO2 (blood-gas), to the "actual world", with biased measurements, using SpO2 (pulse oximetry). Under this counterfactual design, two models are trained with identical data, features, and settings, except for the method of measuring oxygen saturation: models using SaO2 are a "control" and models using SpO2 a "treatment". The blood-gas oximetry linked dataset was a suitable test-bed, containing 163,396 nearly-simultaneous SpO2 - SaO2 paired measurements, aligned with a wide array of clinical features and outcomes. We studied three classification tasks: in-hospital mortality, respiratory SOFA score in the next 24 hours, and SOFA score increase by two points. Models using SaO2 instead of SpO2 generally showed better performance. Patients with overestimation of O2 by pulse oximetry of > 3% had significant decreases in mortality prediction recall, from 0.63 to 0.59, P < 0.001. This mirrors clinical processes where biased pulse oximetry readings provide clinicians with false reassurance of patients' oxygen levels. A similar degradation happened in ML models, with pulse oximetry biases leading to more false negatives in predicting adverse outcomes.