 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning of Lab Values via Masked AutoEncoder
Jan 05, 2025



Accurate imputation of missing laboratory values in electronic health records (EHRs) is critical to enable robust clinical predictions and reduce biases in AI systems in healthcare. Existing methods, such as variational autoencoders (VAEs) and decision tree-based approaches such as XGBoost, struggle to model the complex temporal and contextual dependencies in EHR data, mainly in underrepresented groups. In this work, we propose Lab-MAE, a novel transformer-based masked autoencoder framework that leverages self-supervised learning for the imputation of continuous sequential lab values. Lab-MAE introduces a structured encoding scheme that jointly models laboratory test values and their corresponding timestamps, enabling explicit capturing temporal dependencies. Empirical evaluation on the MIMIC-IV dataset demonstrates that Lab-MAE significantly outperforms the state-of-the-art baselines such as XGBoost across multiple metrics, including root mean square error (RMSE), R-squared (R2), and Wasserstein distance (WD). Notably, Lab-MAE achieves equitable performance across demographic groups of patients, advancing fairness in clinical predictions. We further investigate the role of follow-up laboratory values as potential shortcut features, revealing Lab-MAE's robustness in scenarios where such data is unavailable. The findings suggest that our transformer-based architecture, adapted to the characteristics of the EHR data, offers a foundation model for more accurate and fair clinical imputation models. In addition, we measure and compare the carbon footprint of Lab-MAE with the baseline XGBoost model, highlighting its environmental requirements.
WorldMedQA-V: a multilingual, multimodal medical examination dataset for multimodal language models evaluation
Oct 16, 2024Multimodal/vision language models (VLMs) are increasingly being deployed in healthcare settings worldwide, necessitating robust benchmarks to ensure their safety, efficacy, and fairness. Multiple-choice question and answer (QA) datasets derived from national medical examinations have long served as valuable evaluation tools, but existing datasets are largely text-only and available in a limited subset of languages and countries. To address these challenges, we present WorldMedQA-V, an updated multilingual, multimodal benchmarking dataset designed to evaluate VLMs in healthcare. WorldMedQA-V includes 568 labeled multiple-choice QAs paired with 568 medical images from four countries (Brazil, Israel, Japan, and Spain), covering original languages and validated English translations by native clinicians, respectively. Baseline performance for common open- and closed-source models are provided in the local language and English translations, and with and without images provided to the model. The WorldMedQA-V benchmark aims to better match AI systems to the diverse healthcare environments in which they are deployed, fostering more equitable, effective, and representative applications.
Evaluating the Impact of Pulse Oximetry Bias in Machine Learning under Counterfactual Thinking
Aug 08, 2024
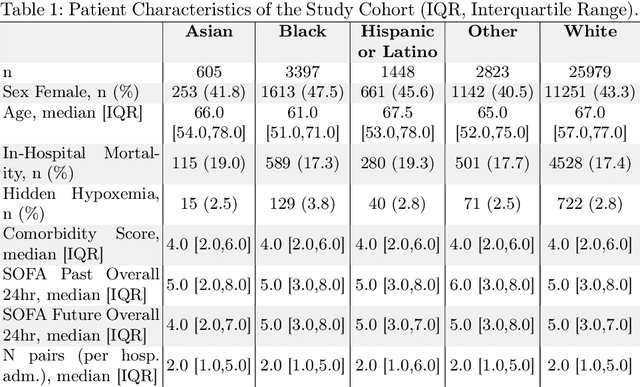
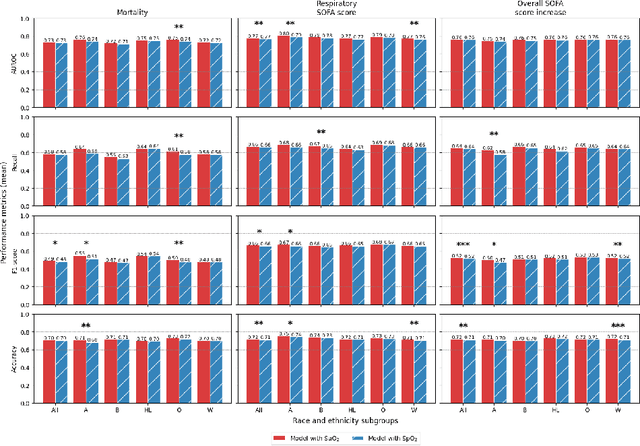

Algorithmic bias in healthcare mirrors existing data biases. However, the factors driving unfairness are not always known. Medical devices capture significant amounts of data but are prone to errors; for instance, pulse oximeters overestimate the arterial oxygen saturation of darker-skinned individuals, leading to worse outcomes. The impact of this bias in machine learning (ML) models remains unclear. This study addresses the technical challenges of quantifying the impact of medical device bias in downstream ML. Our experiments compare a "perfect world", without pulse oximetry bias, using SaO2 (blood-gas), to the "actual world", with biased measurements, using SpO2 (pulse oximetry). Under this counterfactual design, two models are trained with identical data, features, and settings, except for the method of measuring oxygen saturation: models using SaO2 are a "control" and models using SpO2 a "treatment". The blood-gas oximetry linked dataset was a suitable test-bed, containing 163,396 nearly-simultaneous SpO2 - SaO2 paired measurements, aligned with a wide array of clinical features and outcomes. We studied three classification tasks: in-hospital mortality, respiratory SOFA score in the next 24 hours, and SOFA score increase by two points. Models using SaO2 instead of SpO2 generally showed better performance. Patients with overestimation of O2 by pulse oximetry of > 3% had significant decreases in mortality prediction recall, from 0.63 to 0.59, P < 0.001. This mirrors clinical processes where biased pulse oximetry readings provide clinicians with false reassurance of patients' oxygen levels. A similar degradation happened in ML models, with pulse oximetry biases leading to more false negatives in predicting adverse outcomes.
CheXRelNet: An Anatomy-Aware Model for Tracking Longitudinal Relationships between Chest X-Rays
Aug 08, 2022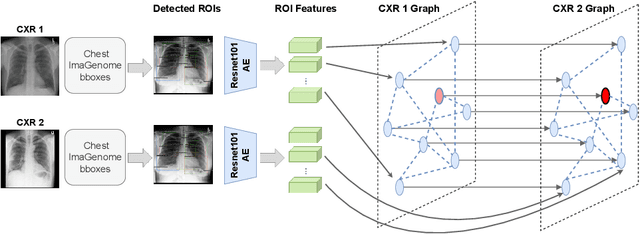
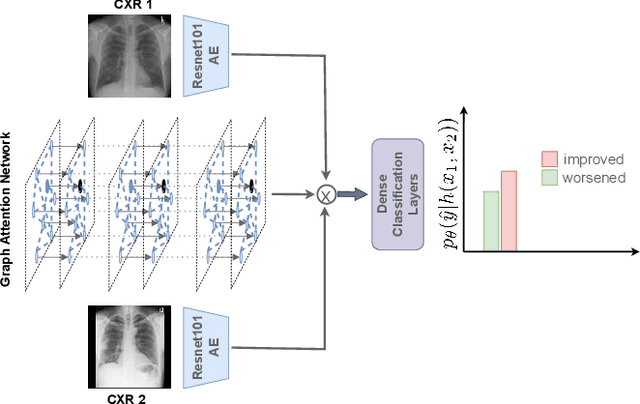
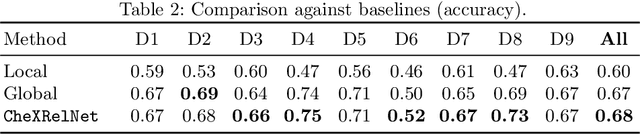
Despite the progress in utilizing deep learning to automate chest radiograph interpretation and disease diagnosis tasks, change between sequential Chest X-rays (CXRs) has received limited attention. Monitoring the progression of pathologies that are visualized through chest imaging poses several challenges in anatomical motion estimation and image registration, i.e., spatially aligning the two images and modeling temporal dynamics in change detection. In this work, we propose CheXRelNet, a neural model that can track longitudinal pathology change relations between two CXRs. CheXRelNet incorporates local and global visual features, utilizes inter-image and intra-image anatomical information, and learns dependencies between anatomical region attributes, to accurately predict disease change for a pair of CXRs. Experimental results on the Chest ImaGenome dataset show increased downstream performance compared to baselines. Code is available at https://github.com/PLAN-Lab/ChexRelNet
Chest ImaGenome Dataset for Clinical Reasoning
Jul 31, 2021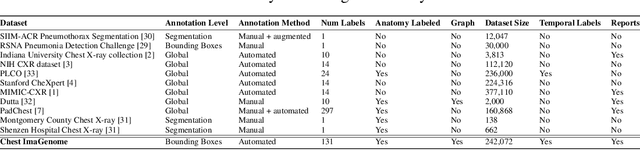
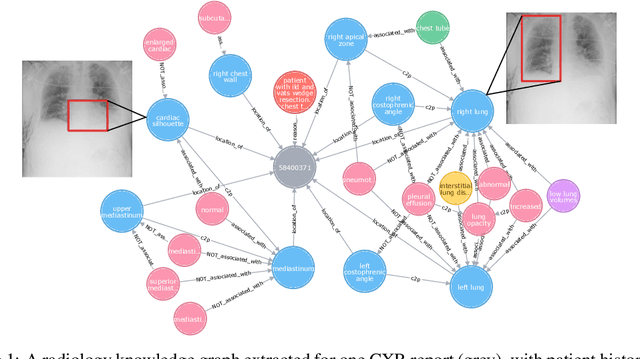
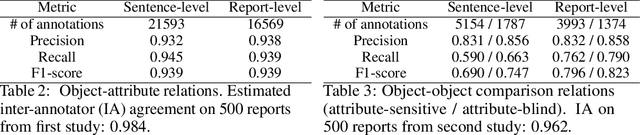

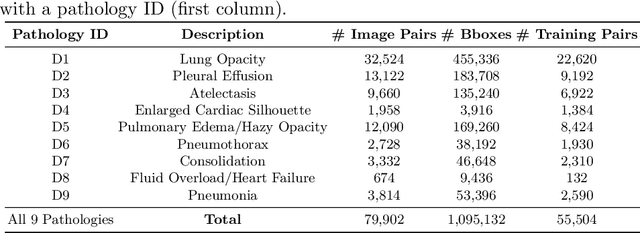
Despite the progress in automatic detection of radiologic findings from chest X-ray (CXR) images in recent years, a quantitative evaluation of the explainability of these models is hampered by the lack of locally labeled datasets for different findings. With the exception of a few expert-labeled small-scale datasets for specific findings, such as pneumonia and pneumothorax, most of the CXR deep learning models to date are trained on global "weak" labels extracted from text reports, or trained via a joint image and unstructured text learning strategy. Inspired by the Visual Genome effort in the computer vision community, we constructed the first Chest ImaGenome dataset with a scene graph data structure to describe $242,072$ images. Local annotations are automatically produced using a joint rule-based natural language processing (NLP) and atlas-based bounding box detection pipeline. Through a radiologist constructed CXR ontology, the annotations for each CXR are connected as an anatomy-centered scene graph, useful for image-level reasoning and multimodal fusion applications. Overall, we provide: i) $1,256$ combinations of relation annotations between $29$ CXR anatomical locations (objects with bounding box coordinates) and their attributes, structured as a scene graph per image, ii) over $670,000$ localized comparison relations (for improved, worsened, or no change) between the anatomical locations across sequential exams, as well as ii) a manually annotated gold standard scene graph dataset from $500$ unique patients.
Expert-Supervised Reinforcement Learning for Offline Policy Learning and Evaluation
Jun 23, 2020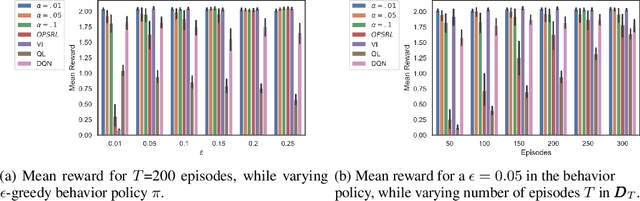
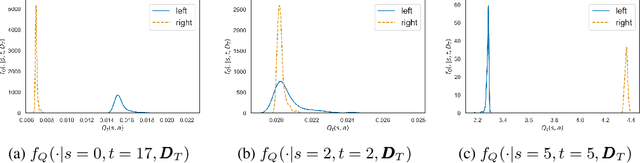
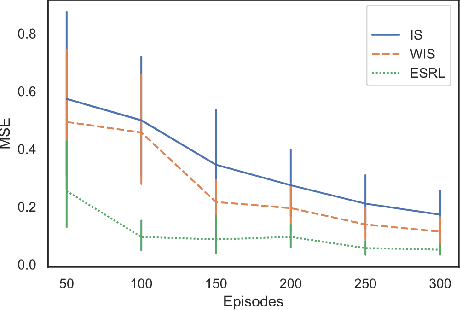
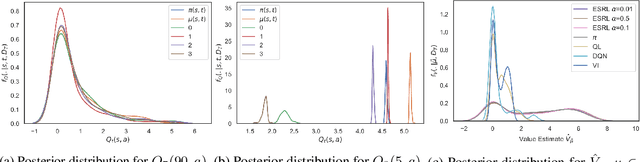
Offline Reinforcement Learning (RL) is a promising approach for learning optimal policies in environments where direct exploration is expensive or unfeasible. However, the adoption of such policies in practice is often challenging, as they are hard to interpret within the application context, and lack measures of uncertainty for the learned policy value and its decisions. To overcome these issues, we propose an Expert-Supervised RL (ESRL) framework which uses uncertainty quantification for offline policy learning. In particular, we have three contributions: 1) the method can learn safe and optimal policies through hypothesis testing, 2) ESRL allows for different levels of risk aversion within the application context, and finally, 3) we propose a way to interpret ESRL's policy at every state through posterior distributions, and use this framework to compute off-policy value function posteriors. We provide theoretical guarantees for our estimators and regret bounds consistent with Posterior Sampling for RL (PSRL) that account for any risk aversion threshold. We further propose an offline version of PSRL as a special case of ESRL.
Migration through Machine Learning Lens -- Predicting Sexual and Reproductive Health Vulnerability of Young Migrants
Nov 15, 2019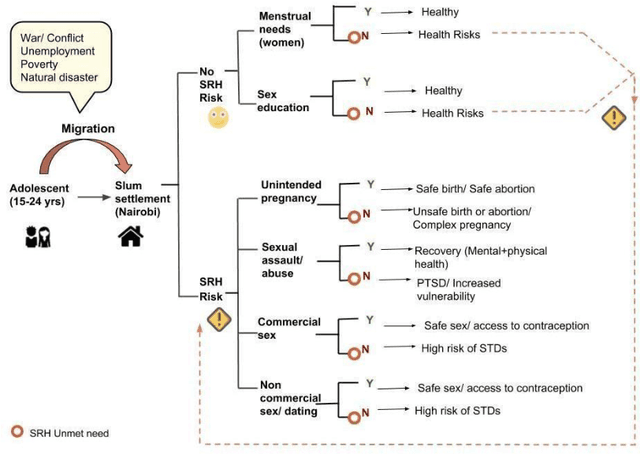

In this paper, we have discussed initial findings and results of our experiment to predict sexual and reproductive health vulnerabilities of migrants in a data-constrained environment. Notwithstanding the limited research and data about migrants and migration cities, we propose a solution that simultaneously focuses on data gathering from migrants, augmenting awareness of the migrants to reduce mishaps, and setting up a mechanism to present insights to the key stakeholders in migration to act upon. We have designed a webapp for the stakeholders involved in migration: migrants, who would participate in data gathering process and can also use the app for getting to know safety and awareness tips based on analysis of the data received; public health workers, who would have an access to the database of migrants on the app; policy makers, who would have a greater understanding of the ground reality, and of the patterns of migration through machine-learned analysis. Finally, we have experimented with different machine learning models on an artificially curated dataset. We have shown, through experiments, how machine learning can assist in predicting the migrants at risk and can also help in identifying the critical factors that make migration dangerous for migrants. The results for identifying vulnerable migrants through machine learning algorithms are statistically significant at an alpha of 0.05.
Understanding the Artificial Intelligence Clinician and optimal treatment strategies for sepsis in intensive care
Mar 06, 2019In this document, we explore in more detail our published work (Komorowski, Celi, Badawi, Gordon, & Faisal, 2018) for the benefit of the AI in Healthcare research community. In the above paper, we developed the AI Clinician system, which demonstrated how reinforcement learning could be used to make useful recommendations towards optimal treatment decisions from intensive care data. Since publication a number of authors have reviewed our work (e.g. Abbasi, 2018; Bos, Azoulay, & Martin-Loeches, 2019; Saria, 2018). Given the difference of our framework to previous work, the fact that we are bridging two very different academic communities (intensive care and machine learning) and that our work has impact on a number of other areas with more traditional computer-based approaches (biosignal processing and control, biomedical engineering), we are providing here additional details on our recent publication.