 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMigration through Machine Learning Lens -- Predicting Sexual and Reproductive Health Vulnerability of Young Migrants
Nov 15, 2019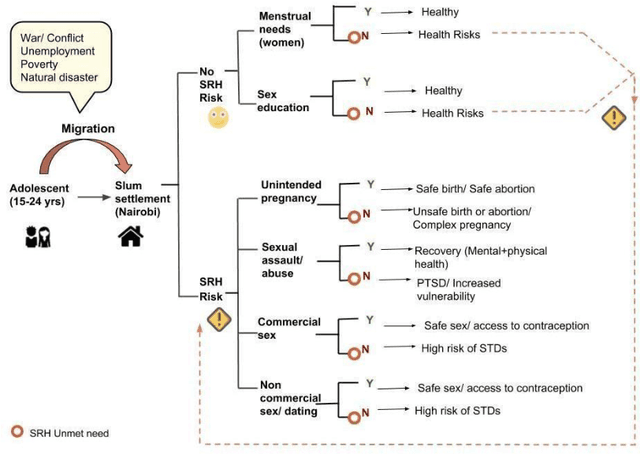

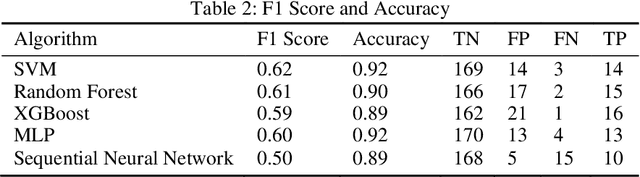
In this paper, we have discussed initial findings and results of our experiment to predict sexual and reproductive health vulnerabilities of migrants in a data-constrained environment. Notwithstanding the limited research and data about migrants and migration cities, we propose a solution that simultaneously focuses on data gathering from migrants, augmenting awareness of the migrants to reduce mishaps, and setting up a mechanism to present insights to the key stakeholders in migration to act upon. We have designed a webapp for the stakeholders involved in migration: migrants, who would participate in data gathering process and can also use the app for getting to know safety and awareness tips based on analysis of the data received; public health workers, who would have an access to the database of migrants on the app; policy makers, who would have a greater understanding of the ground reality, and of the patterns of migration through machine-learned analysis. Finally, we have experimented with different machine learning models on an artificially curated dataset. We have shown, through experiments, how machine learning can assist in predicting the migrants at risk and can also help in identifying the critical factors that make migration dangerous for migrants. The results for identifying vulnerable migrants through machine learning algorithms are statistically significant at an alpha of 0.05.
Job Recommendation through Progression of Job Selection
May 28, 2019



Job recommendation has traditionally been treated as a filter-based match or as a recommendation based on the features of jobs and candidates as discrete entities. In this paper, we introduce a methodology where we leverage the progression of job selection by candidates using machine learning. Additionally, our recommendation is composed of several other sub-recommendations that contribute to at least one of a) making recommendations serendipitous for the end user b) overcoming cold-start for both candidates and jobs. One of the unique selling propositions of our methodology is the way we have used skills as embedded features and derived latent competencies from them, thereby attempting to expand the skills of candidates and jobs to achieve more coverage in the skill domain. We have deployed our model in a real-world job recommender system and have achieved the best click-through rate through a blended approach of machine-learned recommendations and other sub-recommendations. For recommending jobs through machine learning that forms a significant part of our recommendation, we achieve the best results through Bi-LSTM with attention.
Intent Detection and Slots Prompt in a Closed-Domain Chatbot
Jan 10, 2019

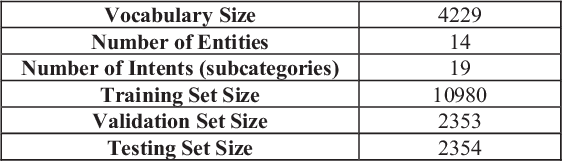
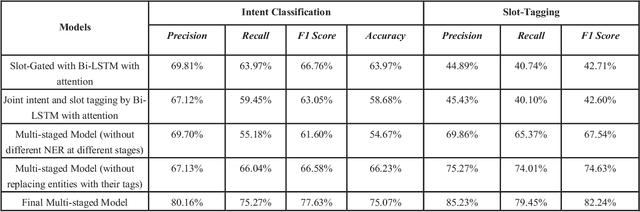
In this paper, we introduce a methodology for predicting intent and slots of a query for a chatbot that answers career-related queries. We take a multi-staged approach where both the processes (intent-classification and slot-tagging) inform each other's decision-making in different stages. The model breaks down the problem into stages, solving one problem at a time and passing on relevant results of the current stage to the next, thereby reducing search space for subsequent stages, and eventually making classification and tagging more viable after each stage. We also observe that relaxing rules for a fuzzy entity-matching in slot-tagging after each stage (by maintaining a separate Named Entity Tagger per stage) helps us improve performance, although at a slight cost of false-positives. Our model has achieved state-of-the-art performance with F1-score of 77.63% for intent-classification and 82.24% for slot-tagging on our dataset that we would publicly release along with the paper.
Role of Intonation in Scoring Spoken English
Aug 23, 2018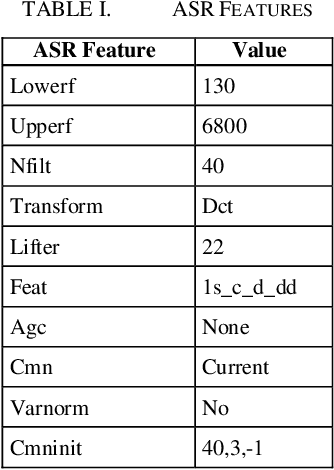
In this paper, we have introduced and evaluated intonation based feature for scoring the English speech of nonnative English speakers in Indian context. For this, we created an automated spoken English scoring engine to learn from the manual evaluation of spoken English. This involved using an existing Automatic Speech Recognition (ASR) engine to convert the speech to text. Thereafter, macro features like accuracy, fluency and prosodic features were used to build a scoring model. In the process, we introduced SimIntonation, short for similarity between spoken intonation pattern and "ideal" i.e. training intonation pattern. Our results show that it is a highly predictive feature under controlled environment. We also categorized interword pauses into 4 distinct types for a granular evaluation of pauses and their impact on speech evaluation. Moreover, we took steps to moderate test difficulty through its evaluation across parameters like difficult word count, average sentence readability and lexical density. Our results show that macro features like accuracy and intonation, and micro features like pause-topography are strongly predictive. The scoring of spoken English is not within the purview of this paper.
Exploring Automated Essay Scoring for Nonnative English Speakers
Sep 29, 2017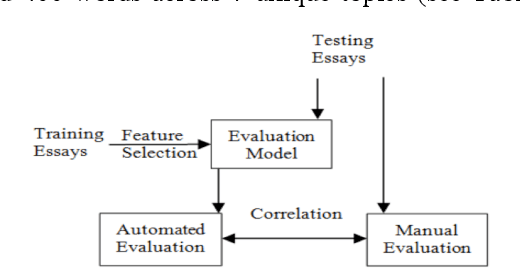


Automated Essay Scoring (AES) has been quite popular and is being widely used. However, lack of appropriate methodology for rating nonnative English speakers' essays has meant a lopsided advancement in this field. In this paper, we report initial results of our experiments with nonnative AES that learns from manual evaluation of nonnative essays. For this purpose, we conducted an exercise in which essays written by nonnative English speakers in test environment were rated both manually and by the automated system designed for the experiment. In the process, we experimented with a few features to learn about nuances linked to nonnative evaluation. The proposed methodology of automated essay evaluation has yielded a correlation coefficient of 0.750 with the manual evaluation.