 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spectral Embedding through Robust and Flexible Knowledge Transfer in Electronic Health Records
Jun 10, 2026We propose a spectral-based, unsupervised representation learning framework to derive low-dimensional embeddings for clinical concepts and patients in rare disease cohorts from electronic health records, where data are high-dimensional but sample sizes are limited. To overcome this challenge, we incorporate a knowledge matrix extracted from a broader population that shares a partially overlapping subspace with the rare-disease cohort. Our method departs from existing approaches by relaxing restrictive one-to-one signal-alignment assumptions between the latent data matrix and knowledge matrix, allowing more flexible and realistic forms of structured sharing. We introduce a novel two-step spectral embedding procedure: first, we identify and remove irrelevant components from the knowledge matrix; then, we apply a projection-based method to separately recover shared and heterogeneous components. Simulations and an analysis of a real-world multiple sclerosis cohort show that the proposed method outperforms competing approaches, particularly in challenging scenarios where shared signals are weak and only partially aligned, as is common in rare-disease data.
Optimally taming biases in black-box models for efficient semiparametric estimation
Jun 04, 2026Modern semiparametric estimation often relies on flexible black-box machine learning methods to estimate nuisance functions, raising a fundamental question: how do nuisance estimation errors propagate into inference for low-dimensional target parameters? The dominant paradigm, exemplified by double machine learning (DML), yields error bounds in which nuisance estimation errors enter multiplicatively. While widely adopted, it remains unclear whether this multiplicative-rate dependence is optimal for black-box models. In this paper, we start by revisiting the partial linear model $Y = μ_0(X)+T\cdotβ_0+\varepsilon$ under a structure-agnostic setting, where the nuisance function $μ_0$ is estimated using a generic machine learning model, with approximation error $δ^a_μ$ and stochastic error $δ_μ^s$. We show that the standard DML rate is not optimal in the regime where the auxiliary function $\mathbb{E}[T|X=x]$ cannot be consistently estimated. We propose a new estimator for $β_0$ that achieves a sharper rate of $n^{-1/2}+δ^a_μ+(δ_μ^s)^2$ and establish a matching lower bound demonstrating its optimality. Our results reveal a new principle: the first-order stochastic error of nuisance estimation can be eliminated without imposing any additional assumptions. This also leads to a revised tuning strategy favoring under-smoothing, where $δ^a_μ\asymp(δ_μ^s)^2$, rather than the classical bias-variance trade-off $δ^a_μ\asymp δ_μ^s$. Under mild additional conditions, the estimator is asymptotically normal with minimal asymptotic variance. The proposed method extends to a broad class of semi-parametric linear functional estimation problems, including average treatment effect estimation. Our results imply that popular orthogonal score methods in semiparametric estimation with black-box nuisance learners can be substantially improved.
Cost-optimal Sequential Testing via Doubly Robust Q-learning
Apr 13, 2026Clinical decision-making often involves selecting tests that are costly, invasive, or time-consuming, motivating individualized, sequential strategies for what to measure and when to stop ascertaining. We study the problem of learning cost-optimal sequential decision policies from retrospective data, where test availability depends on prior results, inducing informative missingness. Under a sequential missing-at-random mechanism, we develop a doubly robust Q-learning framework for estimating optimal policies. The method introduces path-specific inverse probability weights that account for heterogeneous test trajectories and satisfy a normalization property conditional on the observed history. By combining these weights with auxiliary contrast models, we construct orthogonal pseudo-outcomes that enable unbiased policy learning when either the acquisition model or the contrast model is correctly specified. We establish oracle inequalities for the stage-wise contrast estimators, along with convergence rates, regret bounds, and misclassification rates for the learned policy. Simulations demonstrate improved cost-adjusted performance over weighted and complete-case baselines, and an application to a prostate cancer cohort study illustrates how the method reduces testing cost without compromising predictive accuracy.
Knowledge-Embedded Latent Projection for Robust Representation Learning
Feb 18, 2026Latent space models are widely used for analyzing high-dimensional discrete data matrices, such as patient-feature matrices in electronic health records (EHRs), by capturing complex dependence structures through low-dimensional embeddings. However, estimation becomes challenging in the imbalanced regime, where one matrix dimension is much larger than the other. In EHR applications, cohort sizes are often limited by disease prevalence or data availability, whereas the feature space remains extremely large due to the breadth of medical coding system. Motivated by the increasing availability of external semantic embeddings, such as pre-trained embeddings of clinical concepts in EHRs, we propose a knowledge-embedded latent projection model that leverages semantic side information to regularize representation learning. Specifically, we model column embeddings as smooth functions of semantic embeddings via a mapping in a reproducing kernel Hilbert space. We develop a computationally efficient two-step estimation procedure that combines semantically guided subspace construction via kernel principal component analysis with scalable projected gradient descent. We establish estimation error bounds that characterize the trade-off between statistical error and approximation error induced by the kernel projection. Furthermore, we provide local convergence guarantees for our non-convex optimization procedure. Extensive simulation studies and a real-world EHR application demonstrate the effectiveness of the proposed method.
Learning Sequential Decisions from Multiple Sources via Group-Robust Markov Decision Processes
Feb 02, 2026We often collect data from multiple sites (e.g., hospitals) that share common structure but also exhibit heterogeneity. This paper aims to learn robust sequential decision-making policies from such offline, multi-site datasets. To model cross-site uncertainty, we study distributionally robust MDPs with a group-linear structure: all sites share a common feature map, and both the transition kernels and expected reward functions are linear in these shared features. We introduce feature-wise (d-rectangular) uncertainty sets, which preserve tractable robust Bellman recursions while maintaining key cross-site structure. Building on this, we then develop an offline algorithm based on pessimistic value iteration that includes: (i) per-site ridge regression for Bellman targets, (ii) feature-wise worst-case (row-wise minimization) aggregation, and (iii) a data-dependent pessimism penalty computed from the diagonals of the inverse design matrices. We further propose a cluster-level extension that pools similar sites to improve sample efficiency, guided by prior knowledge of site similarity. Under a robust partial coverage assumption, we prove a suboptimality bound for the resulting policy. Overall, our framework addresses multi-site learning with heterogeneous data sources and provides a principled approach to robust planning without relying on strong state-action rectangularity assumptions.
Adversarial Drift-Aware Predictive Transfer: Toward Durable Clinical AI
Jan 21, 2026Clinical AI systems frequently suffer performance decay post-deployment due to temporal data shifts, such as evolving populations, diagnostic coding updates (e.g., ICD-9 to ICD-10), and systemic shocks like the COVID-19 pandemic. Addressing this ``aging'' effect via frequent retraining is often impractical due to computational costs and privacy constraints. To overcome these hurdles, we introduce Adversarial Drift-Aware Predictive Transfer (ADAPT), a novel framework designed to confer durability against temporal drift with minimal retraining. ADAPT innovatively constructs an uncertainty set of plausible future models by combining historical source models and limited current data. By optimizing worst-case performance over this set, it balances current accuracy with robustness against degradation due to future drifts. Crucially, ADAPT requires only summary-level model estimators from historical periods, preserving data privacy and ensuring operational simplicity. Validated on longitudinal suicide risk prediction using electronic health records from Mass General Brigham (2005--2021) and Duke University Health Systems, ADAPT demonstrated superior stability across coding transitions and pandemic-induced shifts. By minimizing annual performance decay without labeling or retraining future data, ADAPT offers a scalable pathway for sustaining reliable AI in high-stakes healthcare environments.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
PEHRT: A Common Pipeline for Harmonizing Electronic Health Record data for Translational Research
Sep 10, 2025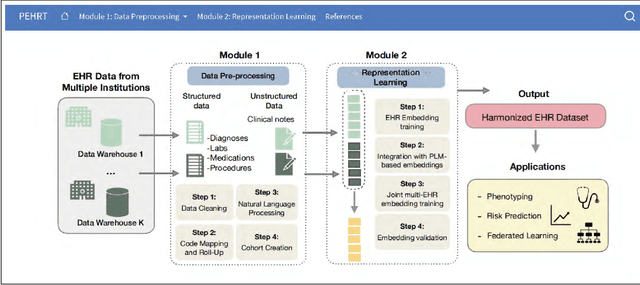
Integrative analysis of multi-institutional Electronic Health Record (EHR) data enhances the reliability and generalizability of translational research by leveraging larger, more diverse patient cohorts and incorporating multiple data modalities. However, harmonizing EHR data across institutions poses major challenges due to data heterogeneity, semantic differences, and privacy concerns. To address these challenges, we introduce $\textit{PEHRT}$, a standardized pipeline for efficient EHR data harmonization consisting of two core modules: (1) data pre-processing and (2) representation learning. PEHRT maps EHR data to standard coding systems and uses advanced machine learning to generate research-ready datasets without requiring individual-level data sharing. Our pipeline is also data model agnostic and designed for streamlined execution across institutions based on our extensive real-world experience. We provide a complete suite of open source software, accompanied by a user-friendly tutorial, and demonstrate the utility of PEHRT in a variety of tasks using data from diverse healthcare systems.
One Patient, Many Contexts: Scaling Medical AI Through Contextual Intelligence
Jun 11, 2025

Medical foundation models, including language models trained on clinical notes, vision-language models on medical images, and multimodal models on electronic health records, can summarize clinical notes, answer medical questions, and assist in decision-making. Adapting these models to new populations, specialties, or settings typically requires fine-tuning, careful prompting, or retrieval from knowledge bases. This can be impractical, and limits their ability to interpret unfamiliar inputs and adjust to clinical situations not represented during training. As a result, models are prone to contextual errors, where predictions appear reasonable but fail to account for critical patient-specific or contextual information. These errors stem from a fundamental limitation that current models struggle with: dynamically adjusting their behavior across evolving contexts of medical care. In this Perspective, we outline a vision for context-switching in medical AI: models that dynamically adapt their reasoning without retraining to new specialties, populations, workflows, and clinical roles. We envision context-switching AI to diagnose, manage, and treat a wide range of diseases across specialties and regions, and expand access to medical care.
Integrated Analysis for Electronic Health Records with Structured and Sporadic Missingness
Jun 10, 2025Objectives: We propose a novel imputation method tailored for Electronic Health Records (EHRs) with structured and sporadic missingness. Such missingness frequently arises in the integration of heterogeneous EHR datasets for downstream clinical applications. By addressing these gaps, our method provides a practical solution for integrated analysis, enhancing data utility and advancing the understanding of population health. Materials and Methods: We begin by demonstrating structured and sporadic missing mechanisms in the integrated analysis of EHR data. Following this, we introduce a novel imputation framework, Macomss, specifically designed to handle structurally and heterogeneously occurring missing data. We establish theoretical guarantees for Macomss, ensuring its robustness in preserving the integrity and reliability of integrated analyses. To assess its empirical performance, we conduct extensive simulation studies that replicate the complex missingness patterns observed in real-world EHR systems, complemented by validation using EHR datasets from the Duke University Health System (DUHS). Results: Simulation studies show that our approach consistently outperforms existing imputation methods. Using datasets from three hospitals within DUHS, Macomss achieves the lowest imputation errors for missing data in most cases and provides superior or comparable downstream prediction performance compared to benchmark methods. Conclusions: We provide a theoretically guaranteed and practically meaningful method for imputing structured and sporadic missing data, enabling accurate and reliable integrated analysis across multiple EHR datasets. The proposed approach holds significant potential for advancing research in population health.