 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIE: Generative Note Information Extraction model for structuring EHR data
Jan 30, 2025
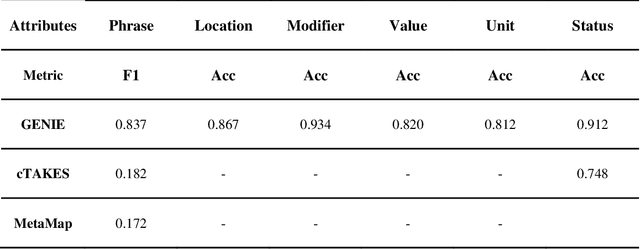
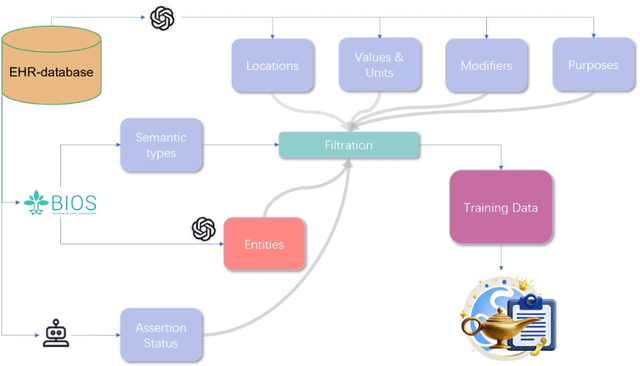
Electronic Health Records (EHRs) hold immense potential for advancing healthcare, offering rich, longitudinal data that combines structured information with valuable insights from unstructured clinical notes. However, the unstructured nature of clinical text poses significant challenges for secondary applications. Traditional methods for structuring EHR free-text data, such as rule-based systems and multi-stage pipelines, are often limited by their time-consuming configurations and inability to adapt across clinical notes from diverse healthcare settings. Few systems provide a comprehensive attribute extraction for terminologies. While giant large language models (LLMs) like GPT-4 and LLaMA 405B excel at structuring tasks, they are slow, costly, and impractical for large-scale use. To overcome these limitations, we introduce GENIE, a Generative Note Information Extraction system that leverages LLMs to streamline the structuring of unstructured clinical text into usable data with standardized format. GENIE processes entire paragraphs in a single pass, extracting entities, assertion statuses, locations, modifiers, values, and purposes with high accuracy. Its unified, end-to-end approach simplifies workflows, reduces errors, and eliminates the need for extensive manual intervention. Using a robust data preparation pipeline and fine-tuned small scale LLMs, GENIE achieves competitive performance across multiple information extraction tasks, outperforming traditional tools like cTAKES and MetaMap and can handle extra attributes to be extracted. GENIE strongly enhances real-world applicability and scalability in healthcare systems. By open-sourcing the model and test data, we aim to encourage collaboration and drive further advancements in EHR structurization.
Event Stream GPT: A Data Pre-processing and Modeling Library for Generative, Pre-trained Transformers over Continuous-time Sequences of Complex Events
Jun 21, 2023Generative, pre-trained transformers (GPTs, a.k.a. "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
Construction of extra-large scale screening tools for risks of severe mental illnesses using real world healthcare data
Dec 20, 2022Importance: The prevalence of severe mental illnesses (SMIs) in the United States is approximately 3% of the whole population. The ability to conduct risk screening of SMIs at large scale could inform early prevention and treatment. Objective: A scalable machine learning based tool was developed to conduct population-level risk screening for SMIs, including schizophrenia, schizoaffective disorders, psychosis, and bipolar disorders,using 1) healthcare insurance claims and 2) electronic health records (EHRs). Design, setting and participants: Data from beneficiaries from a nationwide commercial healthcare insurer with 77.4 million members and data from patients from EHRs from eight academic hospitals based in the U.S. were used. First, the predictive models were constructed and tested using data in case-control cohorts from insurance claims or EHR data. Second, performance of the predictive models across data sources were analyzed. Third, as an illustrative application, the models were further trained to predict risks of SMIs among 18-year old young adults and individuals with substance associated conditions. Main outcomes and measures: Machine learning-based predictive models for SMIs in the general population were built based on insurance claims and EHR.