 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-generated data contamination erodes pathological variability and diagnostic reliability
Jan 21, 2026Generative artificial intelligence (AI) is rapidly populating medical records with synthetic content, creating a feedback loop where future models are increasingly at risk of training on uncurated AI-generated data. However, the clinical consequences of this AI-generated data contamination remain unexplored. Here, we show that in the absence of mandatory human verification, this self-referential cycle drives a rapid erosion of pathological variability and diagnostic reliability. By analysing more than 800,000 synthetic data points across clinical text generation, vision-language reporting, and medical image synthesis, we find that models progressively converge toward generic phenotypes regardless of the model architecture. Specifically, rare but critical findings, including pneumothorax and effusions, vanish from the synthetic content generated by AI models, while demographic representations skew heavily toward middle-aged male phenotypes. Crucially, this degradation is masked by false diagnostic confidence; models continue to issue reassuring reports while failing to detect life-threatening pathology, with false reassurance rates tripling to 40%. Blinded physician evaluation confirms that this decoupling of confidence and accuracy renders AI-generated documentation clinically useless after just two generations. We systematically evaluate three mitigation strategies, finding that while synthetic volume scaling fails to prevent collapse, mixing real data with quality-aware filtering effectively preserves diversity. Ultimately, our results suggest that without policy-mandated human oversight, the deployment of generative AI threatens to degrade the very healthcare data ecosystems it relies upon.
RadGame: An AI-Powered Platform for Radiology Education
Sep 16, 2025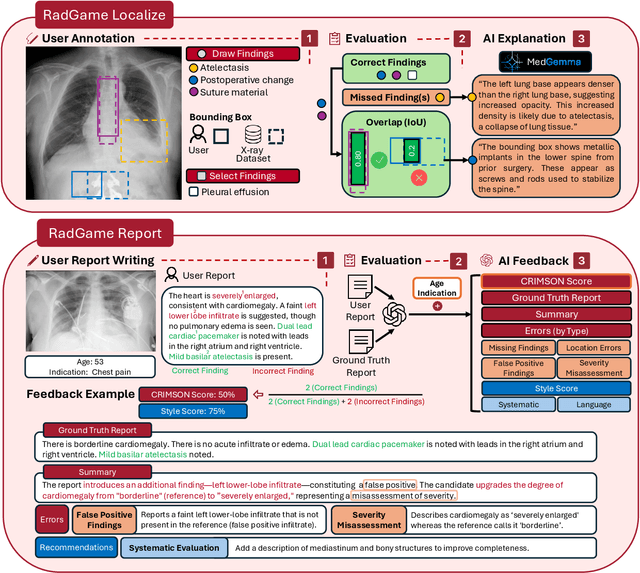
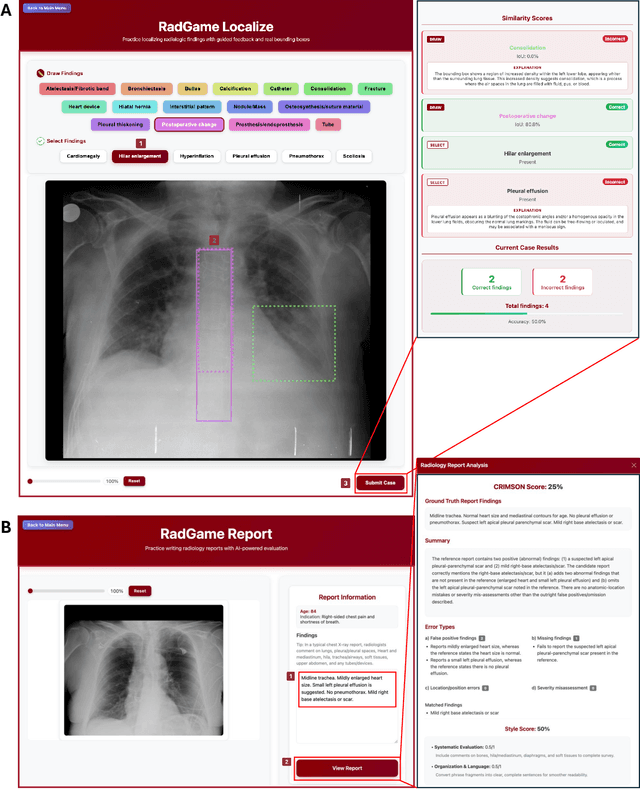
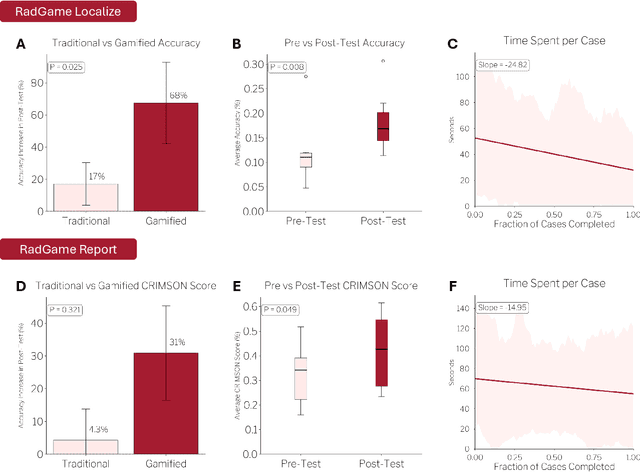

We introduce RadGame, an AI-powered gamified platform for radiology education that targets two core skills: localizing findings and generating reports. Traditional radiology training is based on passive exposure to cases or active practice with real-time input from supervising radiologists, limiting opportunities for immediate and scalable feedback. RadGame addresses this gap by combining gamification with large-scale public datasets and automated, AI-driven feedback that provides clear, structured guidance to human learners. In RadGame Localize, players draw bounding boxes around abnormalities, which are automatically compared to radiologist-drawn annotations from public datasets, and visual explanations are generated by vision-language models for user missed findings. In RadGame Report, players compose findings given a chest X-ray, patient age and indication, and receive structured AI feedback based on radiology report generation metrics, highlighting errors and omissions compared to a radiologist's written ground truth report from public datasets, producing a final performance and style score. In a prospective evaluation, participants using RadGame achieved a 68% improvement in localization accuracy compared to 17% with traditional passive methods and a 31% improvement in report-writing accuracy compared to 4% with traditional methods after seeing the same cases. RadGame highlights the potential of AI-driven gamification to deliver scalable, feedback-rich radiology training and reimagines the application of medical AI resources in education.
Construction of extra-large scale screening tools for risks of severe mental illnesses using real world healthcare data
Dec 20, 2022Importance: The prevalence of severe mental illnesses (SMIs) in the United States is approximately 3% of the whole population. The ability to conduct risk screening of SMIs at large scale could inform early prevention and treatment. Objective: A scalable machine learning based tool was developed to conduct population-level risk screening for SMIs, including schizophrenia, schizoaffective disorders, psychosis, and bipolar disorders,using 1) healthcare insurance claims and 2) electronic health records (EHRs). Design, setting and participants: Data from beneficiaries from a nationwide commercial healthcare insurer with 77.4 million members and data from patients from EHRs from eight academic hospitals based in the U.S. were used. First, the predictive models were constructed and tested using data in case-control cohorts from insurance claims or EHR data. Second, performance of the predictive models across data sources were analyzed. Third, as an illustrative application, the models were further trained to predict risks of SMIs among 18-year old young adults and individuals with substance associated conditions. Main outcomes and measures: Machine learning-based predictive models for SMIs in the general population were built based on insurance claims and EHR.
Ten Quick Tips for Deep Learning in Biology
May 29, 2021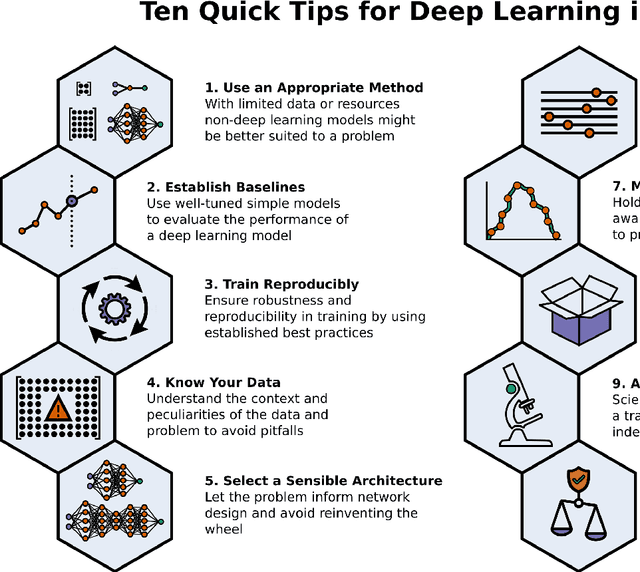
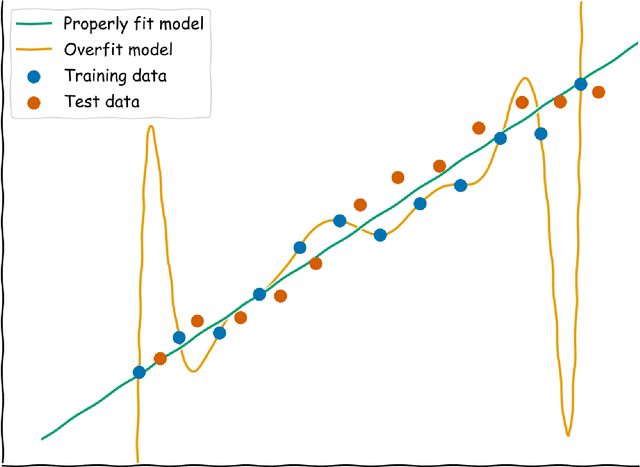
Machine learning is a modern approach to problem-solving and task automation. In particular, machine learning is concerned with the development and applications of algorithms that can recognize patterns in data and use them for predictive modeling. Artificial neural networks are a particular class of machine learning algorithms and models that evolved into what is now described as deep learning. Given the computational advances made in the last decade, deep learning can now be applied to massive data sets and in innumerable contexts. Therefore, deep learning has become its own subfield of machine learning. In the context of biological research, it has been increasingly used to derive novel insights from high-dimensional biological data. To make the biological applications of deep learning more accessible to scientists who have some experience with machine learning, we solicited input from a community of researchers with varied biological and deep learning interests. These individuals collaboratively contributed to this manuscript's writing using the GitHub version control platform and the Manubot manuscript generation toolset. The goal was to articulate a practical, accessible, and concise set of guidelines and suggestions to follow when using deep learning. In the course of our discussions, several themes became clear: the importance of understanding and applying machine learning fundamentals as a baseline for utilizing deep learning, the necessity for extensive model comparisons with careful evaluation, and the need for critical thought in interpreting results generated by deep learning, among others.