 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiCA Learns More Knowledge Than LoRA and Full Fine-Tuning
Apr 02, 2026Minor Component Adaptation (MiCA) is a novel parameter-efficient fine-tuning method for large language models that focuses on adapting underutilized subspaces of model representations. Unlike conventional methods such as Low-Rank Adaptation (LoRA), which target dominant subspaces, MiCA leverages Singular Value Decomposition to identify subspaces related to minor singular vectors associated with the least significant singular values and constrains the update of parameters during fine-tuning to those directions. This strategy leads to up to 5.9x improvement in knowledge acquisition under optimized training hyperparameters and a minimal parameter footprint of 6-60% compared to LoRA. These results suggest that constraining adaptation to minor singular directions provides a more efficient and stable mechanism for integrating new knowledge into pre-trained language models.
Deep Neural Networks for Rank-Consistent Ordinal Regression Based On Conditional Probabilities
Nov 17, 2021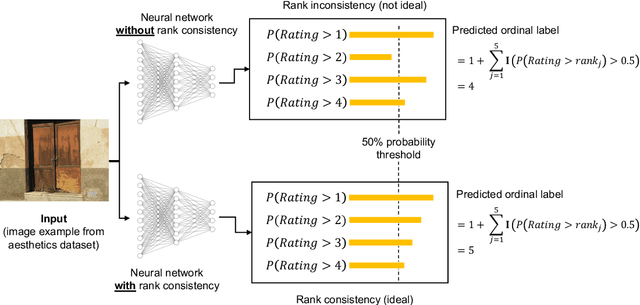
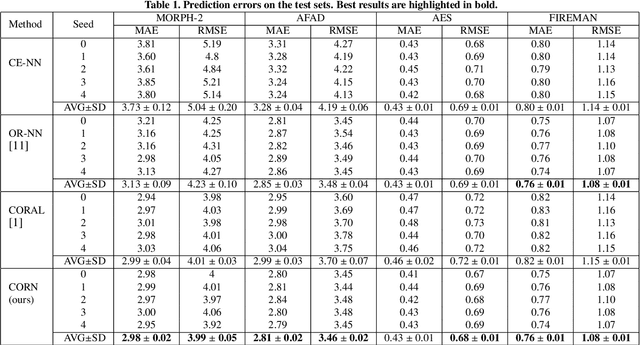
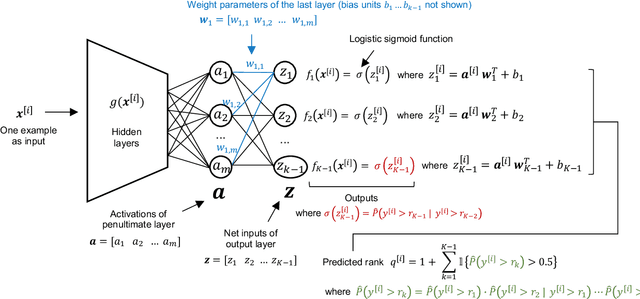
In recent times, deep neural networks achieved outstanding predictive performance on various classification and pattern recognition tasks. However, many real-world prediction problems have ordinal response variables, and this ordering information is ignored by conventional classification losses such as the multi-category cross-entropy. Ordinal regression methods for deep neural networks address this. One such method is the CORAL method, which is based on an earlier binary label extension framework and achieves rank consistency among its output layer tasks by imposing a weight-sharing constraint. However, while earlier experiments showed that CORAL's rank consistency is beneficial for performance, the weight-sharing constraint could severely restrict the expressiveness of a deep neural network. In this paper, we propose an alternative method for rank-consistent ordinal regression that does not require a weight-sharing constraint in a neural network's fully connected output layer. We achieve this rank consistency by a novel training scheme using conditional training sets to obtain the unconditional rank probabilities through applying the chain rule for conditional probability distributions. Experiments on various datasets demonstrate the efficacy of the proposed method to utilize the ordinal target information, and the absence of the weight-sharing restriction improves the performance substantially compared to the CORAL reference approach.
Deeper Learning By Doing: Integrating Hands-On Research Projects Into a Machine Learning Course
Jul 28, 2021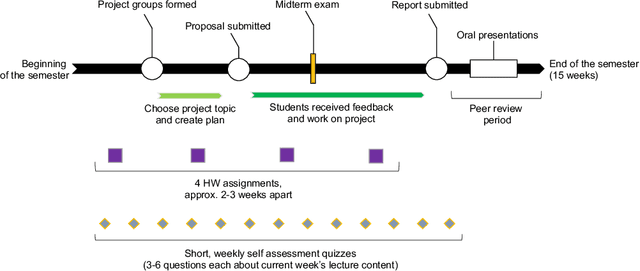
Machine learning has seen a vast increase of interest in recent years, along with an abundance of learning resources. While conventional lectures provide students with important information and knowledge, we also believe that additional project-based learning components can motivate students to engage in topics more deeply. In addition to incorporating project-based learning in our courses, we aim to develop project-based learning components aligned with real-world tasks, including experimental design and execution, report writing, oral presentation, and peer-reviewing. This paper describes the organization of our project-based machine learning courses with a particular emphasis on the class project components and shares our resources with instructors who would like to include similar elements in their courses.
Ten Quick Tips for Deep Learning in Biology
May 29, 2021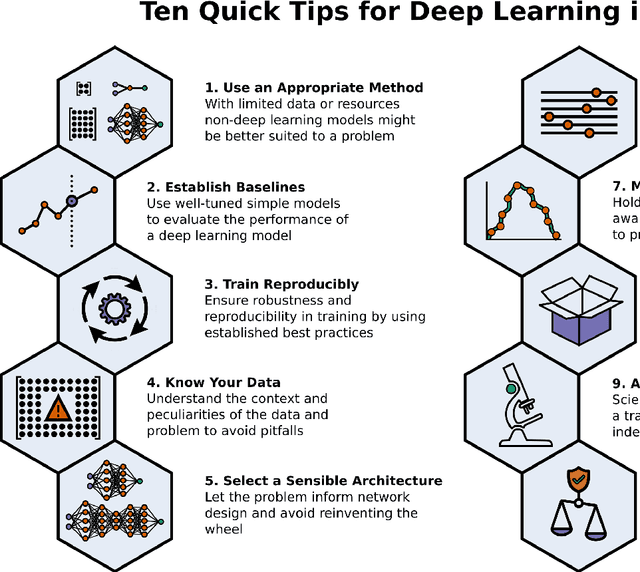
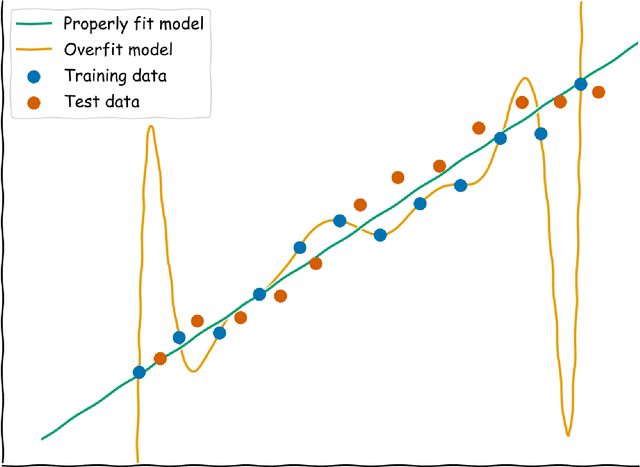
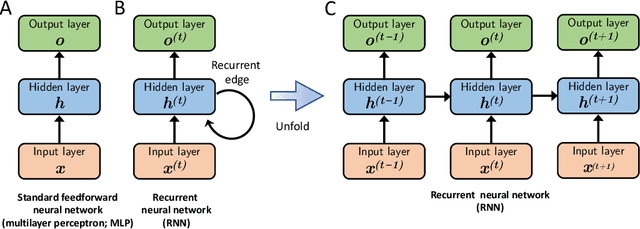
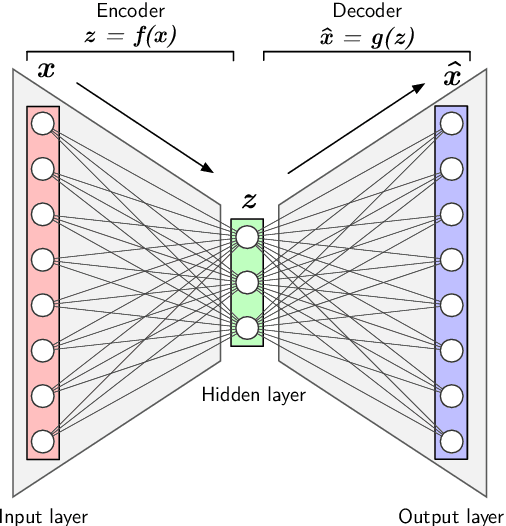
Machine learning is a modern approach to problem-solving and task automation. In particular, machine learning is concerned with the development and applications of algorithms that can recognize patterns in data and use them for predictive modeling. Artificial neural networks are a particular class of machine learning algorithms and models that evolved into what is now described as deep learning. Given the computational advances made in the last decade, deep learning can now be applied to massive data sets and in innumerable contexts. Therefore, deep learning has become its own subfield of machine learning. In the context of biological research, it has been increasingly used to derive novel insights from high-dimensional biological data. To make the biological applications of deep learning more accessible to scientists who have some experience with machine learning, we solicited input from a community of researchers with varied biological and deep learning interests. These individuals collaboratively contributed to this manuscript's writing using the GitHub version control platform and the Manubot manuscript generation toolset. The goal was to articulate a practical, accessible, and concise set of guidelines and suggestions to follow when using deep learning. In the course of our discussions, several themes became clear: the importance of understanding and applying machine learning fundamentals as a baseline for utilizing deep learning, the necessity for extensive model comparisons with careful evaluation, and the need for critical thought in interpreting results generated by deep learning, among others.
Few-Shot Learning for Video Object Detection in a Transfer-Learning Scheme
Mar 30, 2021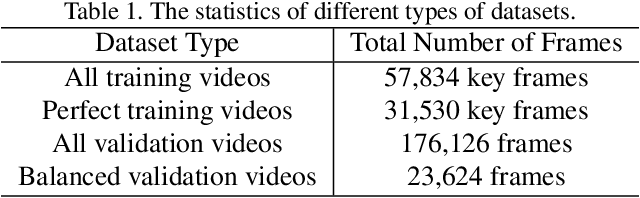
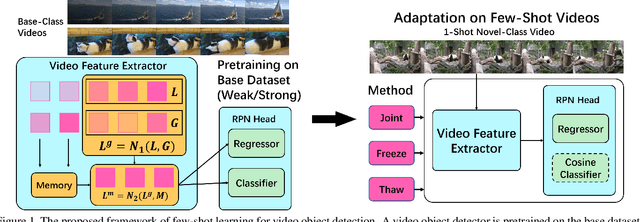
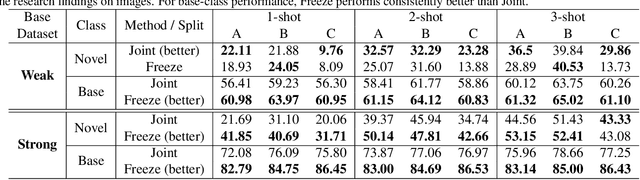
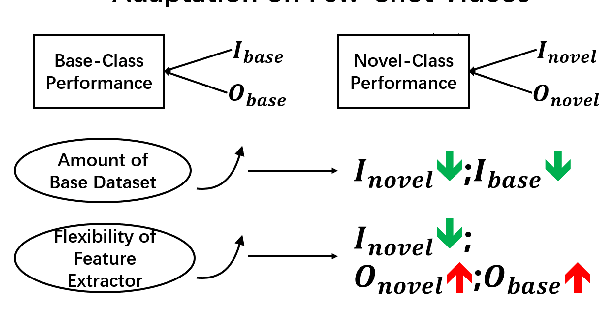
Different from static images, videos contain additional temporal and spatial information for better object detection. However, it is costly to obtain a large number of videos with bounding box annotations that are required for supervised deep learning. Although humans can easily learn to recognize new objects by watching only a few video clips, deep learning usually suffers from overfitting. This leads to an important question: how to effectively learn a video object detector from only a few labeled video clips? In this paper, we study the new problem of few-shot learning for video object detection. We first define the few-shot setting and create a new benchmark dataset for few-shot video object detection derived from the widely used ImageNet VID dataset. We employ a transfer-learning framework to effectively train the video object detector on a large number of base-class objects and a few video clips of novel-class objects. By analyzing the results of two methods under this framework (Joint and Freeze) on our designed weak and strong base datasets, we reveal insufficiency and overfitting problems. A simple but effective method, called Thaw, is naturally developed to trade off the two problems and validate our analysis. Extensive experiments on our proposed benchmark datasets with different scenarios demonstrate the effectiveness of our novel analysis in this new few-shot video object detection problem.
Visual Framing of Science Conspiracy Videos: Integrating Machine Learning with Communication Theories to Study the Use of Color and Brightness
Feb 01, 2021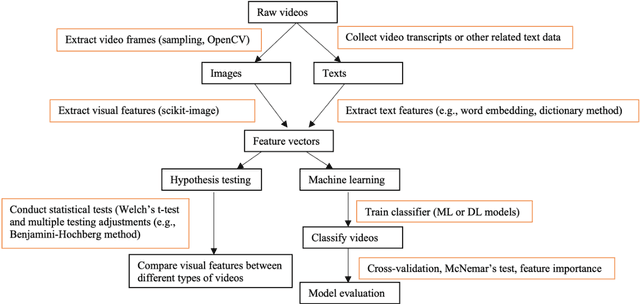
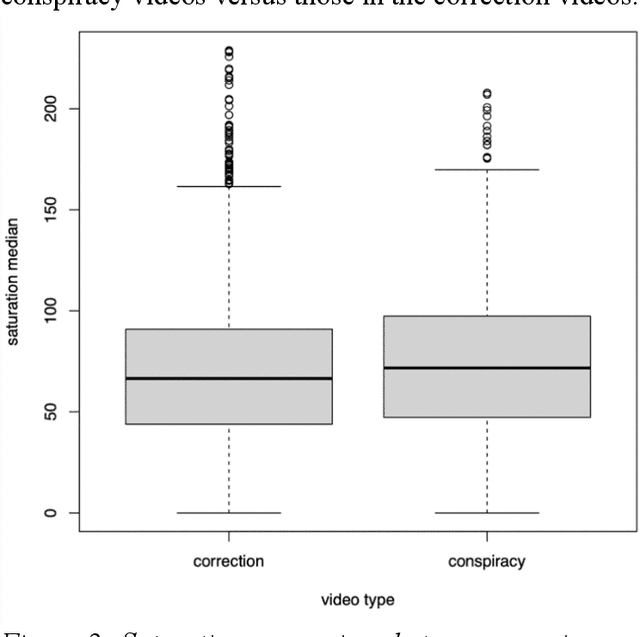
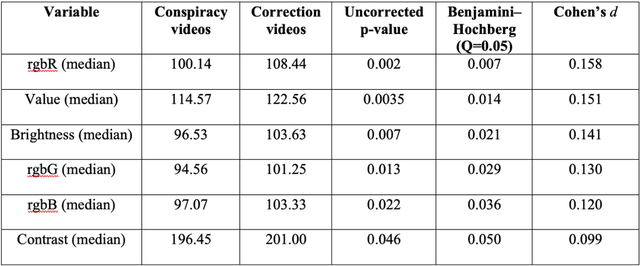
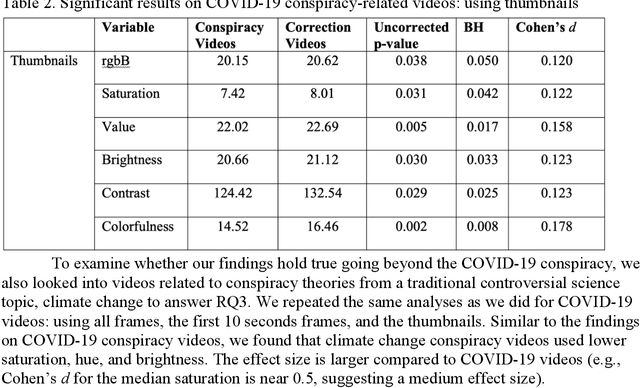
Recent years have witnessed an explosion of science conspiracy videos on the Internet, challenging science epistemology and public understanding of science. Scholars have started to examine the persuasion techniques used in conspiracy messages such as uncertainty and fear yet, little is understood about the visual narratives, especially how visual narratives differ in videos that debunk conspiracies versus those that propagate conspiracies. This paper addresses this gap in understanding visual framing in conspiracy videos through analyzing millions of frames from conspiracy and counter-conspiracy YouTube videos using computational methods. We found that conspiracy videos tended to use lower color variance and brightness, especially in thumbnails and earlier parts of the videos. This paper also demonstrates how researchers can integrate textual and visual features for identifying conspiracies on social media and discusses the implications of computational modeling for scholars interested in studying visual manipulation in the digital era.
Looking back to lower-level information in few-shot learning
May 27, 2020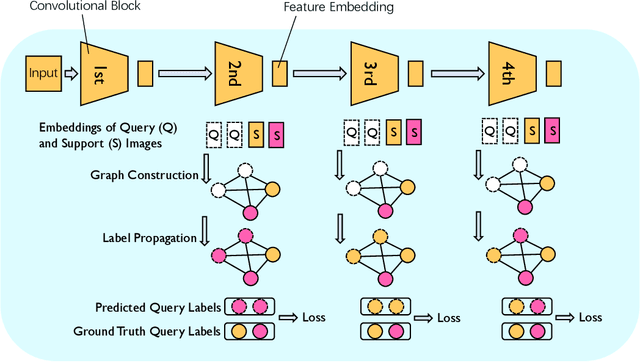
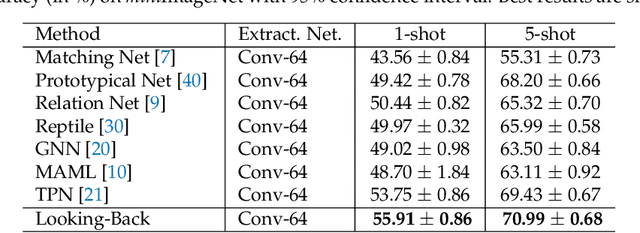

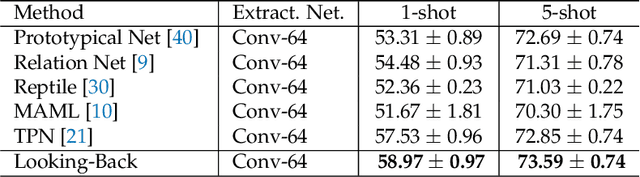
Humans are capable of learning new concepts from small numbers of examples. In contrast, supervised deep learning models usually lack the ability to extract reliable predictive rules from limited data scenarios when attempting to classify new examples. This challenging scenario is commonly known as few-shot learning. Few-shot learning has garnered increased attention in recent years due to its significance for many real-world problems. Recently, new methods relying on meta-learning paradigms combined with graph-based structures, which model the relationship between examples, have shown promising results on a variety of few-shot classification tasks. However, existing work on few-shot learning is only focused on the feature embeddings produced by the last layer of the neural network. In this work, we propose the utilization of lower-level, supporting information, namely the feature embeddings of the hidden neural network layers, to improve classifier accuracy. Based on a graph-based meta-learning framework, we develop a method called Looking-Back, where such lower-level information is used to construct additional graphs for label propagation in limited data settings. Our experiments on two popular few-shot learning datasets, miniImageNet and tieredImageNet, show that our method can utilize the lower-level information in the network to improve state-of-the-art classification performance.
PrivacyNet: Semi-Adversarial Networks for Multi-attribute Face Privacy
Feb 14, 2020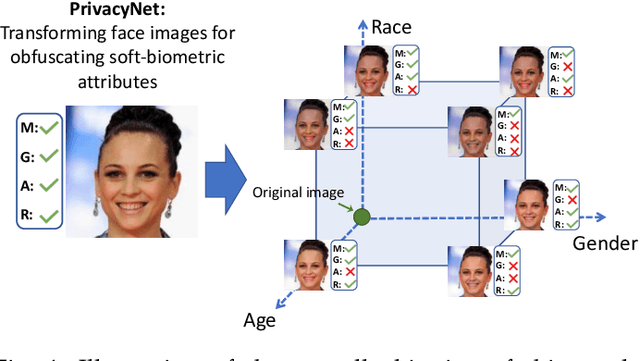
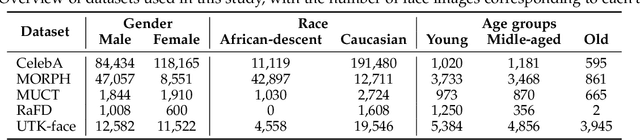
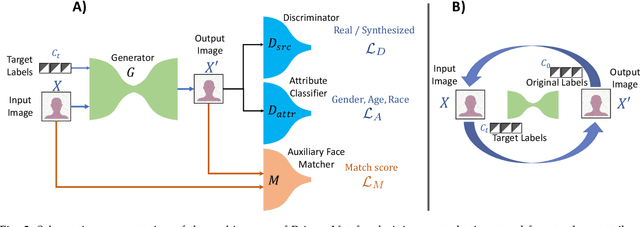
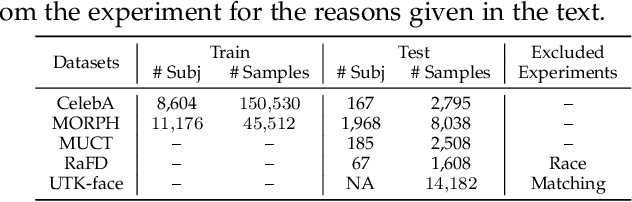
Recent research has established the possibility of deducing soft-biometric attributes such as age, gender and race from an individual's face image with high accuracy. However, this raises privacy concerns, especially when face images collected for biometric recognition purposes are used for attribute analysis without the person's consent. To address this problem, we develop a technique for imparting soft biometric privacy to face images via an image perturbation methodology. The image perturbation is undertaken using a GAN-based Semi-Adversarial Network (SAN) - referred to as PrivacyNet - that modifies an input face image such that it can be used by a face matcher for matching purposes but cannot be reliably used by an attribute classifier. Further, PrivacyNet allows a person to choose specific attributes that have to be obfuscated in the input face images (e.g., age and race), while allowing for other types of attributes to be extracted (e.g., gender). Extensive experiments using multiple face matchers, multiple age/gender/race classifiers, and multiple face datasets demonstrate the generalizability of the proposed multi-attribute privacy enhancing method across multiple face and attribute classifiers.
Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence
Feb 12, 2020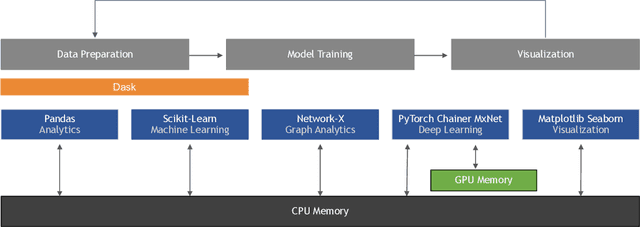
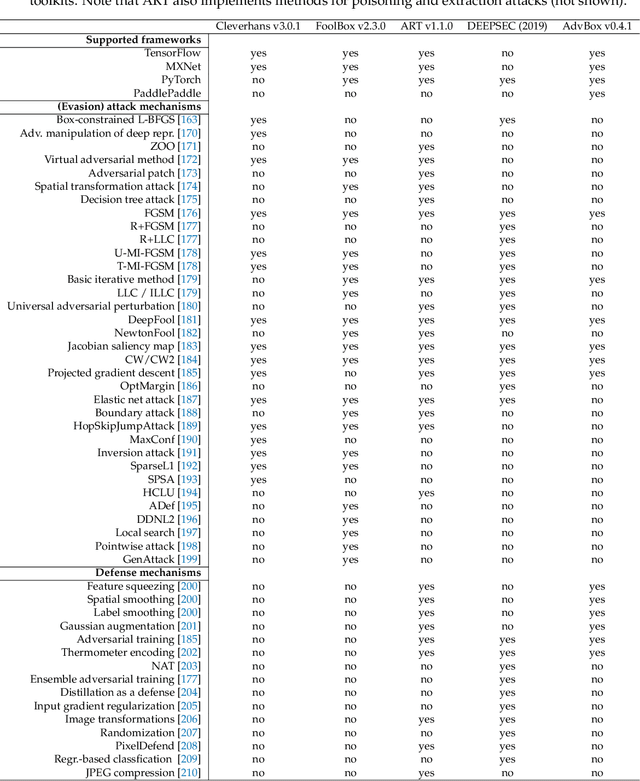
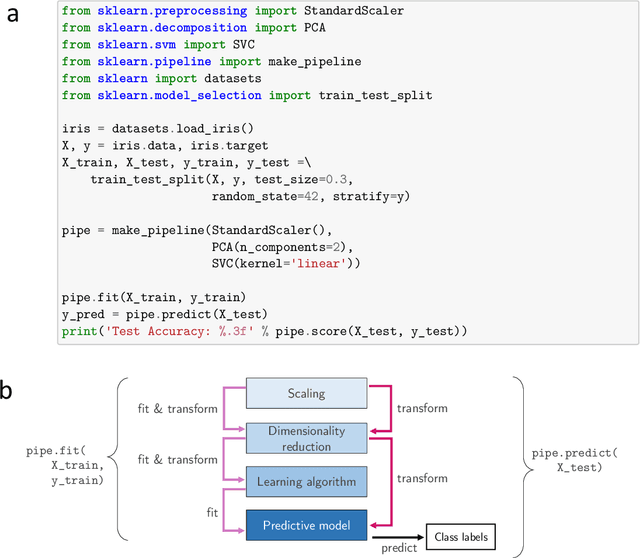

Smarter applications are making better use of the insights gleaned from data, having an impact on every industry and research discipline. At the core of this revolution lies the tools and the methods that are driving it, from processing the massive piles of data generated each day to learning from and taking useful action. Deep neural networks, along with advancements in classical ML and scalable general-purpose GPU computing, have become critical components of artificial intelligence, enabling many of these astounding breakthroughs and lowering the barrier to adoption. Python continues to be the most preferred language for scientific computing, data science, and machine learning, boosting both performance and productivity by enabling the use of low-level libraries and clean high-level APIs. This survey offers insight into the field of machine learning with Python, taking a tour through important topics to identify some of the core hardware and software paradigms that have enabled it. We cover widely-used libraries and concepts, collected together for holistic comparison, with the goal of educating the reader and driving the field of Python machine learning forward.
Machine learning and AI-based approaches for bioactive ligand discovery and GPCR-ligand recognition
Jan 22, 2020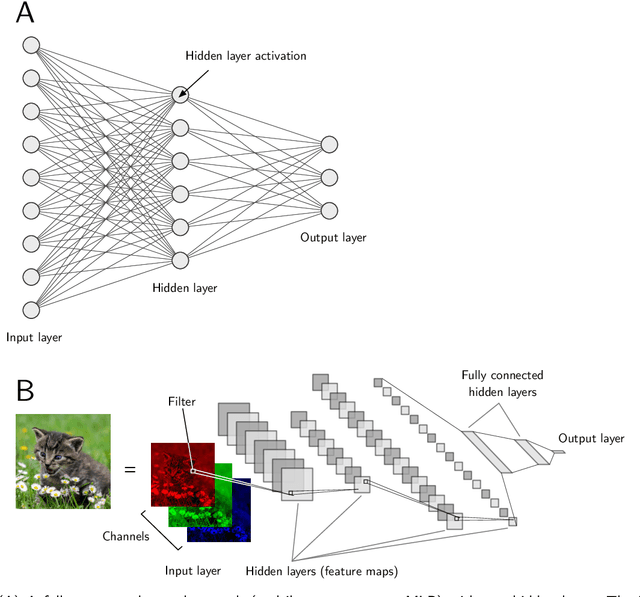
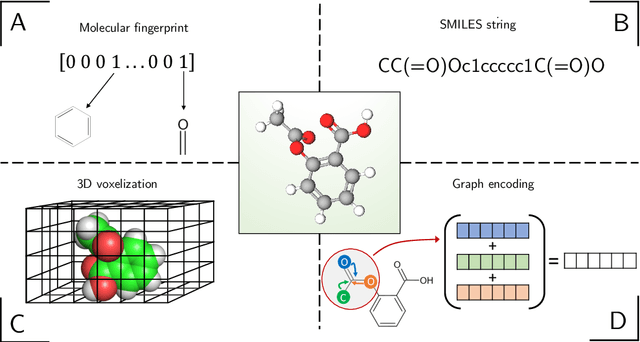
In the last decade, machine learning and artificial intelligence applications have received a significant boost in performance and attention in both academic research and industry. The success behind most of the recent state-of-the-art methods can be attributed to the latest developments in deep learning. When applied to various scientific domains that are concerned with the processing of non-tabular data, for example, image or text, deep learning has been shown to outperform not only conventional machine learning but also highly specialized tools developed by domain experts. This review aims to summarize AI-based research for GPCR bioactive ligand discovery with a particular focus on the most recent achievements and research trends. To make this article accessible to a broad audience of computational scientists, we provide instructive explanations of the underlying methodology, including overviews of the most commonly used deep learning architectures and feature representations of molecular data. We highlight the latest AI-based research that has led to the successful discovery of GPCR bioactive ligands. However, an equal focus of this review is on the discussion of machine learning-based technology that has been applied to ligand discovery in general and has the potential to pave the way for successful GPCR bioactive ligand discovery in the future. This review concludes with a brief outlook highlighting the recent research trends in deep learning, such as active learning and semi-supervised learning, which have great potential for advancing bioactive ligand discovery.