 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusivity in Large Language Models: Personality Traits and Gender Bias in Scientific Abstracts
Jun 27, 2024

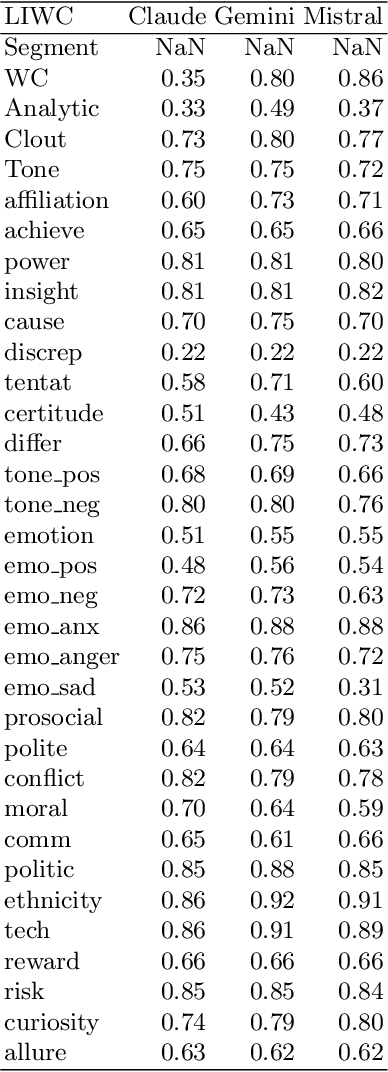
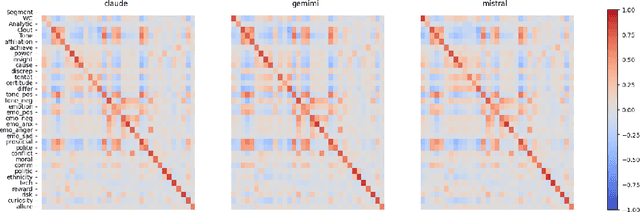
Large language models (LLMs) are increasingly utilized to assist in scientific and academic writing, helping authors enhance the coherence of their articles. Previous studies have highlighted stereotypes and biases present in LLM outputs, emphasizing the need to evaluate these models for their alignment with human narrative styles and potential gender biases. In this study, we assess the alignment of three prominent LLMs - Claude 3 Opus, Mistral AI Large, and Gemini 1.5 Flash - by analyzing their performance on benchmark text-generation tasks for scientific abstracts. We employ the Linguistic Inquiry and Word Count (LIWC) framework to extract lexical, psychological, and social features from the generated texts. Our findings indicate that, while these models generally produce text closely resembling human authored content, variations in stylistic features suggest significant gender biases. This research highlights the importance of developing LLMs that maintain a diversity of writing styles to promote inclusivity in academic discourse.
Computing in the Life Sciences: From Early Algorithms to Modern AI
Jun 17, 2024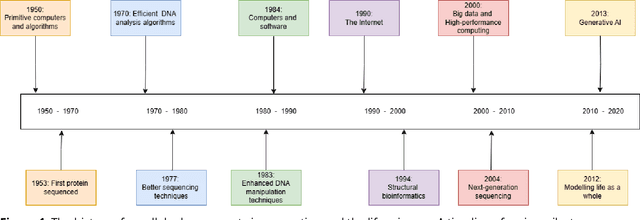
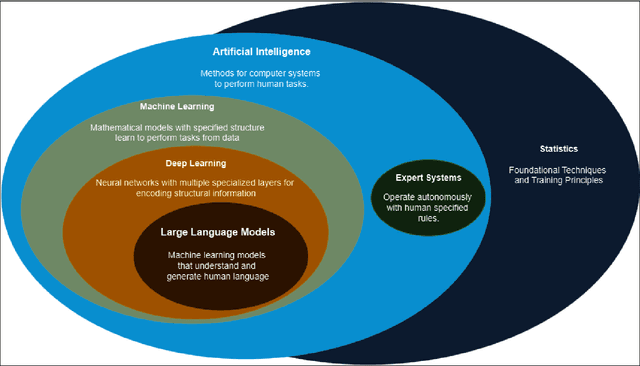

Computing in the life sciences has undergone a transformative evolution, from early computational models in the 1950s to the applications of artificial intelligence (AI) and machine learning (ML) seen today. This paper highlights key milestones and technological advancements through the historical development of computing in the life sciences. The discussion includes the inception of computational models for biological processes, the advent of bioinformatics tools, and the integration of AI/ML in modern life sciences research. Attention is given to AI-enabled tools used in the life sciences, such as scientific large language models and bio-AI tools, examining their capabilities, limitations, and impact to biological risk. This paper seeks to clarify and establish essential terminology and concepts to ensure informed decision-making and effective communication across disciplines.
NHANES-GCP: Leveraging the Google Cloud Platform and BigQuery ML for reproducible machine learning with data from the National Health and Nutrition Examination Survey
Jan 13, 2024Summary: NHANES, the National Health and Nutrition Examination Survey, is a program of studies led by the Centers for Disease Control and Prevention (CDC) designed to assess the health and nutritional status of adults and children in the United States (U.S.). NHANES data is frequently used by biostatisticians and clinical scientists to study health trends across the U.S., but every analysis requires extensive data management and cleaning before use and this repetitive data engineering collectively costs valuable research time and decreases the reproducibility of analyses. Here, we introduce NHANES-GCP, a Cloud Development Kit for Terraform (CDKTF) Infrastructure-as-Code (IaC) and Data Build Tool (dbt) resources built on the Google Cloud Platform (GCP) that automates the data engineering and management aspects of working with NHANES data. With current GCP pricing, NHANES-GCP costs less than $2 to run and less than $15/yr of ongoing costs for hosting the NHANES data, all while providing researchers with clean data tables that can readily be integrated for large-scale analyses. We provide examples of leveraging BigQuery ML to carry out the process of selecting data, integrating data, training machine learning and statistical models, and generating results all from a single SQL-like query. NHANES-GCP is designed to enhance the reproducibility of analyses and create a well-engineered NHANES data resource for statistics, machine learning, and fine-tuning Large Language Models (LLMs). Availability and implementation" NHANES-GCP is available at https://github.com/In-Vivo-Group/NHANES-GCP
The Promise and Peril of Artificial Intelligence -- Violet Teaming Offers a Balanced Path Forward
Aug 28, 2023Artificial intelligence (AI) promises immense benefits across sectors, yet also poses risks from dual-use potentials, biases, and unintended behaviors. This paper reviews emerging issues with opaque and uncontrollable AI systems and proposes an integrative framework called violet teaming to develop reliable and responsible AI. Violet teaming combines adversarial vulnerability probing (red teaming) with solutions for safety and security (blue teaming) while prioritizing ethics and social benefit. It emerged from AI safety research to manage risks proactively by design. The paper traces the evolution of red, blue, and purple teaming toward violet teaming, and then discusses applying violet techniques to address biosecurity risks of AI in biotechnology. Additional sections review key perspectives across law, ethics, cybersecurity, macrostrategy, and industry best practices essential for operationalizing responsible AI through holistic technical and social considerations. Violet teaming provides both philosophy and method for steering AI trajectories toward societal good. With conscience and wisdom, the extraordinary capabilities of AI can enrich humanity. But without adequate precaution, the risks could prove catastrophic. Violet teaming aims to empower moral technology for the common welfare.
Elephants and Algorithms: A Review of the Current and Future Role of AI in Elephant Monitoring
Jun 23, 2023Artificial intelligence (AI) and machine learning (ML) present revolutionary opportunities to enhance our understanding of animal behavior and conservation strategies. Using elephants, a crucial species in Africa's protected areas, as our focal point, we delve into the role of AI and ML in their conservation. Given the increasing amounts of data gathered from a variety of sensors like cameras, microphones, geophones, drones, and satellites, the challenge lies in managing and interpreting this vast data. New AI and ML techniques offer solutions to streamline this process, helping us extract vital information that might otherwise be overlooked. This paper focuses on the different AI-driven monitoring methods and their potential for improving elephant conservation. Collaborative efforts between AI experts and ecological researchers are essential in leveraging these innovative technologies for enhanced wildlife conservation, setting a precedent for numerous other species.
Ten Quick Tips for Deep Learning in Biology
May 29, 2021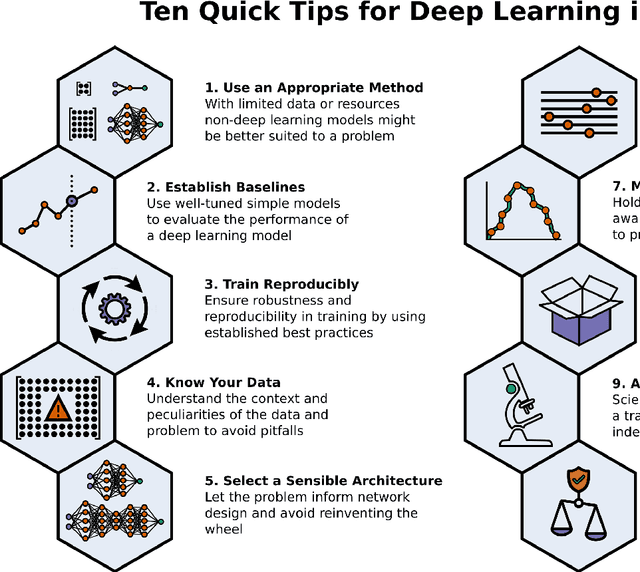
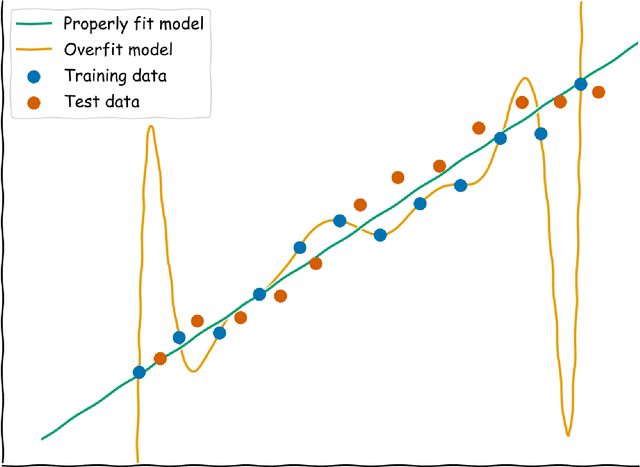
Machine learning is a modern approach to problem-solving and task automation. In particular, machine learning is concerned with the development and applications of algorithms that can recognize patterns in data and use them for predictive modeling. Artificial neural networks are a particular class of machine learning algorithms and models that evolved into what is now described as deep learning. Given the computational advances made in the last decade, deep learning can now be applied to massive data sets and in innumerable contexts. Therefore, deep learning has become its own subfield of machine learning. In the context of biological research, it has been increasingly used to derive novel insights from high-dimensional biological data. To make the biological applications of deep learning more accessible to scientists who have some experience with machine learning, we solicited input from a community of researchers with varied biological and deep learning interests. These individuals collaboratively contributed to this manuscript's writing using the GitHub version control platform and the Manubot manuscript generation toolset. The goal was to articulate a practical, accessible, and concise set of guidelines and suggestions to follow when using deep learning. In the course of our discussions, several themes became clear: the importance of understanding and applying machine learning fundamentals as a baseline for utilizing deep learning, the necessity for extensive model comparisons with careful evaluation, and the need for critical thought in interpreting results generated by deep learning, among others.