 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusivity in Large Language Models: Personality Traits and Gender Bias in Scientific Abstracts
Paper and Code
Jun 27, 2024

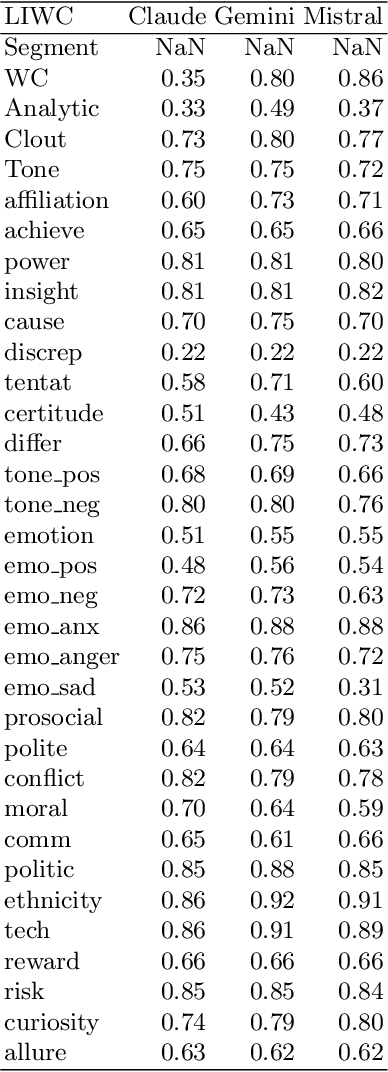
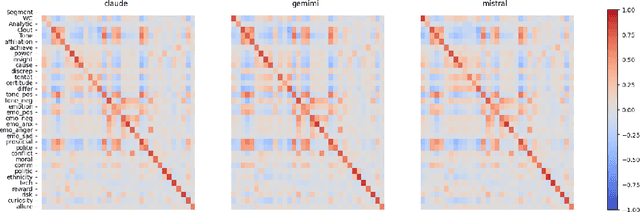
Large language models (LLMs) are increasingly utilized to assist in scientific and academic writing, helping authors enhance the coherence of their articles. Previous studies have highlighted stereotypes and biases present in LLM outputs, emphasizing the need to evaluate these models for their alignment with human narrative styles and potential gender biases. In this study, we assess the alignment of three prominent LLMs - Claude 3 Opus, Mistral AI Large, and Gemini 1.5 Flash - by analyzing their performance on benchmark text-generation tasks for scientific abstracts. We employ the Linguistic Inquiry and Word Count (LIWC) framework to extract lexical, psychological, and social features from the generated texts. Our findings indicate that, while these models generally produce text closely resembling human authored content, variations in stylistic features suggest significant gender biases. This research highlights the importance of developing LLMs that maintain a diversity of writing styles to promote inclusivity in academic discourse.