 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sociotechnical Lens for Evaluating Computer Vision Models: A Case Study on Detecting and Reasoning about Gender and Emotion
Jun 12, 2024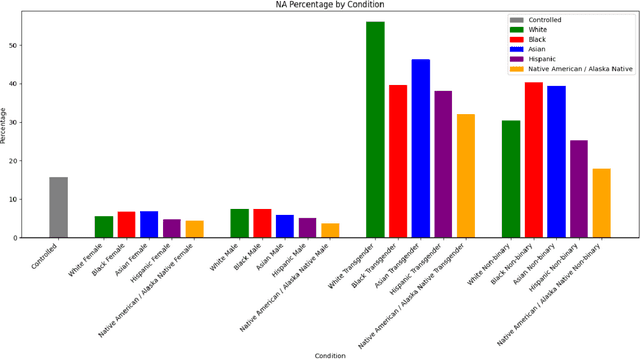
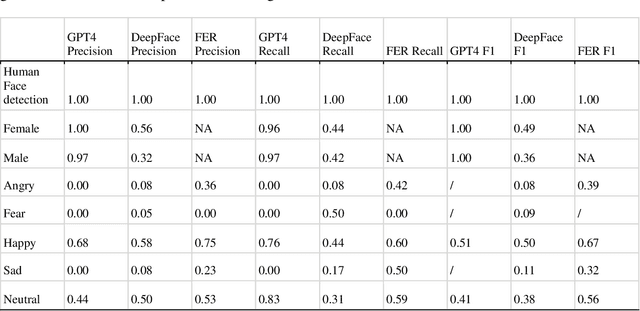
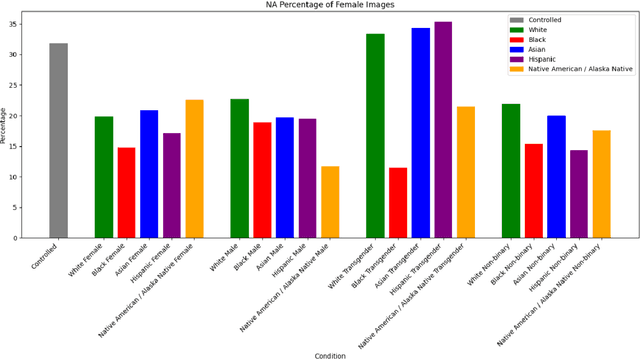
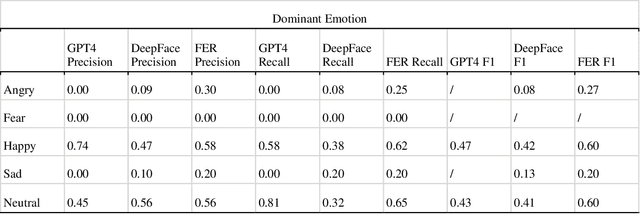
In the evolving landscape of computer vision (CV) technologies, the automatic detection and interpretation of gender and emotion in images is a critical area of study. This paper investigates social biases in CV models, emphasizing the limitations of traditional evaluation metrics such as precision, recall, and accuracy. These metrics often fall short in capturing the complexities of gender and emotion, which are fluid and culturally nuanced constructs. Our study proposes a sociotechnical framework for evaluating CV models, incorporating both technical performance measures and considerations of social fairness. Using a dataset of 5,570 images related to vaccination and climate change, we empirically compared the performance of various CV models, including traditional models like DeepFace and FER, and generative models like GPT-4 Vision. Our analysis involved manually validating the gender and emotional expressions in a subset of images to serve as benchmarks. Our findings reveal that while GPT-4 Vision outperforms other models in technical accuracy for gender classification, it exhibits discriminatory biases, particularly in response to transgender and non-binary personas. Furthermore, the model's emotion detection skew heavily towards positive emotions, with a notable bias towards associating female images with happiness, especially when prompted by male personas. These findings underscore the necessity of developing more comprehensive evaluation criteria that address both validity and discriminatory biases in CV models. Our proposed framework provides guidelines for researchers to critically assess CV tools, ensuring their application in communication research is both ethical and effective. The significant contribution of this study lies in its emphasis on a sociotechnical approach, advocating for CV technologies that support social good and mitigate biases rather than perpetuate them.
Visual Framing of Science Conspiracy Videos: Integrating Machine Learning with Communication Theories to Study the Use of Color and Brightness
Feb 01, 2021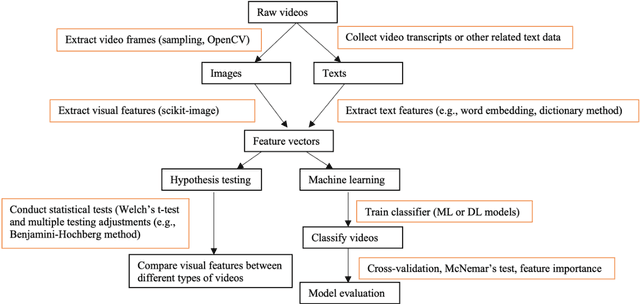
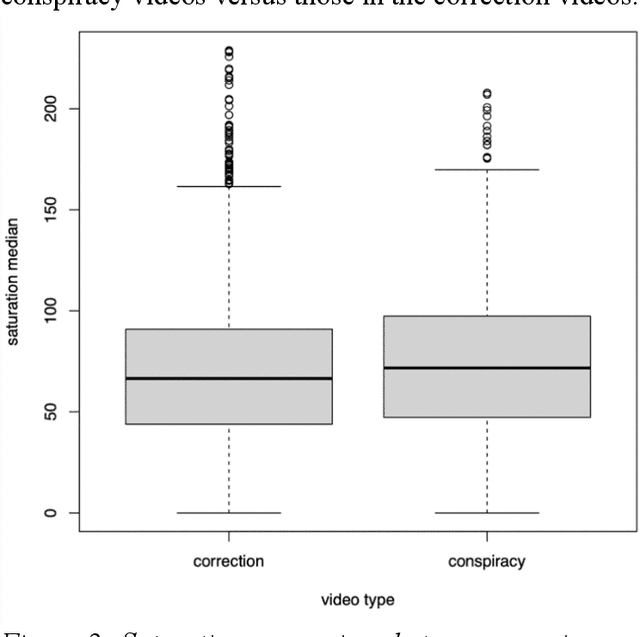
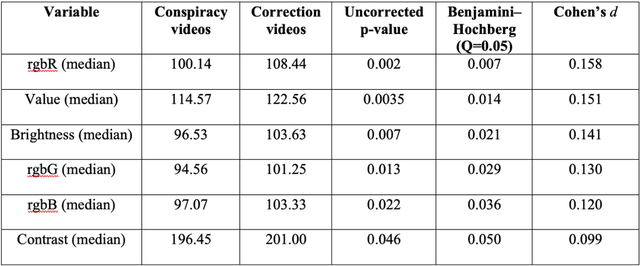
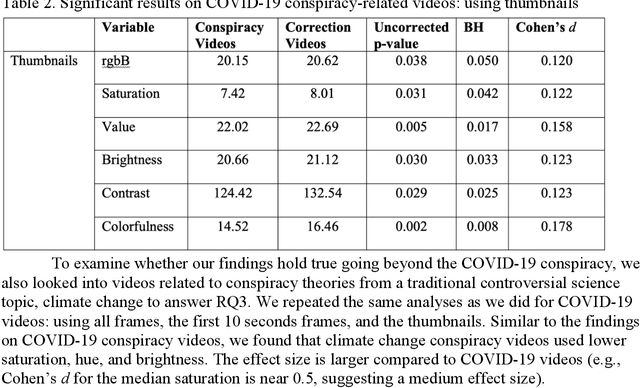
Recent years have witnessed an explosion of science conspiracy videos on the Internet, challenging science epistemology and public understanding of science. Scholars have started to examine the persuasion techniques used in conspiracy messages such as uncertainty and fear yet, little is understood about the visual narratives, especially how visual narratives differ in videos that debunk conspiracies versus those that propagate conspiracies. This paper addresses this gap in understanding visual framing in conspiracy videos through analyzing millions of frames from conspiracy and counter-conspiracy YouTube videos using computational methods. We found that conspiracy videos tended to use lower color variance and brightness, especially in thumbnails and earlier parts of the videos. This paper also demonstrates how researchers can integrate textual and visual features for identifying conspiracies on social media and discusses the implications of computational modeling for scholars interested in studying visual manipulation in the digital era.