 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sociotechnical Lens for Evaluating Computer Vision Models: A Case Study on Detecting and Reasoning about Gender and Emotion
Jun 12, 2024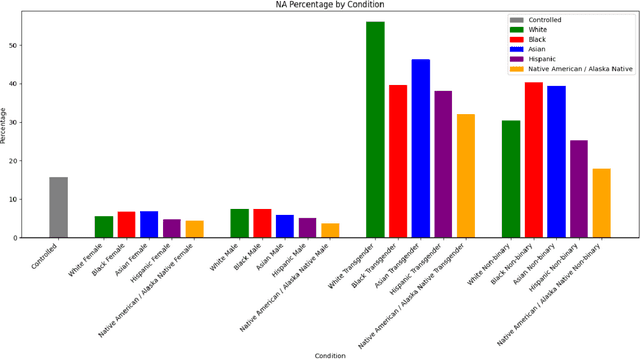
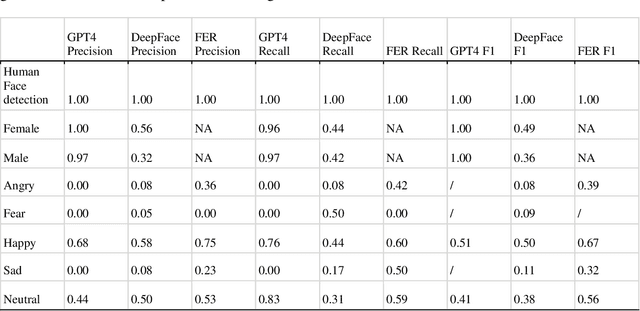
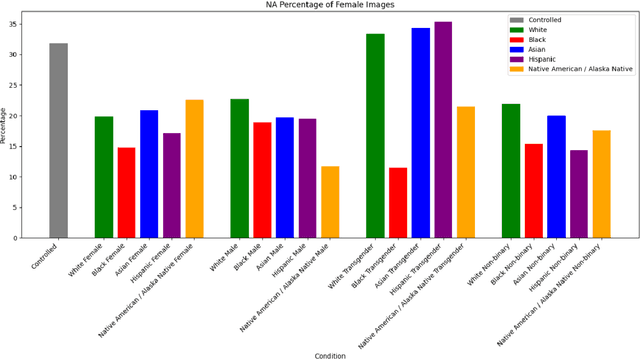
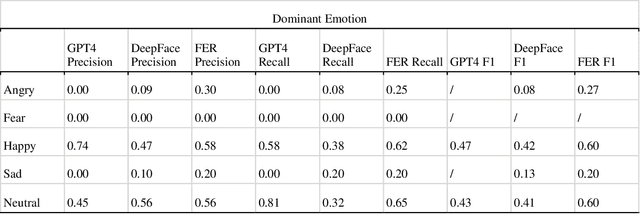
In the evolving landscape of computer vision (CV) technologies, the automatic detection and interpretation of gender and emotion in images is a critical area of study. This paper investigates social biases in CV models, emphasizing the limitations of traditional evaluation metrics such as precision, recall, and accuracy. These metrics often fall short in capturing the complexities of gender and emotion, which are fluid and culturally nuanced constructs. Our study proposes a sociotechnical framework for evaluating CV models, incorporating both technical performance measures and considerations of social fairness. Using a dataset of 5,570 images related to vaccination and climate change, we empirically compared the performance of various CV models, including traditional models like DeepFace and FER, and generative models like GPT-4 Vision. Our analysis involved manually validating the gender and emotional expressions in a subset of images to serve as benchmarks. Our findings reveal that while GPT-4 Vision outperforms other models in technical accuracy for gender classification, it exhibits discriminatory biases, particularly in response to transgender and non-binary personas. Furthermore, the model's emotion detection skew heavily towards positive emotions, with a notable bias towards associating female images with happiness, especially when prompted by male personas. These findings underscore the necessity of developing more comprehensive evaluation criteria that address both validity and discriminatory biases in CV models. Our proposed framework provides guidelines for researchers to critically assess CV tools, ensuring their application in communication research is both ethical and effective. The significant contribution of this study lies in its emphasis on a sociotechnical approach, advocating for CV technologies that support social good and mitigate biases rather than perpetuate them.
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.