 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiskCueBench: Benchmarking Anticipatory Reasoning from Early Risk Cues in Video-Language Models
Jan 06, 2026With the rapid growth of video centered social media, the ability to anticipate risky events from visual data is a promising direction for ensuring public safety and preventing real world accidents. Prior work has extensively studied supervised video risk assessment across domains such as driving, protests, and natural disasters. However, many existing datasets provide models with access to the full video sequence, including the accident itself, which substantially reduces the difficulty of the task. To better reflect real world conditions, we introduce a new video understanding benchmark RiskCueBench in which videos are carefully annotated to identify a risk signal clip, defined as the earliest moment that indicates a potential safety concern. Experimental results reveal a significant gap in current systems ability to interpret evolving situations and anticipate future risky events from early visual signals, highlighting important challenges for deploying video risk prediction models in practice.
Versatile Distributed Maneuvering with Generalized Formations using Guiding Vector Fields
May 09, 2025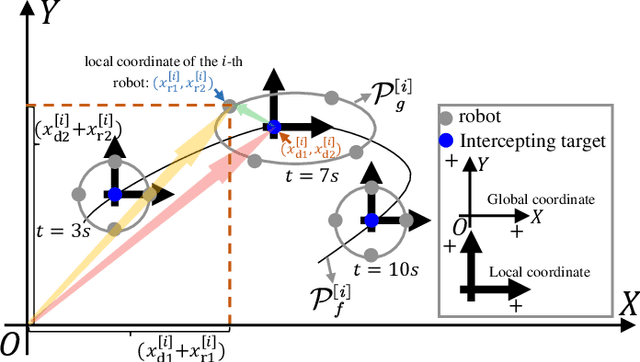
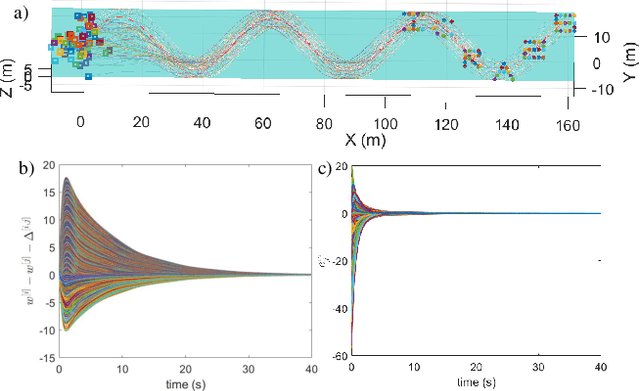
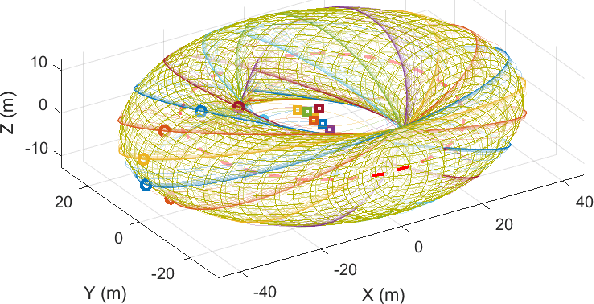
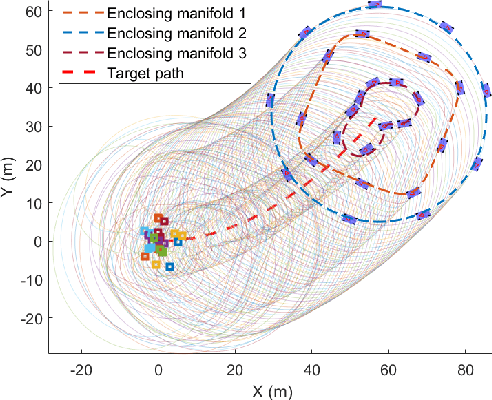
This paper presents a unified approach to realize versatile distributed maneuvering with generalized formations. Specifically, we decompose the robots' maneuvers into two independent components, i.e., interception and enclosing, which are parameterized by two independent virtual coordinates. Treating these two virtual coordinates as dimensions of an abstract manifold, we derive the corresponding singularity-free guiding vector field (GVF), which, along with a distributed coordination mechanism based on the consensus theory, guides robots to achieve various motions (i.e., versatile maneuvering), including (a) formation tracking, (b) target enclosing, and (c) circumnavigation. Additional motion parameters can generate more complex cooperative robot motions. Based on GVFs, we design a controller for a nonholonomic robot model. Besides the theoretical results, extensive simulations and experiments are performed to validate the effectiveness of the approach.
A Sociotechnical Lens for Evaluating Computer Vision Models: A Case Study on Detecting and Reasoning about Gender and Emotion
Jun 12, 2024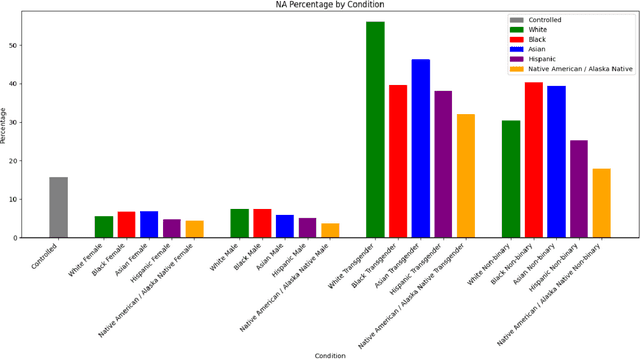
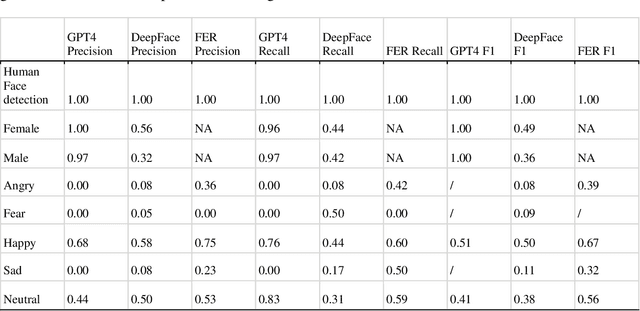
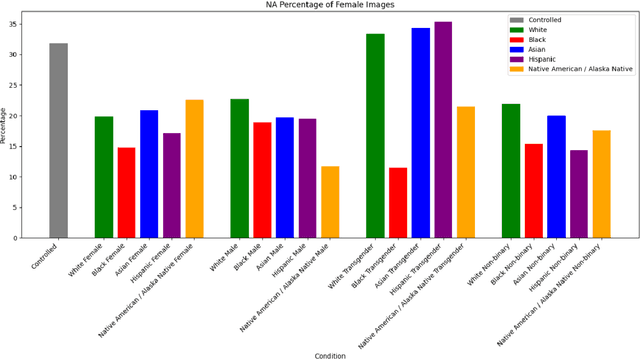
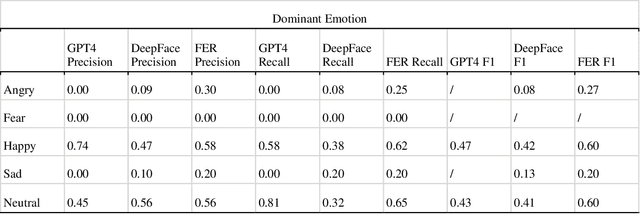
In the evolving landscape of computer vision (CV) technologies, the automatic detection and interpretation of gender and emotion in images is a critical area of study. This paper investigates social biases in CV models, emphasizing the limitations of traditional evaluation metrics such as precision, recall, and accuracy. These metrics often fall short in capturing the complexities of gender and emotion, which are fluid and culturally nuanced constructs. Our study proposes a sociotechnical framework for evaluating CV models, incorporating both technical performance measures and considerations of social fairness. Using a dataset of 5,570 images related to vaccination and climate change, we empirically compared the performance of various CV models, including traditional models like DeepFace and FER, and generative models like GPT-4 Vision. Our analysis involved manually validating the gender and emotional expressions in a subset of images to serve as benchmarks. Our findings reveal that while GPT-4 Vision outperforms other models in technical accuracy for gender classification, it exhibits discriminatory biases, particularly in response to transgender and non-binary personas. Furthermore, the model's emotion detection skew heavily towards positive emotions, with a notable bias towards associating female images with happiness, especially when prompted by male personas. These findings underscore the necessity of developing more comprehensive evaluation criteria that address both validity and discriminatory biases in CV models. Our proposed framework provides guidelines for researchers to critically assess CV tools, ensuring their application in communication research is both ethical and effective. The significant contribution of this study lies in its emphasis on a sociotechnical approach, advocating for CV technologies that support social good and mitigate biases rather than perpetuate them.
Reinforcement Learning in Robotic Motion Planning by Combined Experience-based Planning and Self-Imitation Learning
Jun 11, 2023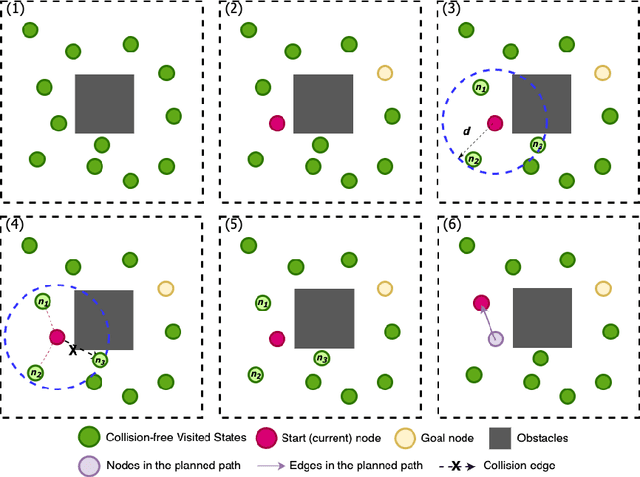

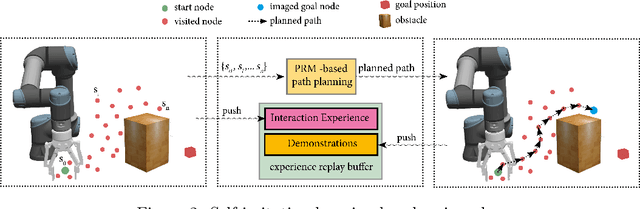

High-quality and representative data is essential for both Imitation Learning (IL)- and Reinforcement Learning (RL)-based motion planning tasks. For real robots, it is challenging to collect enough qualified data either as demonstrations for IL or experiences for RL due to safety considerations in environments with obstacles. We target this challenge by proposing the self-imitation learning by planning plus (SILP+) algorithm, which efficiently embeds experience-based planning into the learning architecture to mitigate the data-collection problem. The planner generates demonstrations based on successfully visited states from the current RL policy, and the policy improves by learning from these demonstrations. In this way, we relieve the demand for human expert operators to collect demonstrations required by IL and improve the RL performance as well. Various experimental results show that SILP+ achieves better training efficiency higher and more stable success rate in complex motion planning tasks compared to several other methods. Extensive tests on physical robots illustrate the effectiveness of SILP+ in a physical setting.
Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains
Jun 03, 2021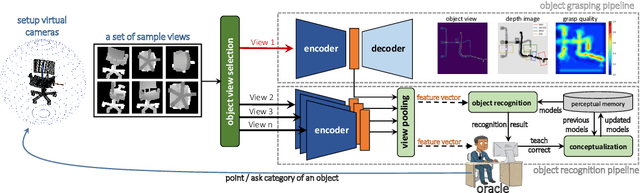
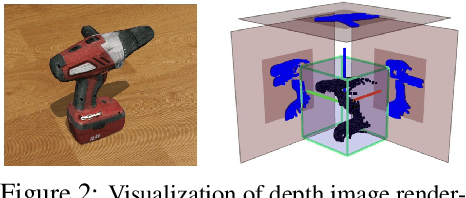
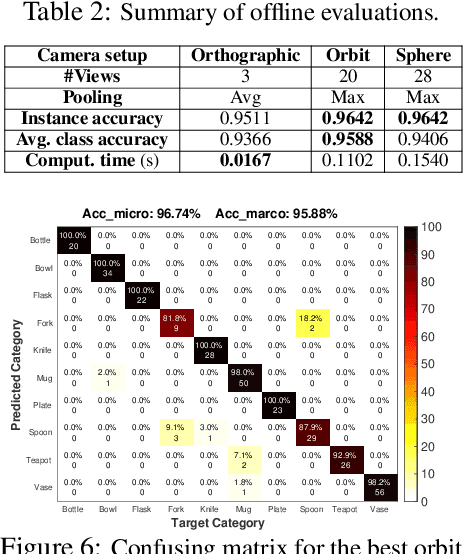
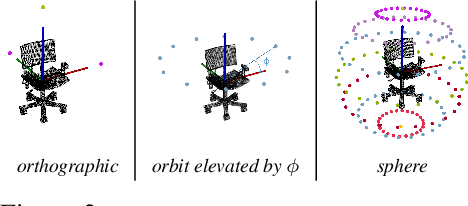
A robot working in human-centric environments needs to know which kind of objects exist in the scene, where they are, and how to grasp and manipulate various objects in different situations to help humans in everyday tasks. Therefore, object recognition and grasping are two key functionalities for such robots. Most state-of-the-art tackles object recognition and grasping as two separate problems while both use visual input. Furthermore, the knowledge of the robot is fixed after the training phase. In such cases, if the robot faces new object categories, it must retrain from scratch to incorporate new information without catastrophic interference. To address this problem, we propose a deep learning architecture with augmented memory capacities to handle open-ended object recognition and grasping simultaneously. In particular, our approach takes multi-views of an object as input and jointly estimates pixel-wise grasp configuration as well as a deep scale- and rotation-invariant representation as outputs. The obtained representation is then used for open-ended object recognition through a meta-active learning technique. We demonstrate the ability of our approach to grasp never-seen-before objects and to rapidly learn new object categories using very few examples on-site in both simulation and real-world settings.
Self-Imitation Learning by Planning
Mar 26, 2021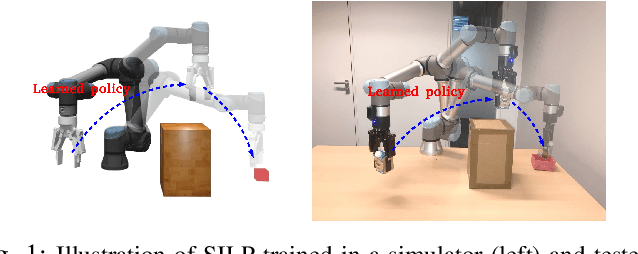
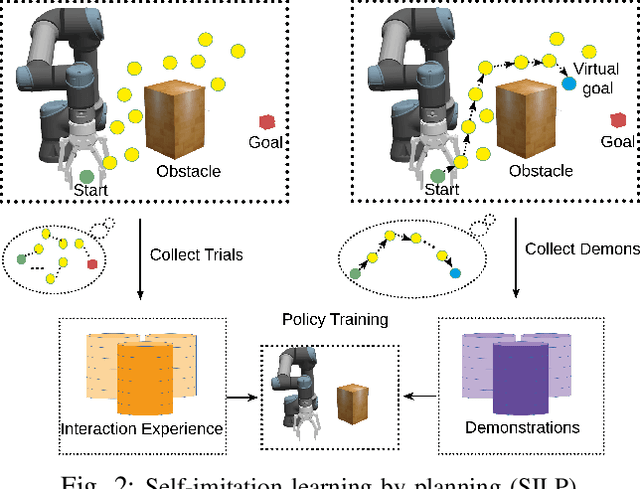
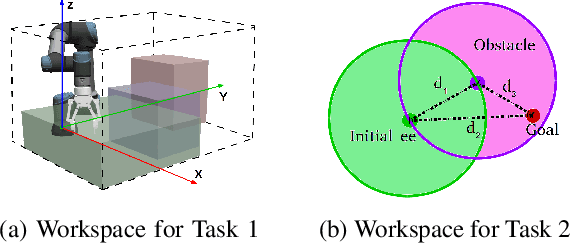
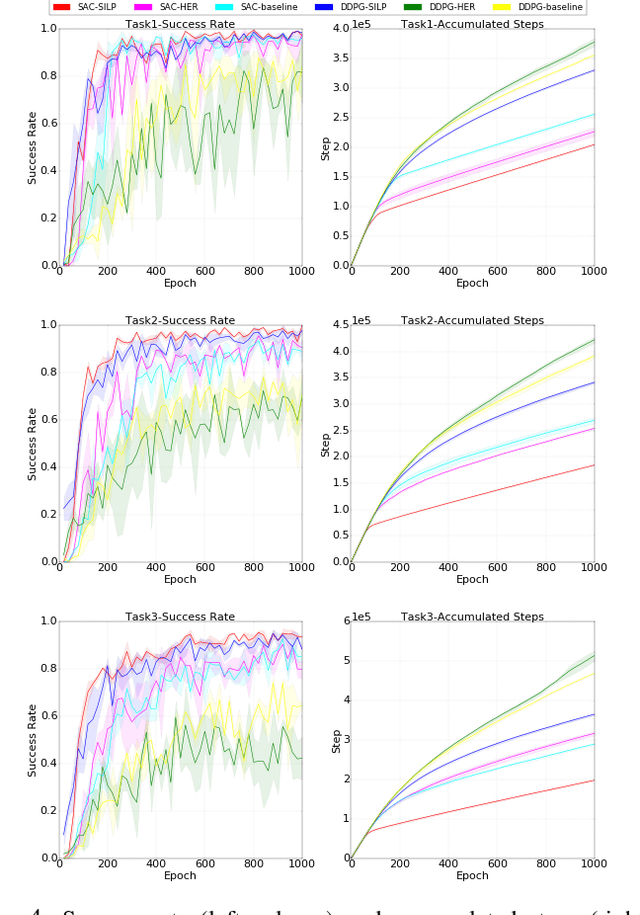
Imitation learning (IL) enables robots to acquire skills quickly by transferring expert knowledge, which is widely adopted in reinforcement learning (RL) to initialize exploration. However, in long-horizon motion planning tasks, a challenging problem in deploying IL and RL methods is how to generate and collect massive, broadly distributed data such that these methods can generalize effectively. In this work, we solve this problem using our proposed approach called {self-imitation learning by planning (SILP)}, where demonstration data are collected automatically by planning on the visited states from the current policy. SILP is inspired by the observation that successfully visited states in the early reinforcement learning stage are collision-free nodes in the graph-search based motion planner, so we can plan and relabel robot's own trials as demonstrations for policy learning. Due to these self-generated demonstrations, we relieve the human operator from the laborious data preparation process required by IL and RL methods in solving complex motion planning tasks. The evaluation results show that our SILP method achieves higher success rates and enhances sample efficiency compared to selected baselines, and the policy learned in simulation performs well in a real-world placement task with changing goals and obstacles.
Accelerating Reinforcement Learning for Reaching using Continuous Curriculum Learning
Feb 07, 2020



Reinforcement learning has shown great promise in the training of robot behavior due to the sequential decision making characteristics. However, the required enormous amount of interactive and informative training data provides the major stumbling block for progress. In this study, we focus on accelerating reinforcement learning (RL) training and improving the performance of multi-goal reaching tasks. Specifically, we propose a precision-based continuous curriculum learning (PCCL) method in which the requirements are gradually adjusted during the training process, instead of fixing the parameter in a static schedule. To this end, we explore various continuous curriculum strategies for controlling a training process. This approach is tested using a Universal Robot 5e in both simulation and real-world multi-goal reach experiments. Experimental results support the hypothesis that a static training schedule is suboptimal, and using an appropriate decay function for curriculum learning provides superior results in a faster way.
Distributed Circumnavigation Control with Dynamic Spacings for a Heterogeneous Multi-robot System
May 16, 2018

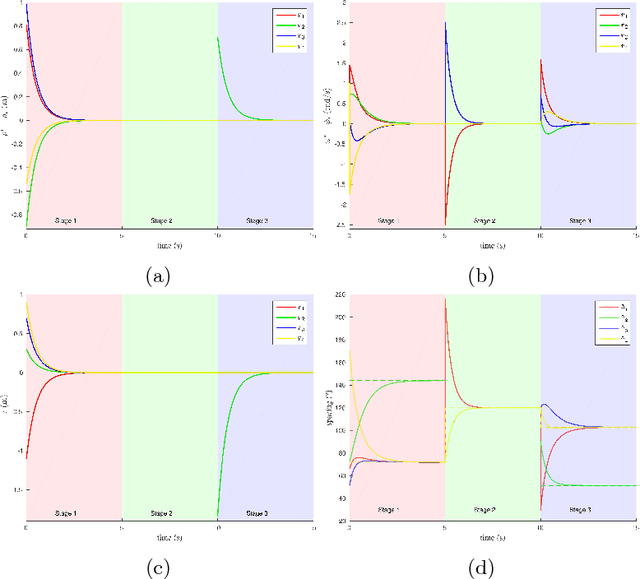

Circumnavigation control is useful in real-world applications such as entrapping a hostile target. In this paper, we consider a heterogeneous multi-robot system where robots have different physical properties, such as maximum movement speeds. Instead of equal-spacings, dynamic spacings according to robots' properties, which are termed utilities in this paper, will be more desirable in a scenario such as target entrapment. A distributed circumnavigation control algorithm based on utilities is proposed for any number of mobile robots from random 3D positions to circumnavigate a target. The dynamic spacings are subject to the variation of robots' utilities. The robots can only obtain the angular positions and utilities of their two neighbouring robots, so the control law is distributed. Theoretical analysis and experimental results are provided to prove the stability and effectiveness of the proposed control algorithm.